「Sidekiq のワーカーノードが稼働する EC2 インスタンスをオートスケールしたい」という依頼人の願いを、匠が叶えます。
このストーリーの登場人物は以下の2人です。
- 依頼人 = アプリケーションエンジニア or マネジメント層(適宜文脈によって読み替えてください)
- 匠 = インフラエンジニア
Before
まずは依頼人が抱えるお悩みについて話を聞いてみることにします。
インフラ構成
依頼人のサーバ構成は、 Sidekiq では標準的な構成を採用していました(図1, 2)。
Web ノードでタスクを Redis 登録し、 Worker ノードで Redis からタスクを取り出し実行します。
Web ノードは API として外部に公開されているほか、 Sidekiq の GUI として利用しています。
各ノードは AutoScalingGroup を構成していますが、台数固定で稼働しています。
図1. サービス構成:
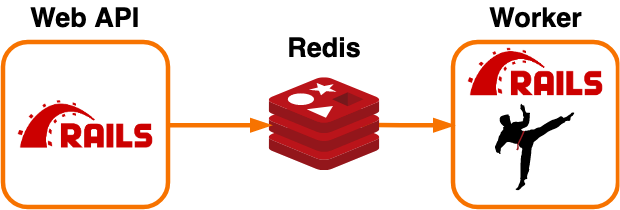
図2. AWS構成図:
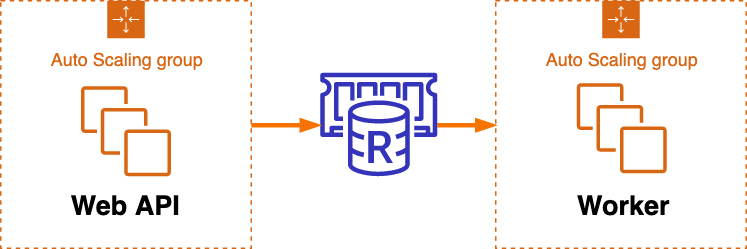
以下の文章では、便宜的に以下の用語を用います:
- マスターノード: タスクを登録するノード(Web API)
- ワーカーノード: タスクを実行するノード(Worker)
1. インスタンスの停止が困難
まず、匠が気になったのは、「インスタンスを固定台数で稼働している」ということでした。
依頼人は「インスタンスを簡単に落とせない」「スケールアウトは簡単にできるが、スケールインは面倒」といったことを口にしていました。
話を詳しく聞くと、 Sidekiq がタスクを処理中にインスタンスを停止すると、処理中のタスクがタスクの途中で異常終了するため、これを防ぐために、依頼人は以下のような手順でインスタンスを停止させていました。
- Sidekiq の GUI から、落としたいインスタンス上で稼働しているプロセスを選び、「一時停止」ボタンを押して Quiet状態にする
- プロセスが処理中のタスクが0になるのを待つ
- インスタンスを停止する
少ない台数で稼働している場合は大した問題になりませんでしたが、10台を超えるインスタンスを稼働していると、間違ったプロセスを終了させてしまうかもしれない、という危険性がありました。
とくに、依頼人はサーバの入れ替えに blue-green デプロイを採用しているため、入れ替え中は一時的に平常時の2倍のインスタンスが起動します。その中から旧運用系のインスタンスだけを選んで GUI 上から停止することは、大変神経を使う作業になっていました。
2. 手動でスケーリングする運用
インスタンスの停止の前に手動の作業を挟むために、依頼人はオートスケーリングを組むことができませんでした。
また、キャンペーン期間中など、普段よりも高負荷が想定される場合は、依頼人はあらかじめ多めにインスタンスをスケールアウトしておき、ピーク負荷が収まったタイミングで通常時のインスタンス数に手動でスケールインする必要がありました。
3. 負荷のピークに備えて、通常時も余分なインスタンスを待機させておく
依頼人のサービスの特性上、毎日深夜に負荷のピークが来ますが、依頼人が毎日手動でスケーリングするわけにもいかず、ピーク時の負荷に合わせたインスタンス数を確保しておく必要がありました。したがって、平常時は必要のない、余分なインスタンスを常に稼働させておく必要がありました。
依頼人は余計な出費をなるべく抑えたいとは思いつつ、サービスの安定稼働のためには仕方ない出費と考えて、しぶしぶ運用していました。
4. 勘と経験に基づいたキャパシティ計画
依頼人は、 Sidekiq の GUI から「再試行が増えている」「待機中のキューが数百件溜まっている」といったリアルタイムな状況は把握できますが、 GUI からは過去の時系列まではわからないため、「ピーク時の待機中のキューの長さはどれくらいか?」「平常時のBusyなスレッド数の割合はどのくらいか?」といった疑問にははっきりと答えることができませんでした。
このため、「ピーク時/平常時にどの程度のインスタンスが必要か?」「負荷のピークは何時から何時までか?」といったことが判断できないため、エビデンスに基づいて設計することができず、依頼人は勘と経験に基づいてキャパシティ計画するしかありませんでした。
改善方針
依頼人のお悩みに対して、匠は3つのステップで解決を図ることにしました。
1. アプリケーションの稼働状況の可視化する
改善の課題に取り組むときの最初のステップは、可視化です。
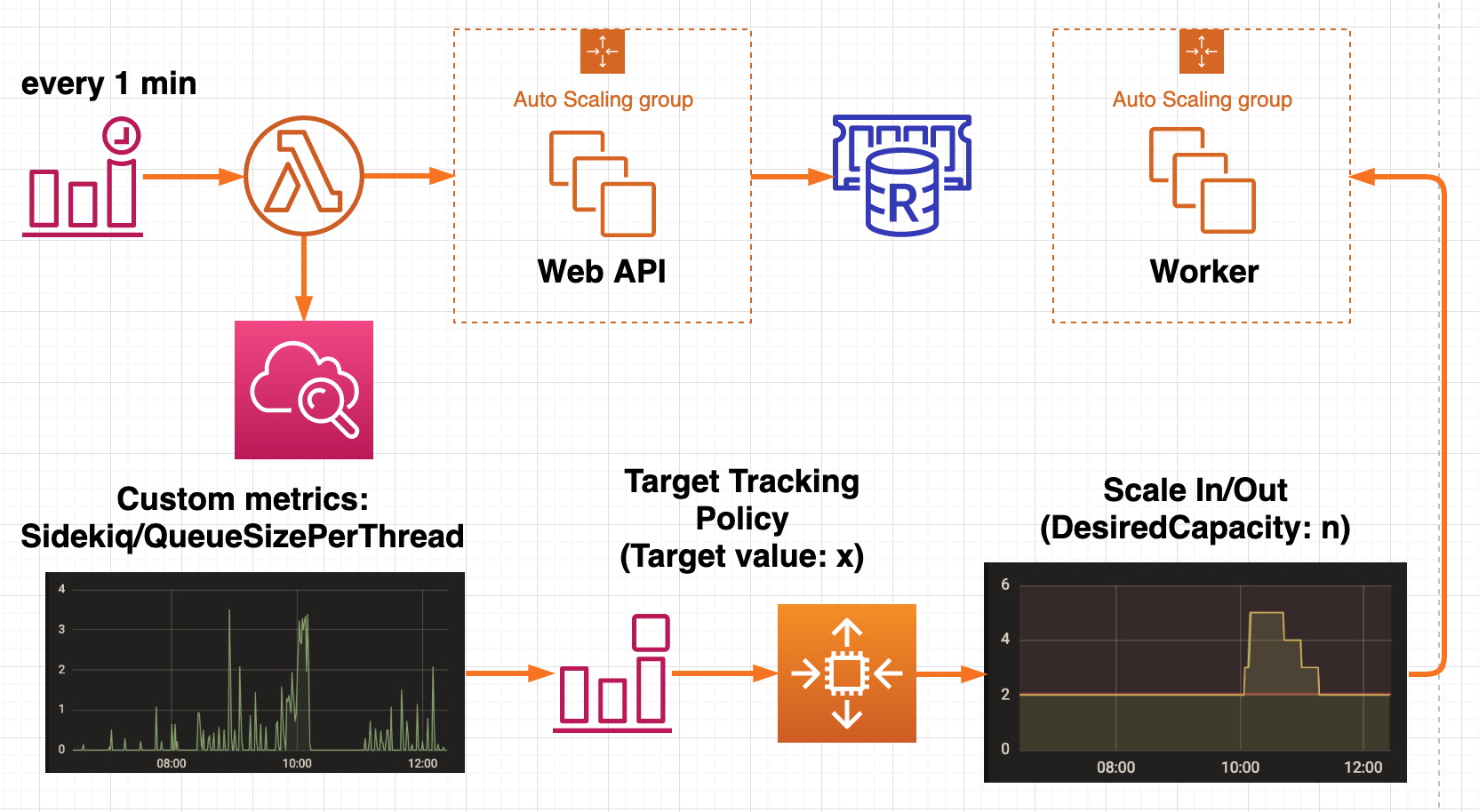
匠は CloudWatch から確認できる「CPU使用率」「メモリ使用率」といった一般的なOSリソースの利用状況のメトリクスに加えて、「待機中のキューの長さ」「キューに入ってから実際に処理されるまでの待ち時間」「Busyなスレッドの割合」といった、アプリケーションの稼働状況を表すメトリクスを取得することにしました。
OSリソースと同じように CloudWattch で確認(あるいは Grafana で可視化)できると便利と考えた匠は、これらのメトリクスをカスタムメトリクスとして公開することにしました。
Sidekiq のメトリクスを取得し、カスタムメトリクスを公開するには、以下のような方法があります:
- インスタンス内の cron ジョブでシェルスクリプトを起動する
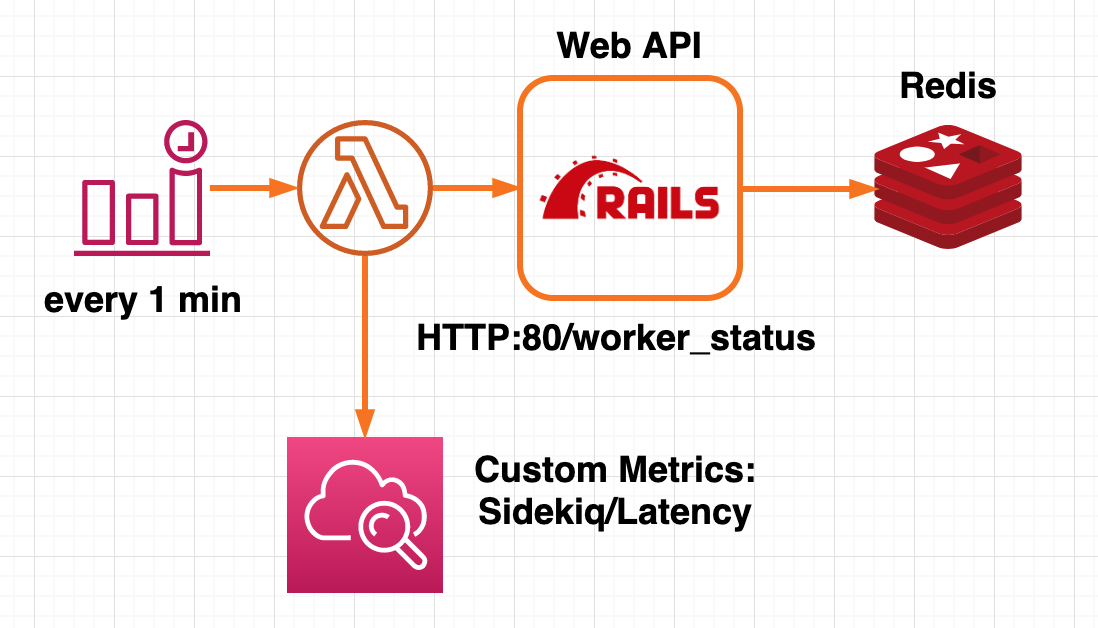
- Sidekiq のマスターノードにメトリクス監視用のエンドポイントを生やし、CloudWatch Event で 1分 ごとに Lambda Function を起動させ、 CloudWatch にメトリクスを送る
ワーカーノードが1台の場合は1のように、インスタンス内で完結して実装するのが簡単ですが、依頼人の構成のようにワーカーノードが複数台稼働している場や、ワーカーノードをオートスケーリングさせたい場合は、インスタンスの外部からメトリクスを取得するしくみが必要になります。
匠は以下のような方法でこれを解決しました。
- Web API ノードで Sidekiq のメトリクスを HTTP のエンドポイントとして外部に公開する(参考資料[4]参照)
- Cloudwatch Event で 1分ごとに Lambda Function を実行し、1 のエンドポイントから取得したメトリクスを、CloudWatch にカスタムメトリクスとして公開する
図3. Lambda Function を呼び出してアプリケーションのメトリクスを取得する
2. インスタンスのシャットダウンの前に Sidekiq をグレースフルシャットダウンする
次に匠が取り組んだのは、何も考えずにワーカーノードをシャットダウンできるようにすることでした。
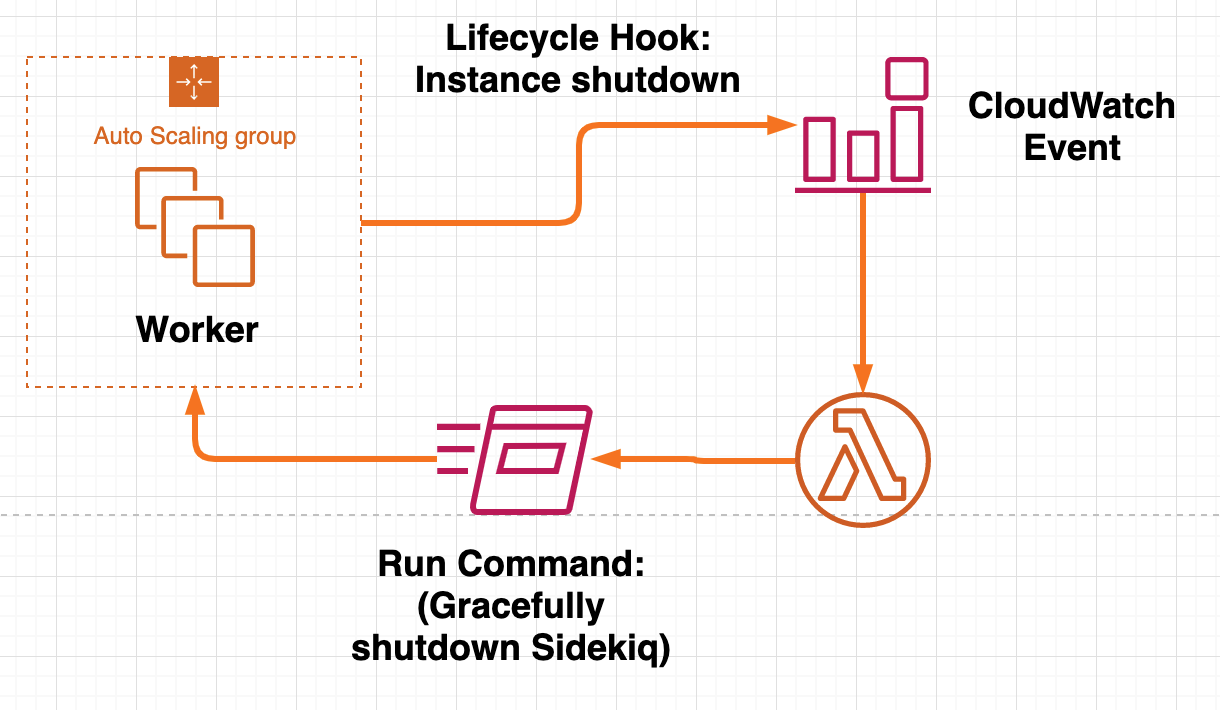
Auto Scaling Group に Lifecycle Hook を設定し、インスタンスのシャットダウンの直前に、Sidekiq をグレースフルにシャットダウンさせることにしました。
匠は、以下のようなピタゴラスイッチを構成することで実現しました(参考資料[3]参照)。
- Lifecycle Hook - Instance Shutdown
- Cloudwatch Event
- Lambda Function
- Systems Manager - Run Command
図4. ASG の Lifecycle Hook をトリガーにして Sidekiq をグレースフルにシャットダウンする
3. オートスケーリングポリシーを設定する
2まで実装できれば、何も恐れることなくオートスケーリングポリシーを設計することができます。
ここで匠の一工夫。
Sidekiq のワーカーノードをオートスケーリングする場合、ステップスケーリングポリシーを採用している記事をよく見かけますが、ターゲット値を「1インスタンスあたりのキュー長」にしてターゲットトラックングポリシーを採用することができます。
これはAWS公式ドキュメント[2]にも紹介されている方法です。
さらに、ターゲット値として「1スレッドあたりのキュー長」を採用すると、Sidekiq の同時実行数(concurrency)を変更した場合でも、ターゲット値の目標値を変更しなくて済みます。
ターゲットトラッキングポリシーのターゲット値は、1の方法と同じようにして、カスタムメトリクスとして公開します。
ターゲットトラッキングポリシーにすると、予め指定するパラメータが少なくてすむので設計が楽です。スケーリングの振る舞いに影響するのは、「ターゲット値の目標値」と「ウォームアップ期間」の2つだけだからです。
図5. Target Tracking Policy によるオートスケーリング
After
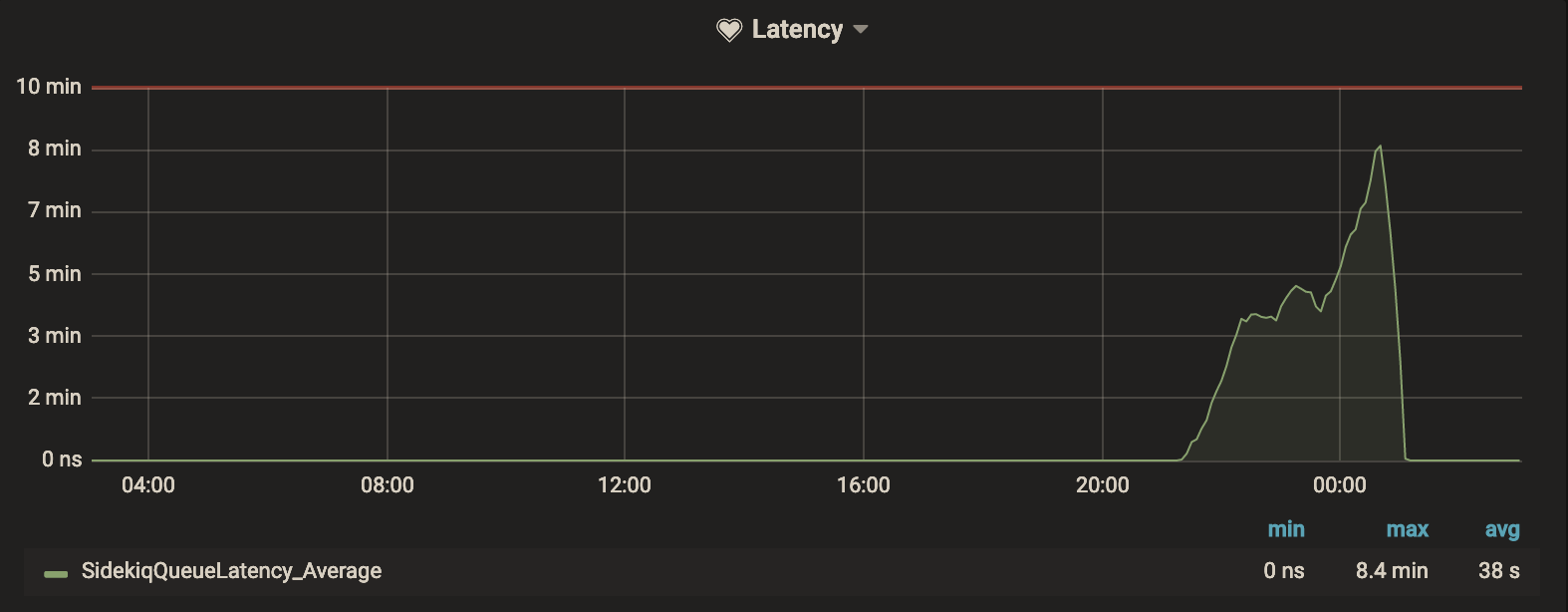
以前は必要もないのに、ピーク負荷に合わせて多めにインスタンスを起動していました。また、Sidekiq の稼働状況のメトリクスもなかったため、ピーク時は逆にキャパシティが足りず、最大で 8m 程度の遅延が生じていることがわかりました。
before - 8台で常時稼働:

一方、匠の手によって生まれ変わった構成では、負荷(ELB Request Count) に応じて最適なインスタンス数にスケールしているのがわかります。
after - 2-12台でオートスケーリング:

なお、匠はすぐに 2-12 台の範囲でスケールさせずに、最初は 4-8 台でスケールさせて様子をみることにしました。最大値と最小値の振れ幅を小さくしたことで、系が予期しない振る舞いをしたとしても、傷が浅くて済むからです。実際、最初にリリースしたときは Sidekiq のグレースフルシャットダウンの途中で失敗しているケースが数件あり、翌日切り戻しました。
最初は4-8台で様子を見ながら稼働させた:

1. エビデンスに基づいてチューニングできるように
それまでは「CPU使用率」「メモリ使用率」といったOSの基本的なメトリクスしか取得していなかったため、「平常時にどの程度リソースに余裕があるのか?」「ピーク時にリソースが足りているのか?」について、誰も説得力のある回答をすることができませんでした。
before:
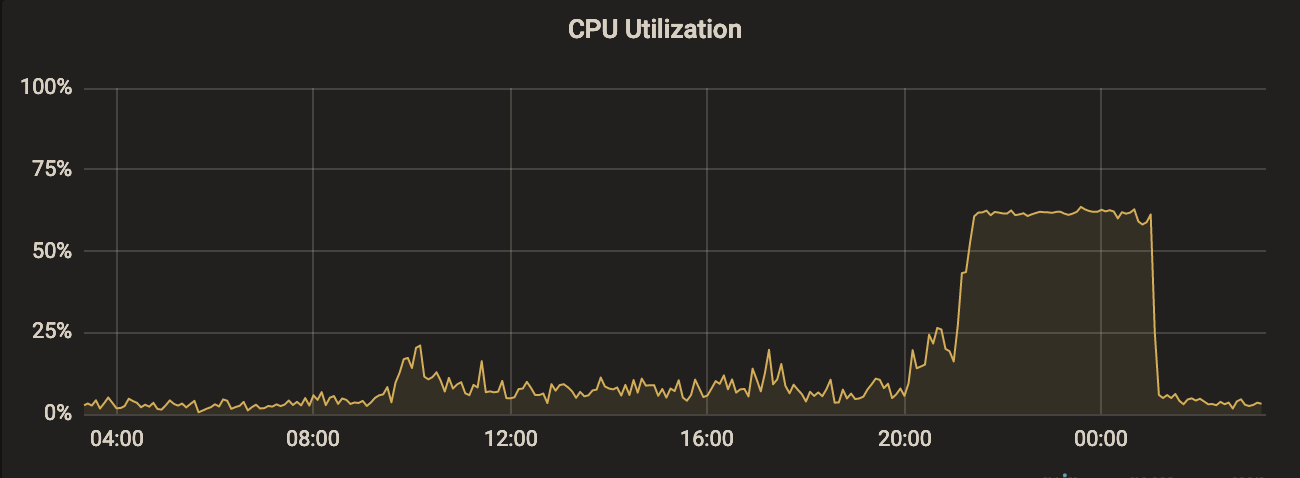
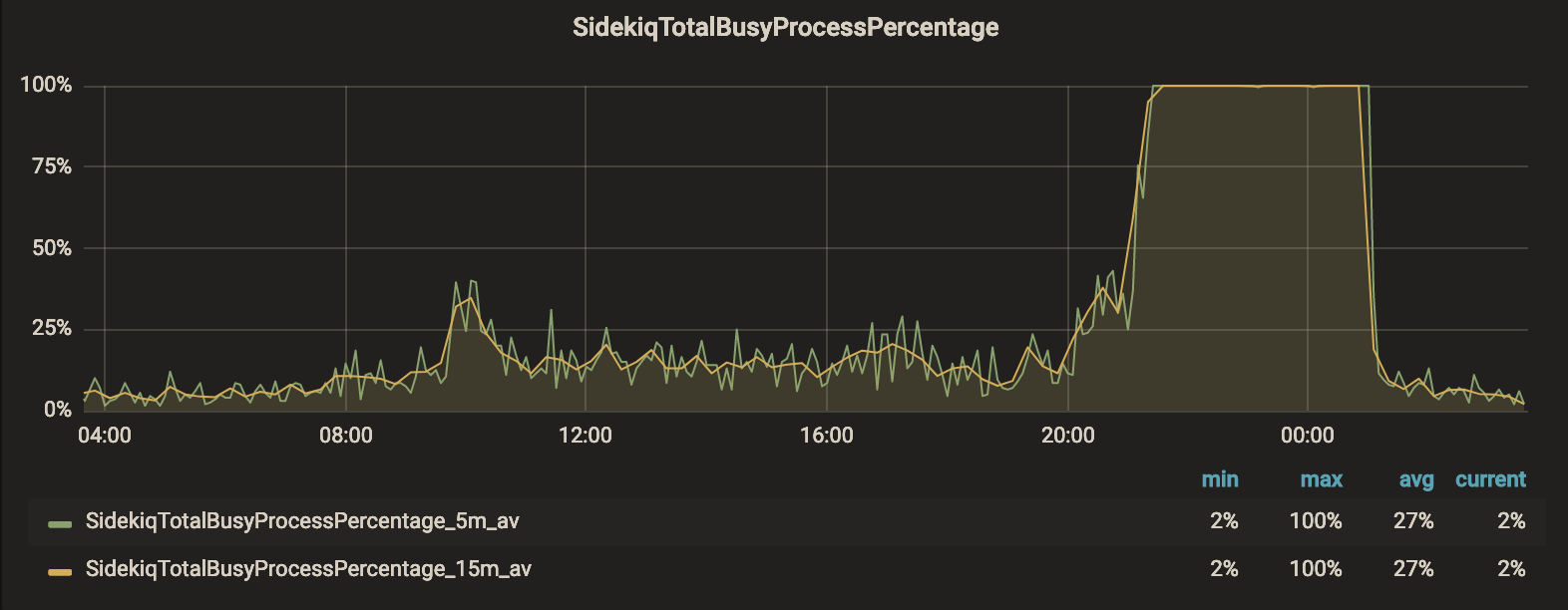
これに対し、匠は以下の3つのメトリクスを可視化しました。
- 1スレッドあたりのキュー長
- レイテンシー
- Busy なプロセスの割合
これにより、「ピーク時は何時から何時までか?」「平常時にどの程度リソースに余裕があるのか?」「ピーク時はどの程度レイテンシーが生じているのか?」といった疑問に対して、具体的な数値で答えられるようになりました。
その結果、依頼人は勘と経験ではなく、客観的なエビデンスに基づいてキャパシティプランニングやチューニングができるようになりました。
after:
2. インスタンスの停止が簡単に
Lifecycle Hook によって、インスタンスの停止前に自動的に Sidekiq をグレースフルシャットダウンしてくれるので、処理中のタスクが失われるリスクがなくなりました。
このため、依頼人は ASG の要求数を変えるだけでスケールイン、スケールアウトを自由にできるようになりました。
また、 Sidekiq の GUI からおっかなびっくりプロセスを停止する必要がなくなり、間違ったプロセスを停止してしまうリスクもなくなりました。
3. 手動のスケーリング運用が不要に
ピーク負荷が予想される、キャンペーンの直前/直後にエンジニアが手動でスケールアウト、スケールインする必要がなくなりました。これによって、単純作業が何よりも嫌いな依頼人は、よりクリエイティブなことに時間を使うことができるようになりました。
4. インスタンスの稼働費用を60%削減
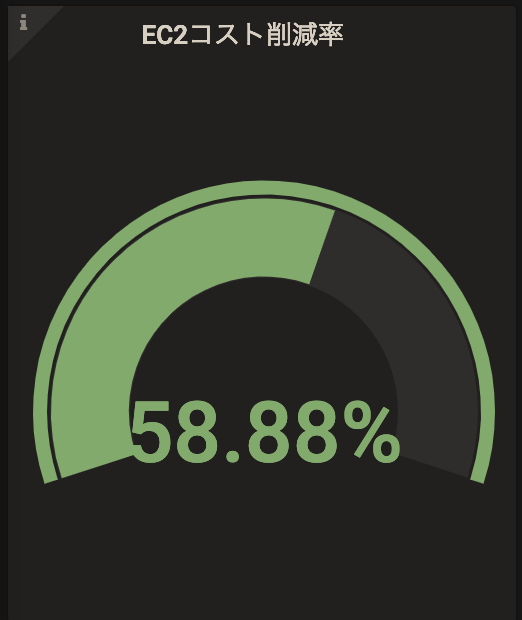
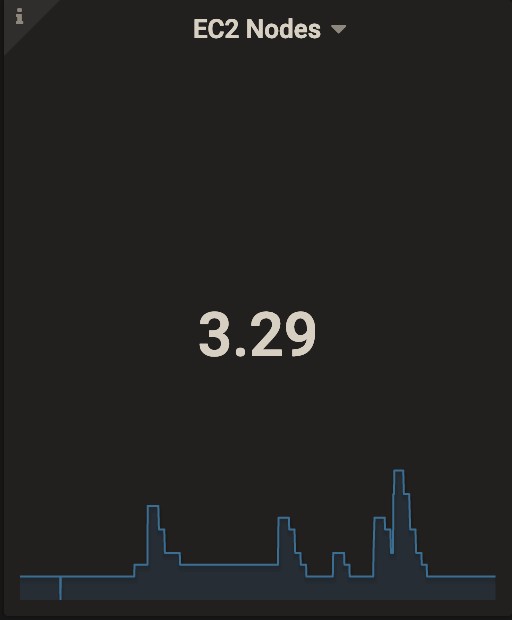
匠の業により、負荷に合わせて動的にスケーリングしてくれるようになったので、平常時は少ないインスタンス数で稼働でき、インスタンスの稼働費用が抑えられるようになりました。
どのくらい削減できるかは、サービスの負荷の特性によりますが、このサービスの場合では、常時8台稼働していたものが平均で3.29台の稼働ですむようになり、60%近くEC2の稼働費用を削減することができました。これには依頼人にも思わず笑みがこぼれます。
終わりに
Sidekiq の Worker Node をオートスケールさせるまでの工数を考えると、それなりにしきいが高いですが、少しづつ改善していくだけでも効果は得られるので、まずは可視化あたりから始めてみてはいかがでしょうか。