はじめに
キュー内のメッセージ数に応じて Sidekiq を実行する EC2 インスタンスをスケールする方法を紹介します。
といっても、基本的なスケーリングポリシーの設計は参考資料[1]に書いてあることほぼそのままです。
参考資料では SQS を例に書いてますが、一般的な非同期メッセージングサービスであれば同様の考え方でスケーリングポリシーを設計することができます。
準備
Sidekiq のプロセスを実行するEC2インスタンスをオートスケールするにあたって、いくつか準備することがあります。
- スケールインのときに Sidekiq をグレースフルシャットダウンさせる
- Sidekiq のメトリクスを監視する
スケールインのときに Sidekiq をグレースフルシャットダウンさせる
Sidekiq がジョブの実行中にシャットダウンしてしまわないようにするために、インスタンス停止時のライフサイクルフックをトリガーにして、Sidekiq のプロセスをグレースフルにシャットダウンさせます。
詳細な設定方法は参考資料[3]に譲ります。
Sidekiq をメトリクス監視する
Sidekiq の稼働中の状態を正確に知るために、基本的なメトリクスを観測できるようにします。
後に出てくるシステムのパラメータを決定する上でも役立ちます。
参考資料[4]に詳細な手順が紹介されています。
メトリクスの例
- キュー長
- キューに登録されてから、Sidekiq で処理されるまでの最大待ち時間
- Busy なプロセスの数
スケーリングポリシーの設計
参考資料[2]によると、ターゲット追跡に使用できるメトリクスには以下の制約があります:
すべてのメトリクスがターゲット追跡に使用できるわけではありません。これは、カスタマイズされたメトリクスを指定する場合に重要になる場合があります。メトリクスは有効な使用率メトリクスであり、インスタンスの使用頻度を指定する必要があります。メトリクス値は Auto Scaling グループのインスタンス数に比例して増減する必要があります。それにより、メトリクスデータを使用して比例的にインスタンス数をスケールアウトまたはスケールインできます。
例えば、以下のようなものです。
- AutoScaling Group あたりのCPU使用率の平均値
- 稼働中のプロセス数の合計
キューイングシステムの場合は以下が候補になります(参考資料[1]参照)。
- 1インスタンス(or 1プロセス)あたりのキュー長
共通しているのは、 システムの負荷が同じ場合、インスタンス数に反比例して増減する量であるということです。
つまり、インスタンス数を$I$、ターゲット追跡対象のメトリクスを$M_T$とすると、以下の式で表せます:
$$M_T\propto I^{-1}$$
例として、$M_T$が「CPU使用率の平均値」の場合、各インスタンスのCPU使用率を$c_i$とすると、 $IM_T=\sum{c_i}=\text{const.}$と表せるので、たしかに反比例の関係にあります。
また、$M_T$が「1インスタンスあたりのキュー長」の場合、キュー長を$N$とすると、$IM_T=N=\text{const.}$と書け、やはり反比例の関係にあります。
システム全体で処理する負荷を表す量として、Webサービスでは「インスタンスのCPU使用率の平均値」を採用するのに対して、キューイングシステムでは「キュー長」を採用していることになります。
1. システムのパラメータの設計
参考資料[1]にしたがって、以下のパラメータを決定します。
- 1インスタンスあたりの許容できるキューの長さ: $N_I^{\ast}$
- 1メッセージあたりの許容できる最大遅延時間: $L^{\ast}$
- 1インスタンスあたりのメッセージ処理時間: $T_I$
例として、 $T_I=4.48\text{s}, L^{*}=60\text{s}$ とすると、$N_I^{\ast}=L^{\ast}/T_I=13.39$ と計算できます。
$L^{\ast}$はサービスの要件から決めることができますが、$T_L$は不明なので、システムのメトリクスの観測値などから推定する必要があります。
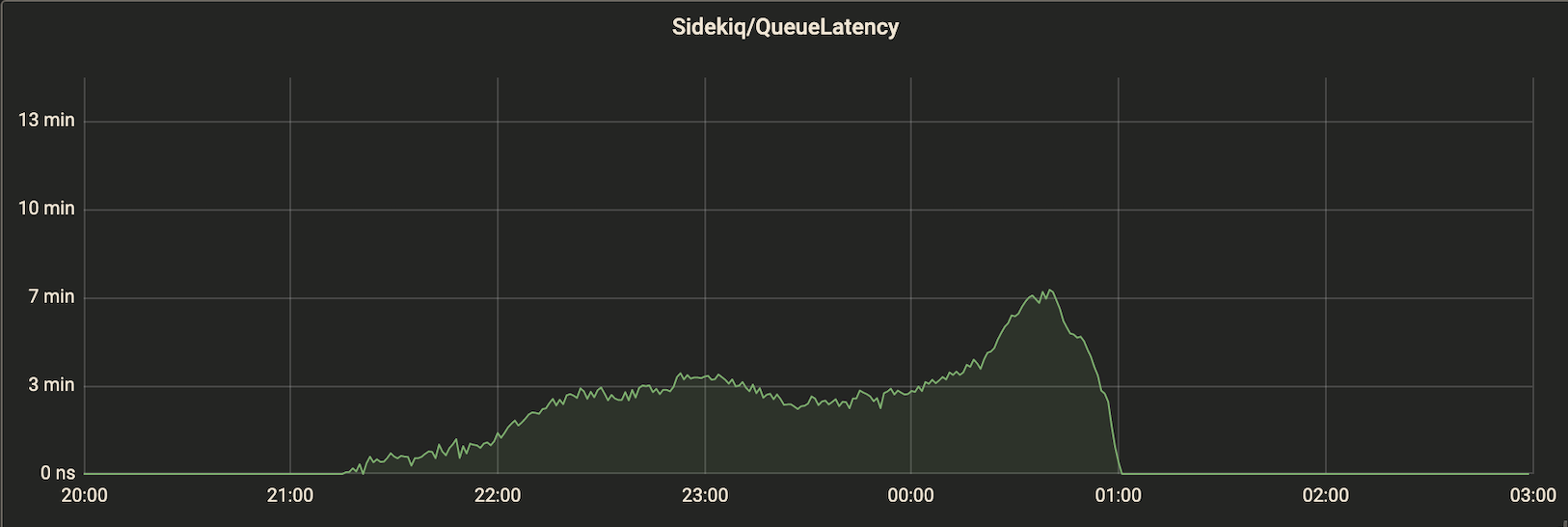
キューのサイズとレイテンシーの関係がわかっていれば、$T_I$を推定できます。例えば、図1,2 のようなグラフが得られているとします。常時 8 インスタンス稼働しているとすると、ピーク時の1インスタンスあたりのキュー長が 750/8=93.75 に対してレイテンシーが 7 min なので、$T_I\approx7*60/93.75=4.48\text{s}$ くらいだとわかります。
図1. キューの長さ
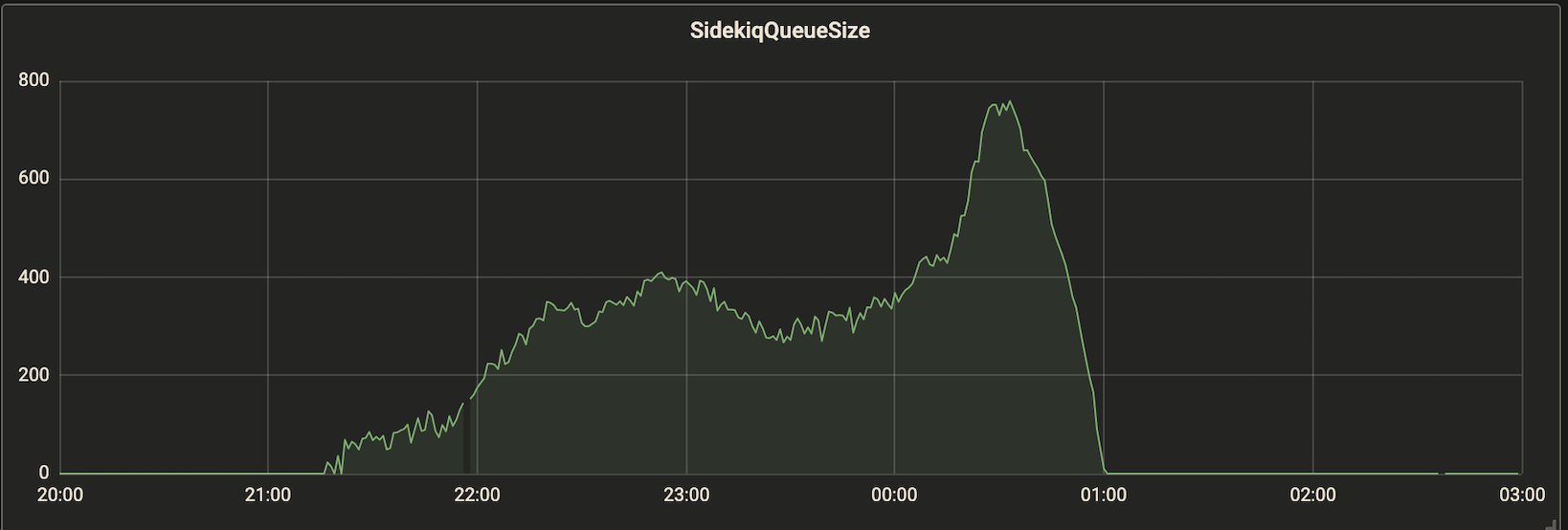
図2. レイテンシー
今回の例では $M_T^{\ast}=N_I^{\ast}=10$とします。
なお、$M_T^{\ast}$ はターゲット追跡ポリシーにおける、メトリクスの目標値です。
2. ターゲット追跡ポリシーに指定するカスタムメトリクスを生成する
1インスタンスあたりのキュー長をカスタムメトリクスとして観測する必要があります。
キュー長を$N$, インスタンス数を$I$とすると、$N_I=N/I$ を計算してカスタムメトリクスとして発行します。
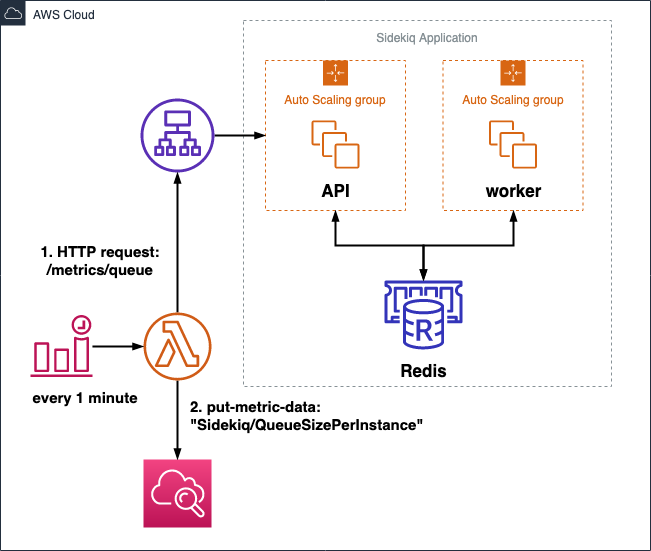
例えば、図3のように、1分ごとにCloudWatch Event を生成し、 Lambda Function でメトリクスを発行します。メトリクス名は QueueSizePerInstance とします。
図3. ターゲットメトリクスを発行するための構成例
3. ターゲット追跡ポリシーの作成
あとは、2で設定したカスタムメトリクスをもとにターゲット追跡ポリシーを作成するだけです。
詳細は参考資料[1]に譲るとして、ターゲット追跡ポリシーの設定は以下のようにします。
{
"TargetValue":10.0,
"CustomizedMetricSpecification":{
"MetricName":"QueueSizePerInstance",
"Namespace":"Sidekiq",
"Dimensions":[
{
"Name":"Stage",
"Value":"prd"
}
],
"Statistic":"Average",
"Unit":"Count"
}
}
まとめ
- Webサービスだけでなく、キューイングシステムのようなワークロードの場合でもターゲット追跡ポリシーを指定することができる
- SQSだけでなく、Sidekiqの場合も考え方は同じ(ただし、安全にスケールするための準備が必要)