こんにちは!
私は インメモリカラムナーデータ処理技術に興味を持ち 個人的に OSSの Apache Arrow、Apache DataFusion、Polars の調査とアプリ開発を行っています。開発言語はPythonで、パソコンで扱える程度のビッグデータ(容量は1TB未満)の処理スピード(性能)の評価も行っています。
そんな中 ノーコードでビッグデータハンドリングアプリが開発できる 「ESPERiC」と呼ぶツール があったので試してみました。
ESPERiCは 独自のインメモリカラムナー技術を採用したデータ処理エンジンとAPI およびGUIから構成されており、GUIでの操作からPythonアプリが自動的に生成される仕組みとなっています。扱えるデータサイズは パソコンの搭載メモリに入り切る大きさです。
※ 本稿の データハンドリング等は MacBook Pro メモリ 32GB を使用しています。
データの準備
今回 下記のデータ(ファイル)を準備しました。
NYC_YellowTaxi_TripData.csv
TLC(The New York City Taxi and Limousine Commission)の Yellow Taxi 乗客データの2020年1月から2024年6月までを1つのファイルにまとめました。ビッグデータにするため あえて データを集めて1つにしました。
データの中身(項目内容)は ここ(Data Dictionary – Yellow Taxi Trip Records)を参照ください。
データプロファイリング
データハンドリングの前に Zarque-profiling1 (https://github.com/crescendo-medix/zarque-profiling) を使って NYC_YellowTaxi_Trip データのプロファイリングを行ってみました。約1億5千万行 19列のデータプロファイリングが 約4分で 終わりました。データの概要、データ品質アラート、列毎の ユニーク値、欠損値、無限値、最大値、最小値、平均値、中央値、標準偏差、重複レコード などのレポートが作成されます。
・Overview ... 行数 153,851,817 列数 19
・Alerts ... 警告数 22 (欠損値や0値がある、距離や金額データに 偏りが大きいものがある)
・Variables ... total amount(合計金額)の 0値やマイナス値が気になる
 
|
 |
ちなみに Pandas-profilingは 20分ぐらい経ってもプロファイリングが終了しないので 強制終了させました。メモリプレッシャーが高かったのでメモリ不足の可能性があります。
データハンドリング
今回は イエロータクシーの運行データ(NYC_YellowTaxi_TripData)項目のうち お客の 乗車地点(PULocationID)と 降車地点(DOLocationID)をもとに 賃走回数の多いルートを集計し トップ10を抽出します。つまり お客が 「どこで乗車して」「 どこで降車する」のが多いかを調べ 多い順に先頭から10ルート抽出します。また、乗車地点と降車地点を わかりやすい「地名」に変換して表示します。
ESPERiC GUIで 下記のように操作します。
1.ESPERiC 起動
ESPERiC を立ち上げ2て、メニュー [ファイル] [インポート] で myDataStore を開きます。
myDataStore フォルダー には データハンドリングで使用するファイルを格納しておきます。
2.データインポート
myDataStore 中の CSVファイルをクリックすると インポートウイザードが立ち上がります。
項目名とデータタイプを設定してインポートを実行します。インポート処理は データ行数と列数に比例して 時間が掛かります。
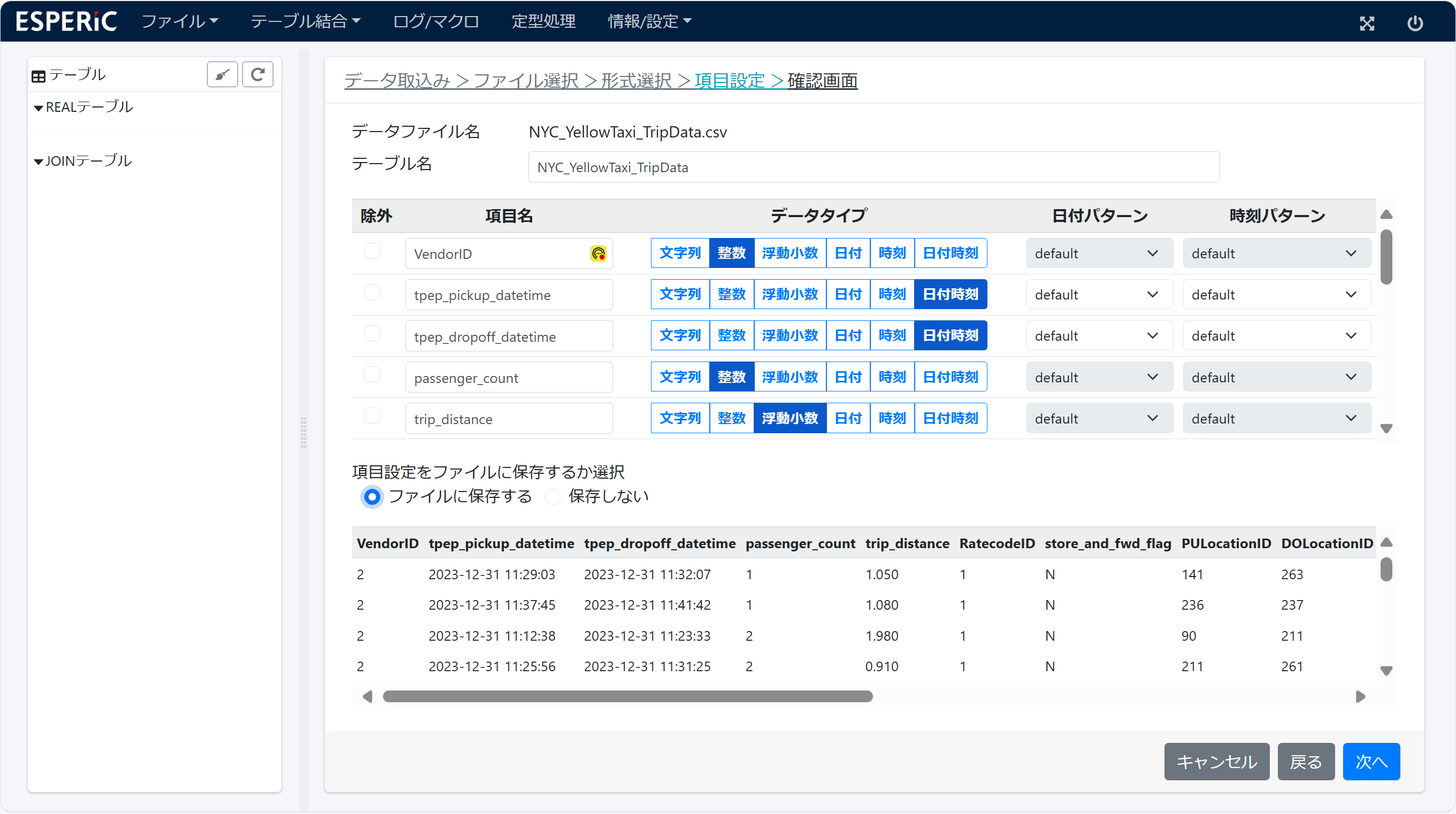
NYC_YellowTaxi_TripData をインポートします。インポートが完了すると 3. テーブル に示す テーブル NYC_YellowTaxi_TripData が表示されます。
同様に TaxiZone_Lookup もインポートします。TaxiZone_Lookup は 地点IDと地名 の対応テーブルです。
3.テーブル
インポートしたデータがグリッド形式で表示されます。 データハンドリングは この画面で行います。
テーブルには REALテーブル3 と JOINテーブル4の2種類があります。
4.抽出
データプロファイリングで total amount に 0値やマイナス値があるのが分かったので 0 より大きい値の行を抽出します。
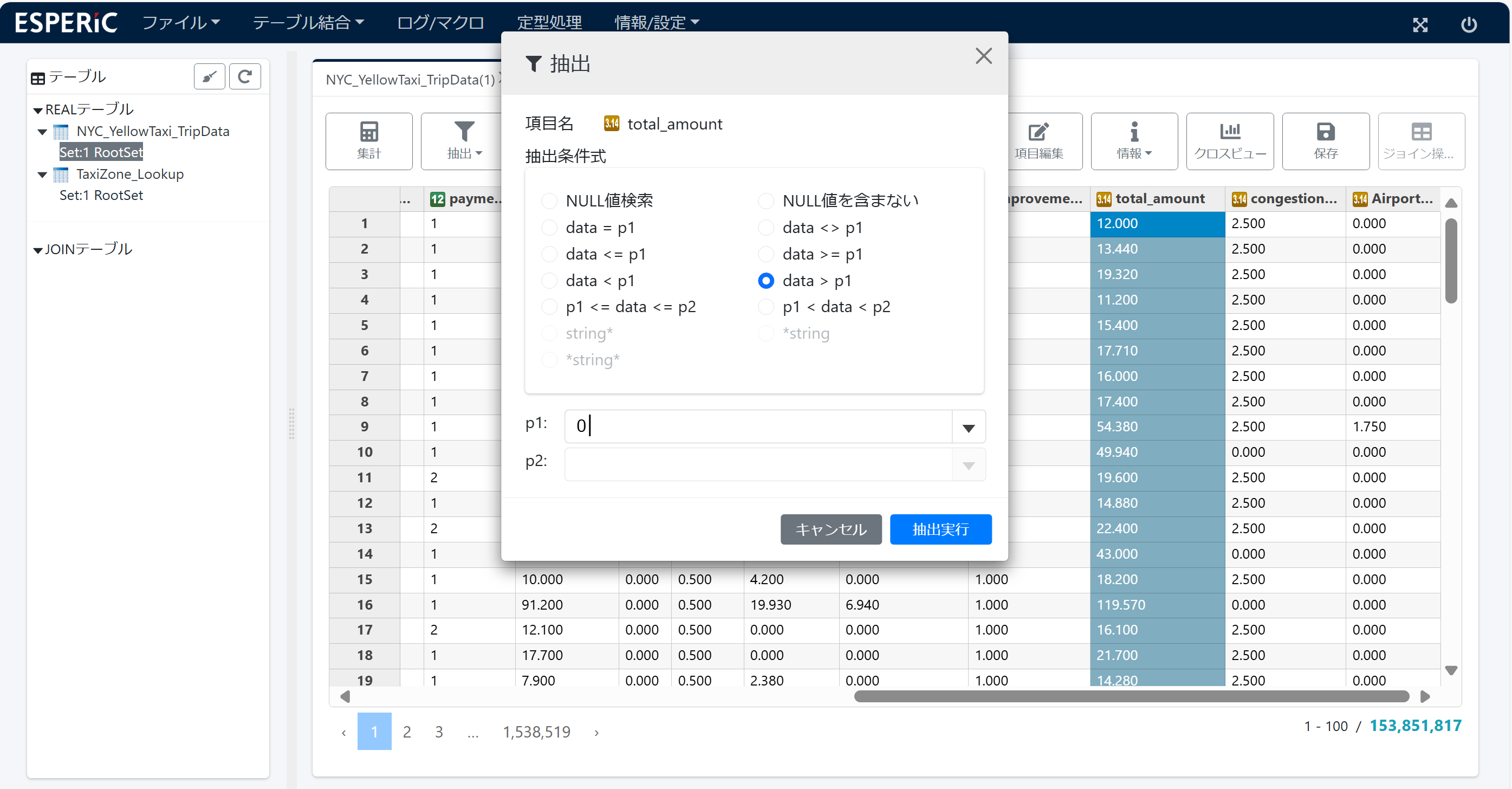
値を抽出したテーブル( Set:2 Search Set:1 [total_amount] > 0 5)が表示されます。画面は 5. 集計 を参照
5.集計
テーブル(Set:2)の PULocationID(乗車地点)と DOLocationID(降車地点)の組み合わせで 件数 を集計します。どこで乗車して どこで降車したか 毎の件数です。
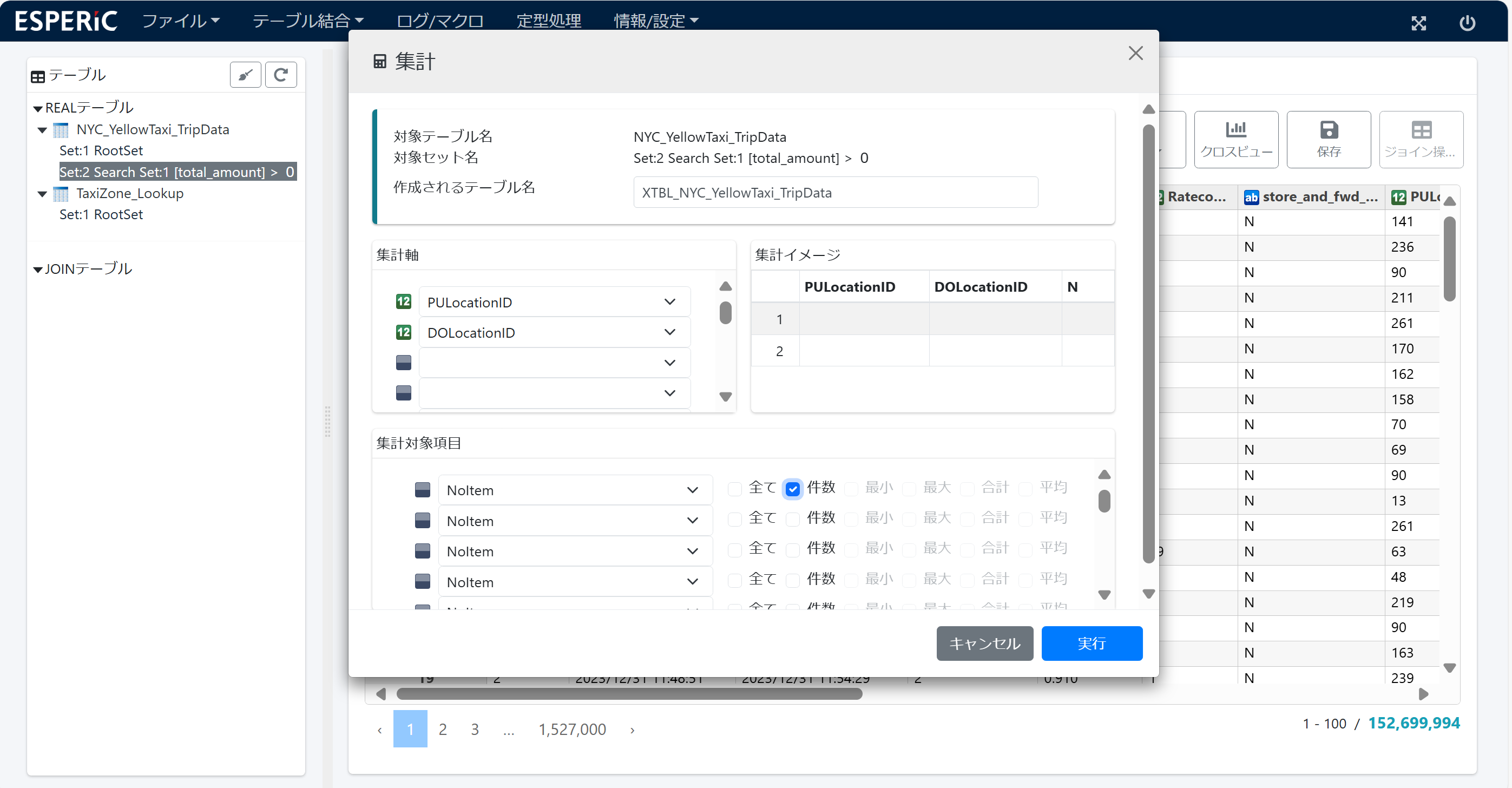
集計テーブル XTBL_NYC_YellowTaxi_TripData が作成されます。画面は 6. ソート を参照
6.ソート
集計テーブルの項目名 N を 回数 に変更し、回数を降順ソートします。
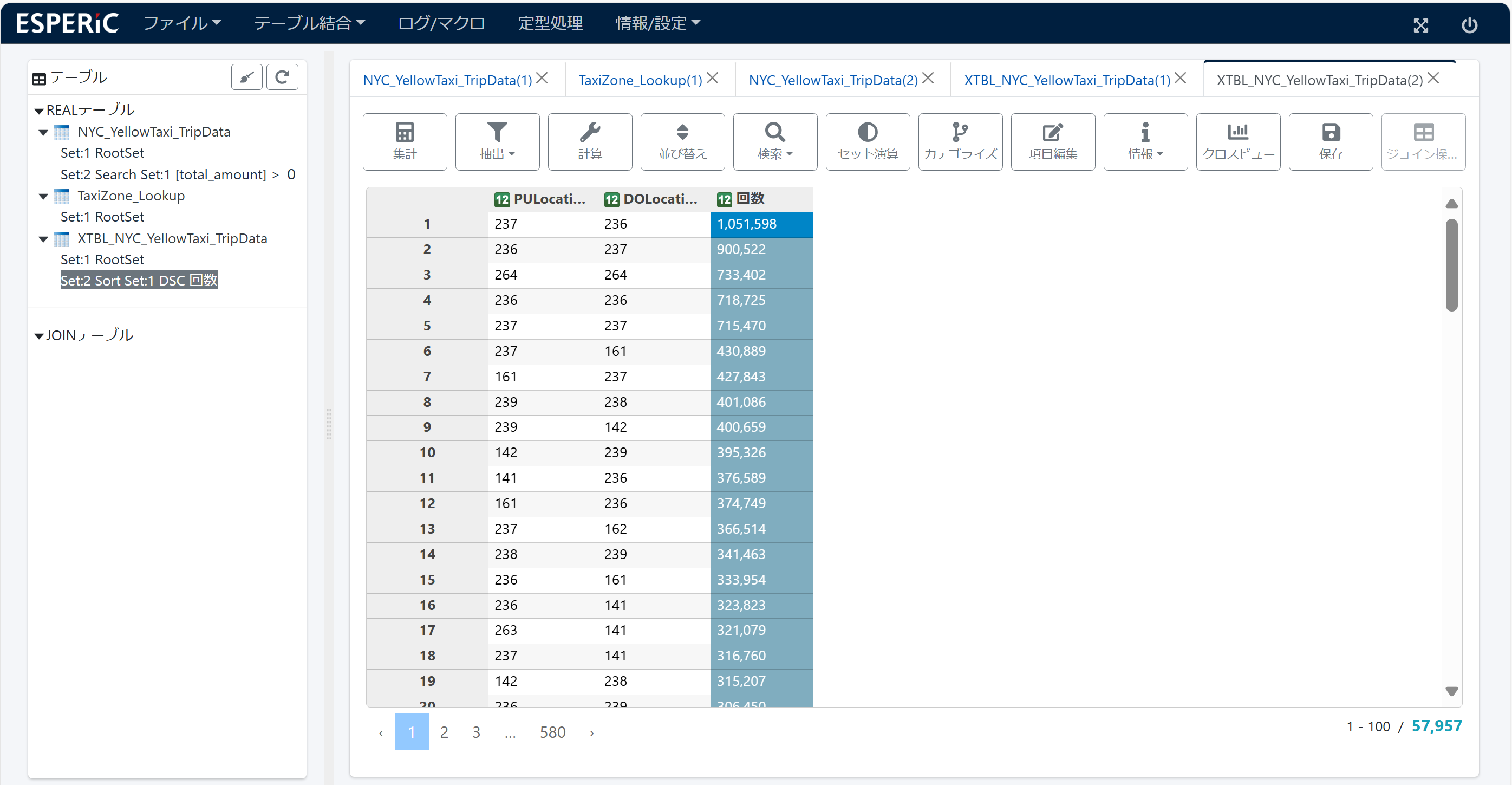
集計テーブルが回数の多い順に並びました。
7.ジョイン
PULocationID(乗車地点)と DOLocationID(降車地点)は「ID」なので TaxiZone_Lookup とジョインして「地名」を追加します。
スタージョインになりますが、ESPERiC のジョインは 2つのRealテーブル同士しか指定できないので、この操作は 少しめんどうです。
(1)1回目のジョイン... 集計テーブルの PULocationID と TaxiZone_Lookupテーブルの LocationID をキーにしてジョインします。
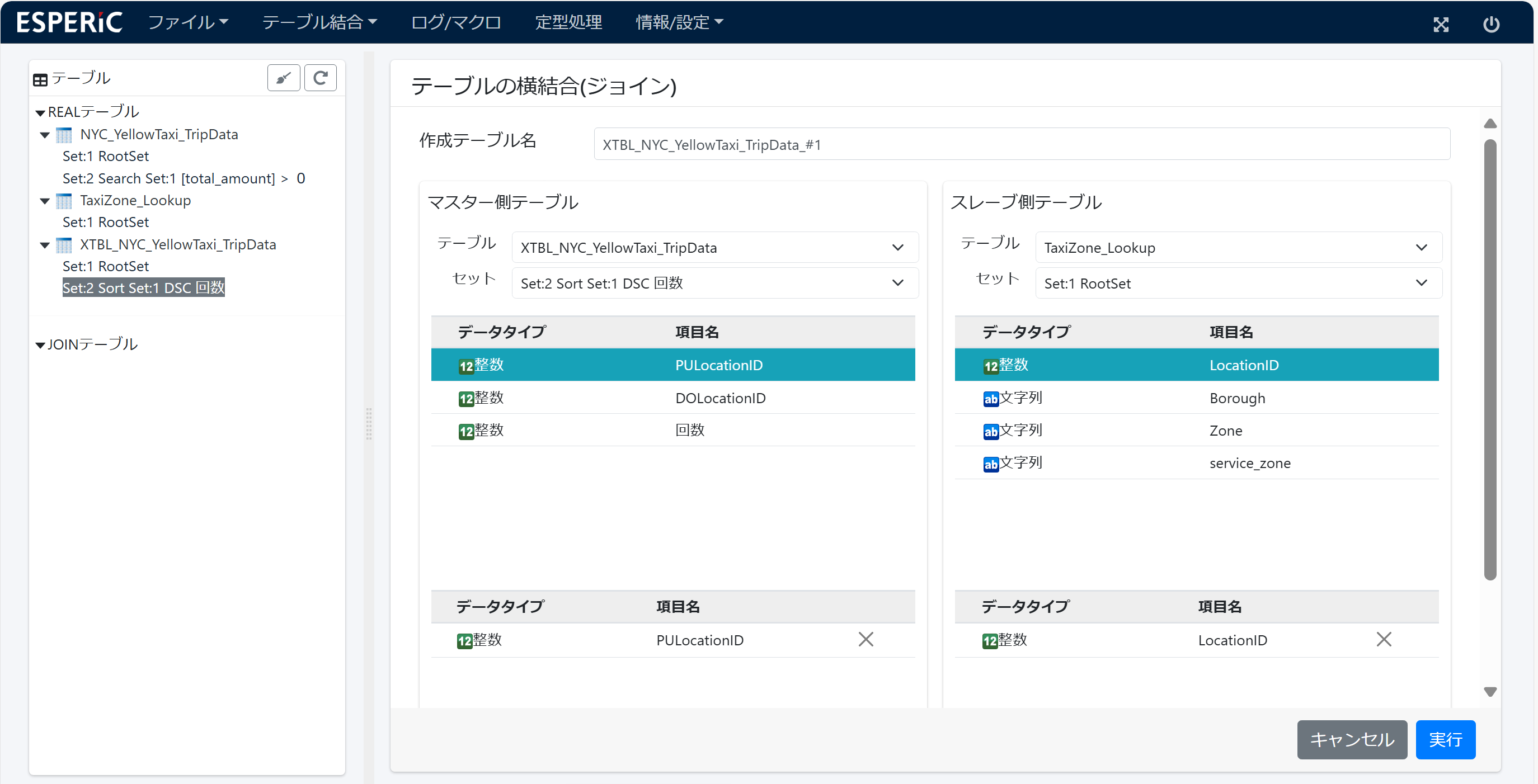
乗車地名(BoroughとZone)が追加された ジョインテーブルが作成されます。
(2)1回目の項目転送... ジョインテーブルの 項目 BoroughとZone を項目転送6します。集計テーブルに 乗車地名(BoroughとZone)が追加されます。
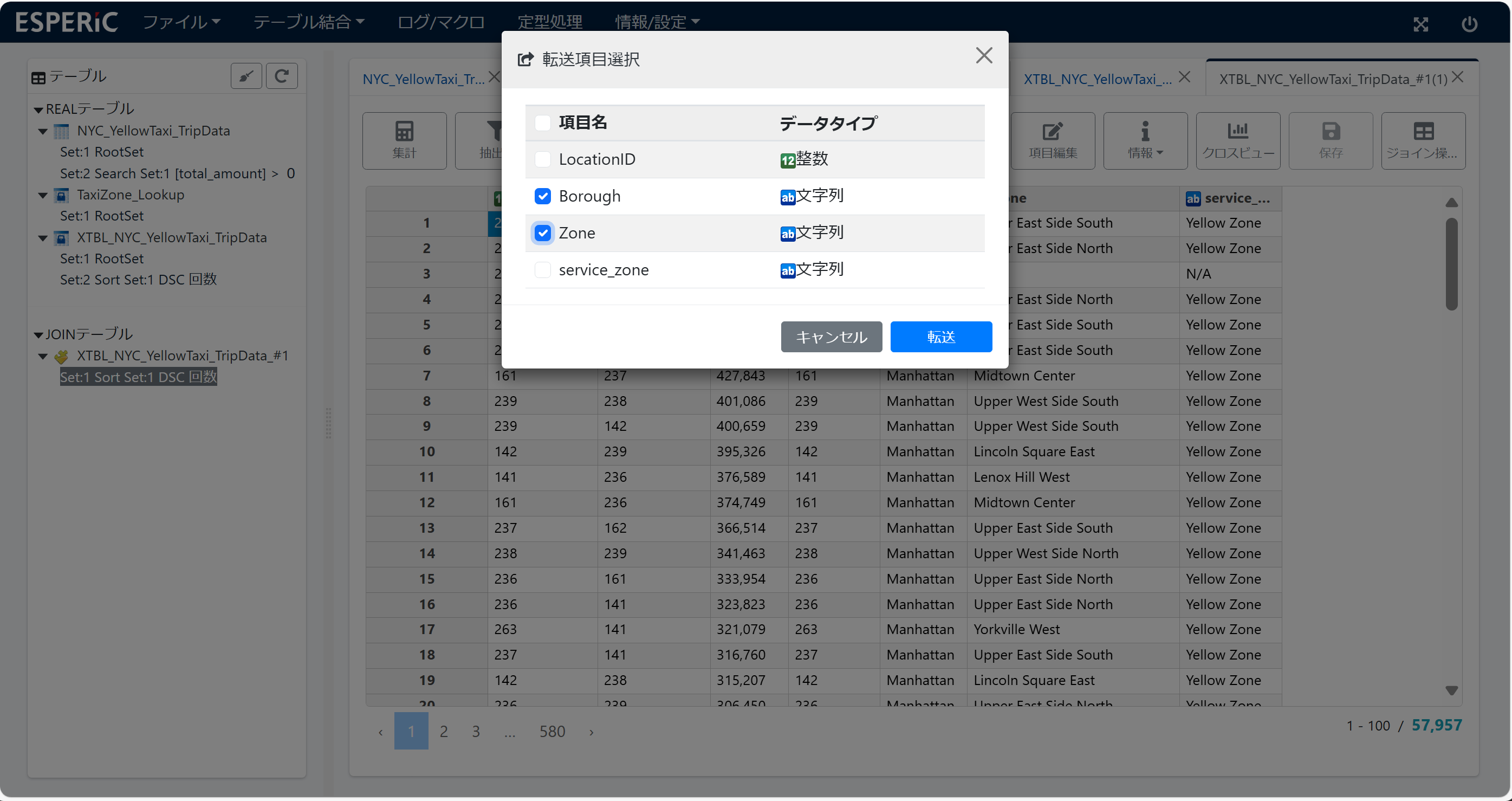
(3)ジョインテーブルは 不要になったので 削除します。
(4)集計テーブルの項目名 BoroughとZone を 乗車地名と乗車ゾーン に変更します。
(5)2回目のジョイン... 集計テーブルの DOLocationID と TaxiZone_Lookupテーブルの LocationID をキーにしてジョインします。
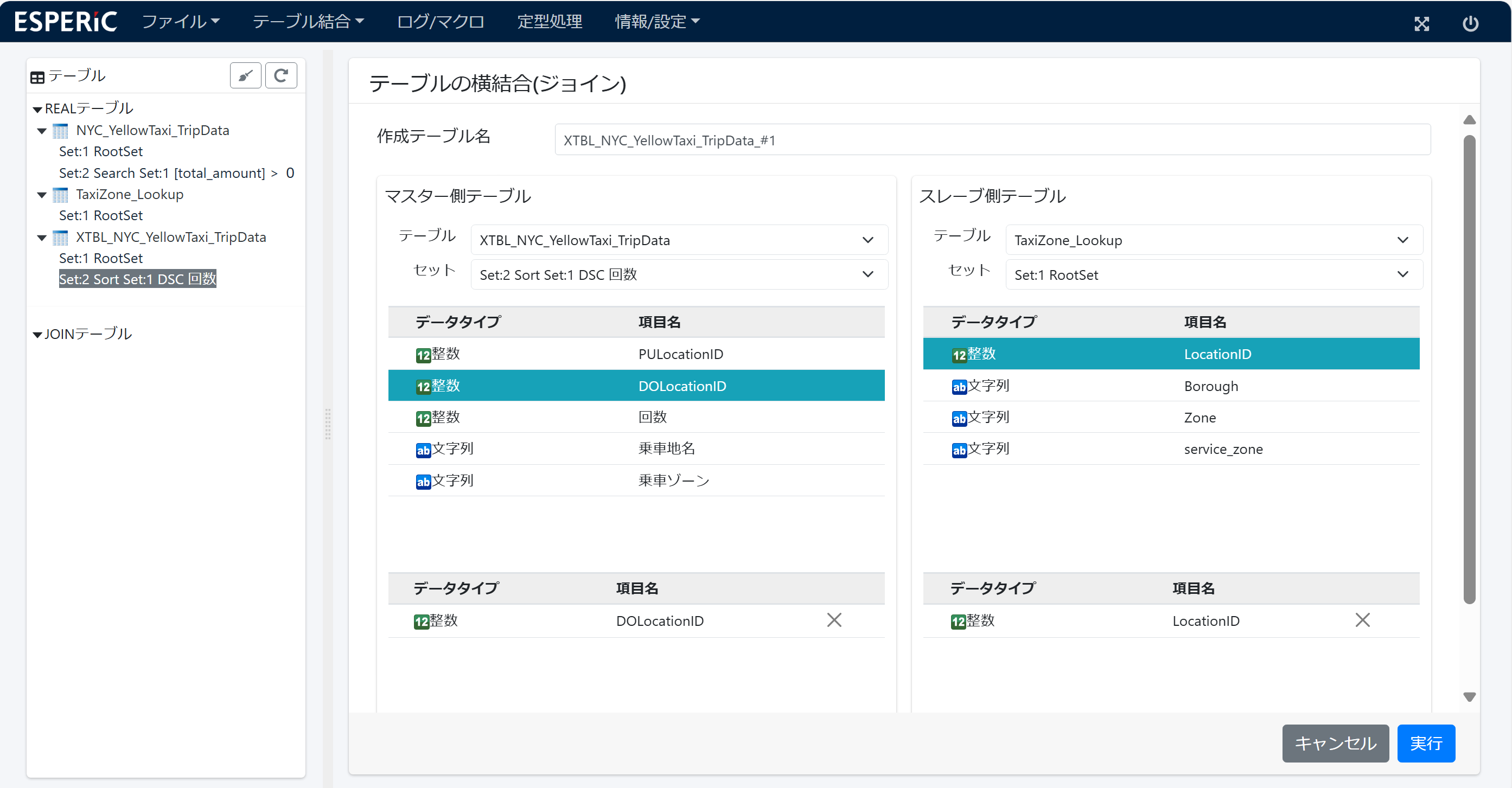
降車地名(BoroughとZone)が追加された ジョインテーブルが作成されます。
(6)2回目の項目転送... ジョインテーブルの 項目 BoroughとZone を項目転送します。集計テーブルに 降車地名(BoroughとZone)が追加されます。
(7)ジョインテーブルは 不要になったので 削除します。
(8)集計テーブルの項目名 BoroughとZone を 降車地名と降車ゾーン に変更します。
このように ジョインと項目転送を繰り返すことで、集計テーブルに 乗車地域名(乗車地名と乗車ゾーン) 降車地域名(降車地名と降車ゾーン)が追加されました。
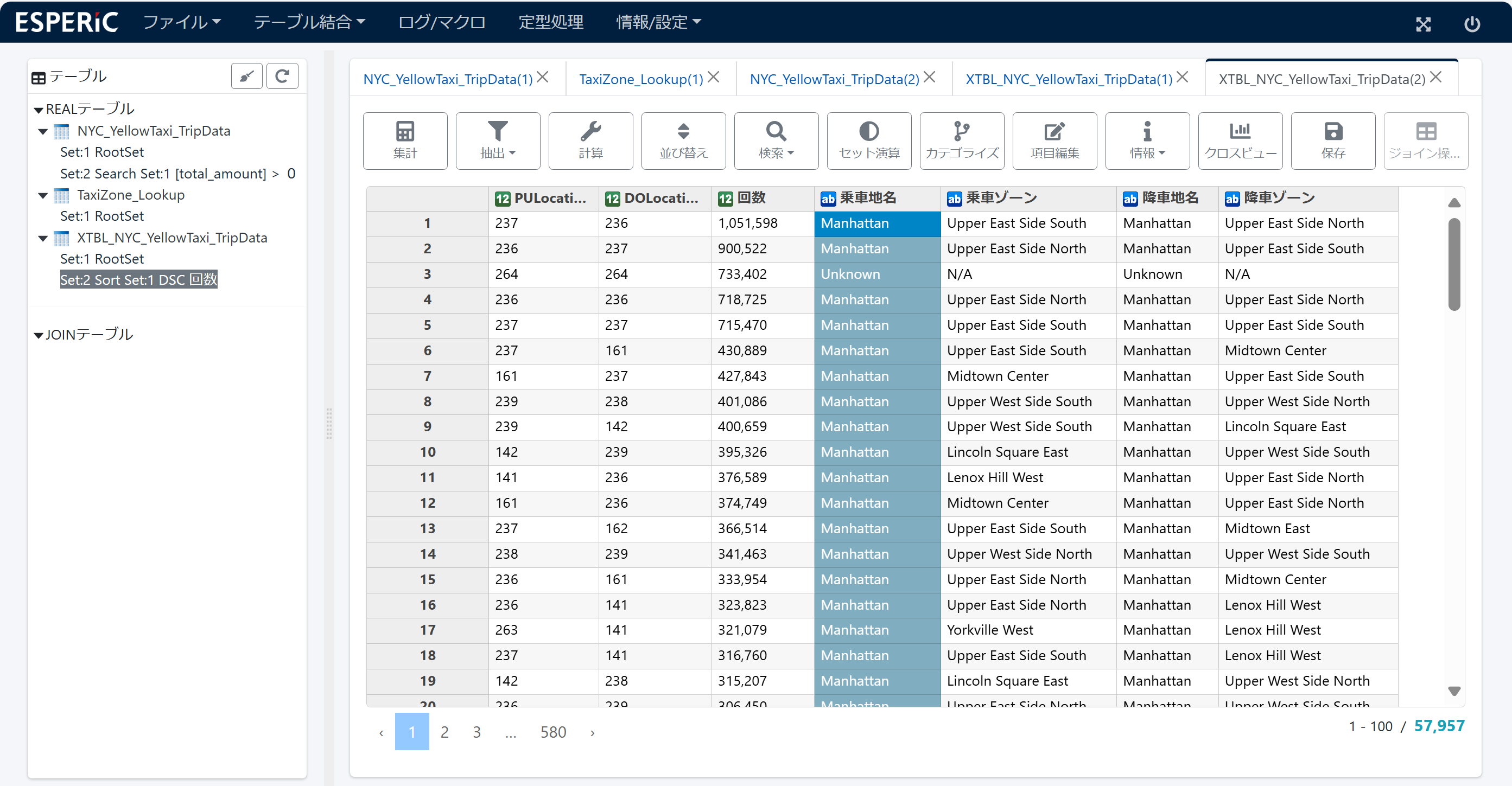
8.切り出し
集計テーブルの先頭から10行(トップ10)を切り出します。Set:3 が作成されます。
その Set:3 を サブテーブル抽出7で「Top10_YellowTaxi_FareRoutes」という名前のRealテーブルにします。さらに 項目名 PULocationIDとDOLocationID を 乗車地IDと降車地ID に変更し、項目を 回数、乗車地、降車地 の順に並べ替えます。
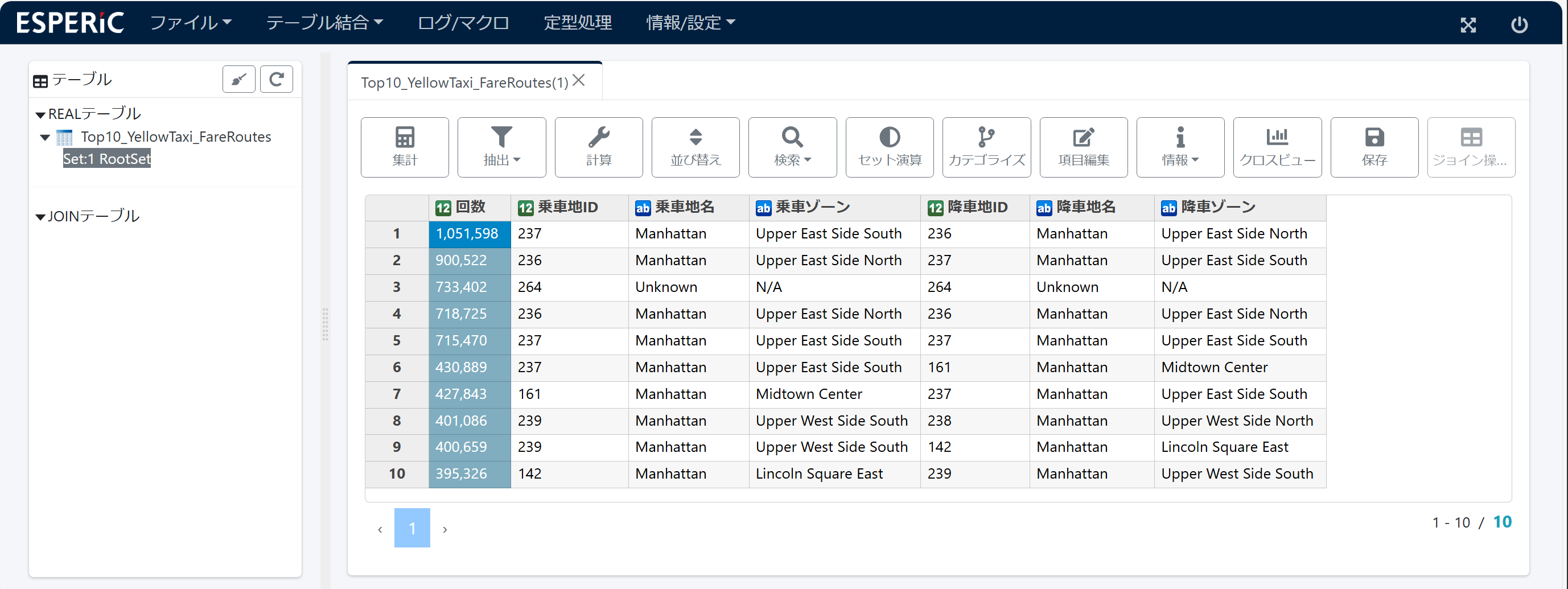
画面は完成したテーブルです。Yellow Taxi の営業範囲は ほとんど Manhattan 地区のようです。
9.エクスポート
Top10_YellowTaxi_FareRoutes テーブルを外部ファイル(CSV)に書き出します。このファイルを 可視化ツールに渡して グラフ表示などできます。
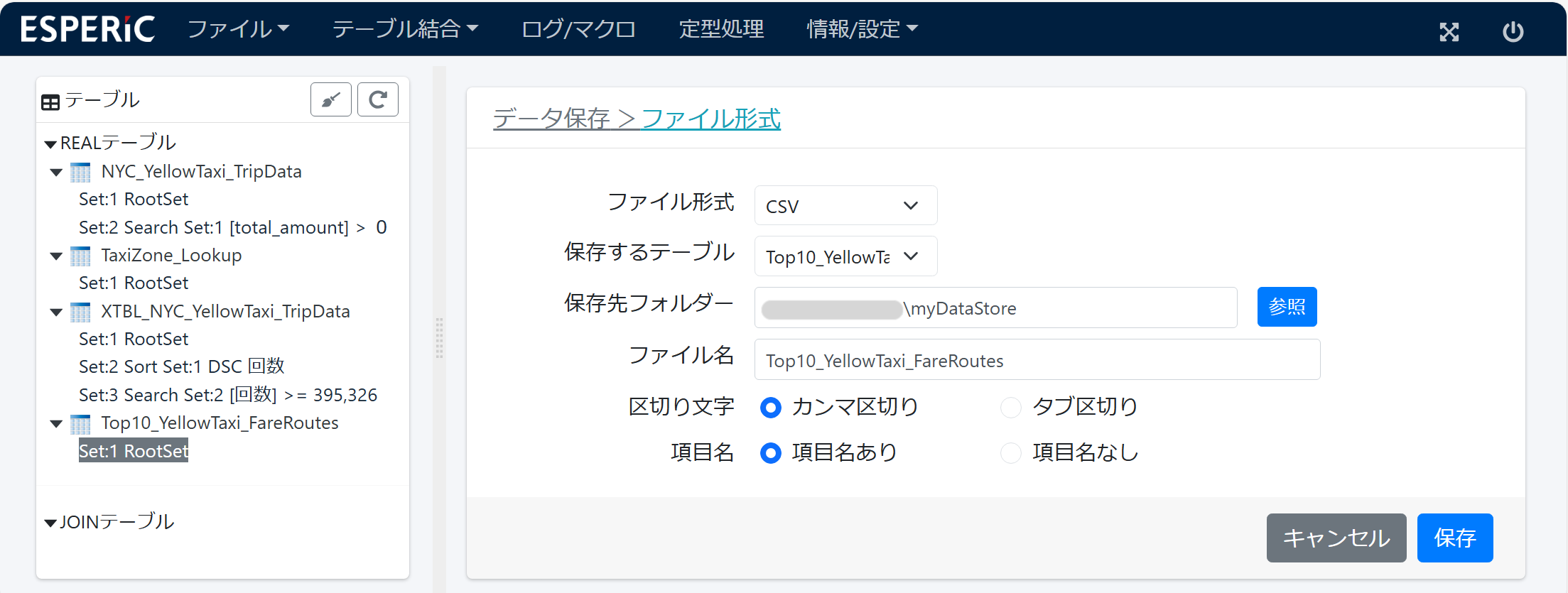
ESPERiCは インメモリデータ処理なので 必要なデータは外部ファイルに書き出しておく必要があります。
生成されたコード
ESPERiCの操作ログから 下記のような Pythonコード が生成できます。
# -*- coding: utf-8 -*-
from lfmRecipeCom import *
result = dsx.db_codeset("UTF8")
result = dsx.catalog("NYC_YellowTaxi_TripData", "/Users/guest/myDataStore/NYC_YellowTaxi_TripData.csv", "/Users/guest/myDataStore/structInfo/NYC_YellowTaxi_TripData/structInfo.txt")
result = dsx.catalog("TaxiZone_Lookup", "/Users/guest/myDataStore/TaxiZone_Lookup.csv", "/Users/guest/myDataStore/structInfo/TaxiZone_Lookup/structInfo.txt")
result = dsx.search("NYC_YellowTaxi_TripData", "total_amount", 1, "[total_amount] > 0")
result = dsx.xsum("NYC_YellowTaxi_TripData", 2, ['PULocationID', 'DOLocationID'], [['-', 'Yes', 'No', 'No', 'No', 'No']])
result = dsx.rename_item("XTBL_NYC_YellowTaxi_TripData", "N", "回数")
result = dsx.sort("XTBL_NYC_YellowTaxi_TripData", "回数", 1, "DSC")
result = dsx.join("XTBL_NYC_YellowTaxi_TripData_#1", "XTBL_NYC_YellowTaxi_TripData", "TaxiZone_Lookup", 2, 1, ['PULocationID'], ['LocationID'], "Inner", "No")
result = dsx.transfer_item("XTBL_NYC_YellowTaxi_TripData_#1", "Borough")
result = dsx.transfer_item("XTBL_NYC_YellowTaxi_TripData_#1", "Zone")
result = dsx.delete_table("XTBL_NYC_YellowTaxi_TripData_#1")
result = dsx.rename_item("XTBL_NYC_YellowTaxi_TripData", "Borough", "乗車地名")
result = dsx.rename_item("XTBL_NYC_YellowTaxi_TripData", "Zone", "乗車ゾーン")
result = dsx.join("XTBL_NYC_YellowTaxi_TripData_#1", "XTBL_NYC_YellowTaxi_TripData", "TaxiZone_Lookup", 2, 1, ['DOLocationID'], ['LocationID'], "Inner", "No")
result = dsx.transfer_item("XTBL_NYC_YellowTaxi_TripData_#1", "Borough")
result = dsx.transfer_item("XTBL_NYC_YellowTaxi_TripData_#1", "Zone")
result = dsx.delete_table("XTBL_NYC_YellowTaxi_TripData_#1")
result = dsx.rename_item("XTBL_NYC_YellowTaxi_TripData", "Borough", "降車地名")
result = dsx.rename_item("XTBL_NYC_YellowTaxi_TripData", "Zone", "降車ゾーン")
result = dsx.search("XTBL_NYC_YellowTaxi_TripData", "SeqNo", 2, "[SeqNo] <= 10")
result = dsx.extract_set("XTBL_NYC_YellowTaxi_TripData", 3, "No", "No", ['PULocationID', 'DOLocationID', '回数', '乗車地名', '乗車ゾーン', '降車地名', '降車ゾーン'], "Top10_YellowTaxi_FareRoutes")
result = dsx.rename_item("Top10_YellowTaxi_FareRoutes", "PULocationID", "乗車地ID")
result = dsx.rename_item("Top10_YellowTaxi_FareRoutes", "DOLocationID", "降車地ID")
result = dsx.move_item("Top10_YellowTaxi_FareRoutes", ['回数'], "乗車地ID")
result = dsx.move_item("Top10_YellowTaxi_FareRoutes", ['降車地ID'], "乗車ゾーン")
result = dsx.write_csv("Top10_YellowTaxi_FareRoutes", "/Users/guest/myDataStore/Top10_YellowTaxi_FareRoutes.csv", 1, "CSV", 1, -1, 1, -1, "Yes")
このコードは、Excelのマクロのように データハンドリングの反復操作を自動化するのが主な目的で ESPERiCのもとで実行しますが、独立した Pythonアプリ として実行することも可能です。Pythonなので 処理を追加したり 引数を扱うようなアプリに変更(ローコード)することも容易です。また、ESPERiC GEAR-Rest(Web API)を使用すれば クラウドサービスの ひとつのサービスアプリにもなります。
手書きコードとの比較
ESPERiCの操作と同じデータハンドリング処理を インメモリカラムナー技術を使っている Apache DataFusion-Python(SQL)でコードを書いてみました。
なお、予めお断りしておきますが、ここでは いずれが優れているか を評価するものではありません。
import datafusion
ctx = datafusion.SessionContext()
ctx.register_csv('nyc_yellowtaxi_tripdata', './NYC_YellowTaxi_TripData.csv')
ctx.register_csv('taxizone_lookup', './TaxiZone_Lookup.csv')
ctx.sql('''
SELECT
ROW_NUMBER() OVER(ORDER BY count DESC) AS "No.",
count AS "回数",
"PULocationID" AS "乗車地ID",
frloc."Borough" AS "乗車地名",
frloc."Zone" AS "乗車ゾーン",
"DOLocationID" AS "降車地ID",
toloc."Borough" AS "降車地名",
toloc."Zone" AS "降車ゾーン"
FROM (SELECT
"PULocationID",
"DOLocationID",
COUNT("DOLocationID") AS count
FROM (SELECT
*
FROM nyc_yellowtaxi_tripdata
WHERE total_amount > 0
)
GROUP BY
"PULocationID",
"DOLocationID"
)
JOIN taxizone_lookup AS frloc ON "PULocationID" = frloc."LocationID"
JOIN taxizone_lookup AS toloc ON "DOLocationID" = toloc."LocationID"
ORDER BY count DESC
LIMIT 10
''').write_csv('./Top10_YellowTaxi_FareRoutes.csv')
当然のことながら ESPERiCの生成コード に比べたらスマートです。
ESPERiCが生成するコードは、手操作に忠実なコードで、プログラミングとしては冗長な部分も含まれています。一方、手書きコードは 目的の結果を得るのに最適なコードとなっています。また、この手書きコードは SQLオプティマイザーによって さらに処理の最適化が行われ 実行も早い。
まとめ
ESPERiC を試してみて、ビッグデータ処理の速さ(対話処理の応答スピード)は CX(カスタマーエクスペリエンス)を左右する重要な要素だと感じました。使ってみて ビッグデータでも全くストレスなく 気持ちよく操作できました。
ただ 操作性(GUI)は 必ずしも良いとは言えません。GUIの設計コンセプトが不明ですが、スタージョインのように ユーザ目線ではなく データ処理エンジンの機能に沿った実装のようです。データ処理エンジンの機能を理解して使用するのであれば より良い CX を得ることが可能と思われます。
本稿で紹介した ESPERiC は このWebサイト を参照ください。また こちら から ダウンロードと6ヶ月無料で使用できるライセンスキーの申し込みができます。