はじめに
作曲する度に売れる米津玄師さん。
紡ぎ出される歌詞は人を魅了する力があるように思えます。
今回は、その魅力をディープラーニングに学習させてみようと思いました。
本記事は「データの前処理」までです。以下がその大まかな手順です。
- スクレイピングして、米津さんが作詞した歌詞を全て取得
- ディープラーニングの問題設定に沿うようにデータを整形
- 8:2で訓練データとテストデータに分ける
一般的に「前処理」とは、正規化など精度向上のためのデータ処理を差しますが、今回の「前処理」とは、ディープラーニングの入力や出力となるように整形することを表します。
使ったモデル
フレームワーク: Pytorch
モデル: Attentionを加えたseq2seq
seq2seqとAttention背景
「機械翻訳」に使われる手法の一つです。以下がseq2seqのイメージとなります。
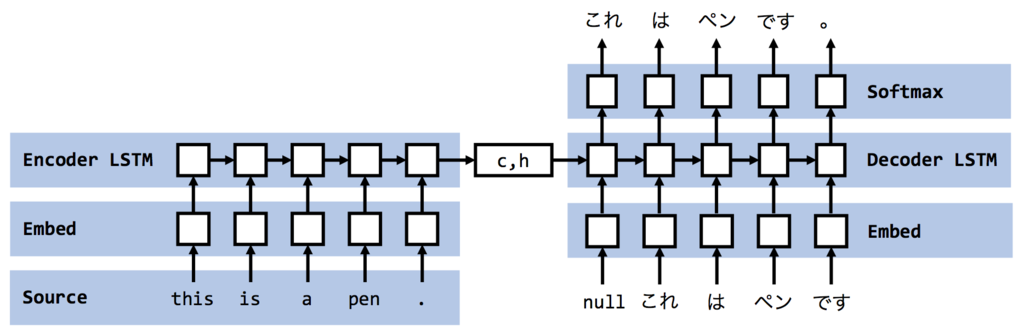
引用記事: Encoder-decoderモデルとTeacher Forcing,Scheduled Sampling,Professor Forcing
これによって Encoder 側で入力をエンコードした情報をもとに Decoder で文章生成できるのですが、実は若干の問題があります。それは、Decoderの入力を固定長のベクトルでしか表現できないというものです。Encoder の出力は隠れ層 $h$ なのですが、このサイズは固定です。それゆえ、入力系列の長さが長すぎるデータセットは、 $h$ に情報を適切に圧縮しきれず、入力系列の長さが短すぎるデータセットは、 $h$ にムダな情報を取り込んでしまいます。
そこで、 Encoder の最後の隠れ層の状態だけでなく、途中の隠れ層の状態も利用 したくなってきます。
これが、Attention が考案された背景です。
Attention機構
Attentionとは、時系列データを扱う際に過去の重要なポイントに注意を払う(=Attention)ための手法です。今回では、ある曲の「歌詞の一節」に対して「次の一節」を予測するので、次の一節を予測するために、前回の一節のどこに注目すればいいかといった形になります。以下がAttentionのイメージです。
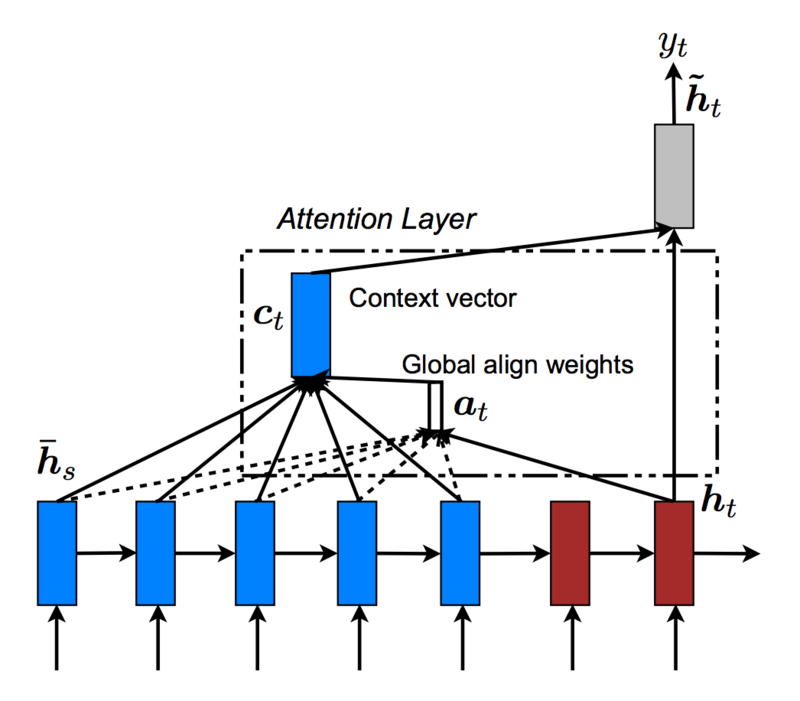
source: Effective Approaches to Attention-based Neural Machine Translation
参考論文によると、正確には Global Attention model と呼ばれます。Encoderの全ての隠れ状態をベクトルとしてまとめ、それらとDecoderの出力の内積をとることで、**「Encoderの全ての隠れ状態とDecoderの出力の類似度」**が得られます。この類似度を内積により測ることが「重要な要素に注目している」というAttentionと呼ばれる所以です。
実装
Google colabに必要な自作モジュールをアップロードした後、
後ほど記載するmain.pyをコピペして実行。
必要な自作モジュール

問題設定
以下のように、米津玄師さんがこれまでに出された曲の「一節」から「次の一節」を予測します。
|入力テキスト| 出力テキスト |
|-------+-------|
|あたしあなたに会えて本当に嬉しいのに | _当たり前のようにそれらすべてが悲しいんだ |
|当たり前のようにそれらすべてが悲しいんだ| _今 痛いくらい幸せな思い出が |
|今 痛いくらい幸せな思い出が| _いつか来るお別れを育てて歩く|
|いつか来るお別れを育てて歩く| _誰かの居場所を奪い生きるくらいならばもう|
これは歌詞ネットからスクレイピングさせていただき作成いたしました。
データ準備
スクレイピング
下記コードにてスクレイピングにより、歌詞を取得する
なお、これらはGoogle Colabで実行。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
import requests
from bs4 import BeautifulSoup
import re
import time
# setting
# Seleniumをあらゆる環境で起動させるChromeオプション
options = Options()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--proxy-server="direct://"');
options.add_argument('--proxy-bypass-list=*');
options.add_argument('--start-maximized');
options.add_argument('--headless');
class DriverConrol():
def __init__(self, driver):
self.driver = driver
def get(self, url):
self.driver.get(url)
def get_text(self, selector):
element = self.driver.find_element_by_css_selector(selector)
return element.text
def get_text_by_attribute(self, selector, attribute='value'):
element = self.driver.find_element_by_css_selector(selector)
return element.get_attribute(attribute)
def input_text(self, selector, text):
element = self.driver.find_element_by_css_selector(selector)
element.clear()
element.send_keys(text)
def select_option(self, selector, text):
element = driver.find_element_by_css_selector(selector)
Select(element).select_by_visible_text(text)
def click(self, selector):
element = self.driver.find_element_by_css_selector(selector)
element.click()
def get_lyric(self, url):
self.get(url)
time.sleep(2)
element = self.driver.find_element_by_css_selector('#kashi_area')
lyric = element.text
return lyric
def get_url(self):
return self.driver.current_url
def quit(self):
self.driver.quit()
BASE_URL = 'https://www.uta-net.com/'
search_word = '米津玄師'
search_jenre = '作詞者名'
driver = webdriver.Chrome(chrome_options=options)
dc = DriverConrol(driver)
dc.get(BASE_URL) # アクセス
# 検索
dc.input_text('#search_form > div:nth-child(1) > input.search_input', search_word)
dc.select_option('#search_form > div:nth-child(2) > select', search_jenre)
dc.click('#search_form > div:nth-child(1) > input.search_submit')
time.sleep(2)
# requestsで一気にurlを取得
response = requests.get(dc.get_url())
response.encoding = response.apparent_encoding # 文字化け対策
soup = BeautifulSoup(response.text, "html.parser")
side_td1s = soup.find_all(class_="side td1") # classがside td1のtd要素を全て取得
lyric_urls = [side_td1.find('a', href=re.compile('song')).get('href') for side_td1 in side_td1s] # side_td1sに含まれる, hrefに''songが含まれるaタグのhref要素を取得
music_names = [side_td1.find('a', href=re.compile('song')).text for side_td1 in side_td1s] # 全曲名を取得
# 歌詞を取得して、lyric_lisに追加していく
lyric_lis = list()
for lyric_url in lyric_urls:
lyric_lis.append(dc.get_lyric(BASE_URL + lyric_url))
with open(search_word + '_lyrics.txt', 'wt') as f_lyric, open(search_word + '_musics.txt', 'wt') as f_music:
for lyric, music in zip(lyric_lis, music_names):
f_lyric.write(lyric + '\n\n')
f_music.write(music + '\n')
取得された歌詞を一部抜粋
あたしあなたに会えて本当に嬉しいのに
当たり前のようにそれらすべてが悲しいんだ
今 痛いくらい幸せな思い出が
いつか来るお別れを育てて歩く
誰かの居場所を奪い生きるくらいならばもう
あたしは石ころにでもなれたならいいな
だとしたら勘違いも戸惑いもない
そうやってあなたまでも知らないままで
...
データ整形
現状は[問題設定]で示したデータには程遠いので「データの整形」を行う。
つまり、この処理を行います。

以下のコードでデータ整形を行う
わかりづらいコードにはなりますが、一応これで前処理は完了です。
from datasets import LyricDataset
import torch
import torch.optim as optim
from modules import *
from device import device
from utils import *
from dataloaders import SeqDataLoader
import math
import os
from utils
# ==========================================
# データ用意
# ==========================================
# 米津玄師_lyrics.txtのパス
file_path = "lyric/米津玄師_lyrics.txt"
edited_file_path = "lyric/米津玄師_lyrics_edit.txt"
yonedu_dataset = LyricDataset(file_path, edited_file_path)
yonedu_dataset.prepare()
# check
print(yonedu_dataset[0])
# 8:2でtrainとtestに分ける
train_rate = 0.8
data_num = len(yonedu_dataset)
train_set = yonedu_dataset[:math.floor(data_num * train_rate)]
test_set = yonedu_dataset[math.floor(data_num * train_rate):]
from sklearn.model_selection import train_test_split
from janome.tokenizer import Tokenizer
import torch
from utils import *
class LyricDataset(torch.utils.data.Dataset):
def __init__(self, file_path, edited_file_path, transform=None):
self.file_path = file_path
self.edited_file_path = edited_file_path
self.tokenizer = Tokenizer(wakati=True)
self.input_lines = [] # NNの入力となる配列(それぞれの要素はテキスト)
self.output_lines = [] # NNの正解データとなる配列(それぞれの要素はテキスト)
self.word2id = {} # e.g.) {'word0': 0, 'word1': 1, ...}
self.input_data = [] # 一単語一単語がID化された歌詞の一節
self.output_data = [] # 一単語一単語がID化された次の一節
self.word_num_max = None
self.transform = transform
self._no_brank()
def prepare(self):
# NNの入力となる配列(テキスト)とNNの正解データ(テキスト)となる配列を返す
self.get_text_lines()
# date.txtで登場するすべての文字にIDを割り当てる
for line in self.input_lines + self.output_lines: # 最初の一節とそれ以降の一節
self.get_word2id(line)
# 一節の単語数の最大値を求める
self.get_word_num_max()
# NNの入力となる配列(ID)とNNの正解データ(ID)となる配列を返す
for input_line, output_line in zip(self.input_lines, self.output_lines):
self.input_data.append([self.word2id[word] for word in self.line2words(input_line)] \
+ [self.word2id[" "] for _ in range(self.word_num_max - len(self.line2words(input_line)))])
self.output_data.append([self.word2id[word] for word in self.line2words(output_line)] \
+ [self.word2id[" "] for _ in range(self.word_num_max - len(self.line2words(output_line)))])
def _no_brank(self):
# 行の間の空白を取る
with open(self.file_path, "r") as fr, open(self.edited_file_path, "w") as fw:
for line in fr.readlines():
if isAlpha(line) or line == "\n":
continue # 英字と空白は飛ばす
fw.write(line)
def get_text_lines(self, to_file=True):
"""
空行なしの歌詞ファイルのパスfile_pathを受け取り、次のような配列を返す
"""
# 米津玄師_lyrics.txtを1行ずつ読み込んで「歌詞の一節」と「次の一節」に分割して、inputとoutputで分ける
with open(self.edited_file_path, "r") as f:
line_list = f.readlines() # 歌詞の一節...line
line_num = len(line_list)
for i, line in enumerate(line_list):
if i == line_num - 1:
continue # 最後は「次の一節」がない
self.input_lines.append(line.replace("\n", ""))
self.output_lines.append("_" + line_list[i+1].replace("\n", ""))
if to_file:
with open(self.edited_file_path, "w") as f:
for input_line, output_line in zip(self.input_lines, self.output_lines):
f.write(input_line + " " + output_line + "\n")
def line2words(self, line: str) -> list:
word_list = [token for token in self.tokenizer.tokenize(line)]
return word_list
def get_word2id(self, line: str) -> dict:
word_list = self.line2words(line)
for word in word_list:
if not word in self.word2id.keys():
self.word2id[word] = len(self.word2id)
def get_word_num_max(self):
# 長さが最大のものを求める
word_num_list = []
for line in self.input_lines + self.output_lines:
word_num_list.append(len([self.word2id[word] for word in self.line2words(line)]))
self.word_num_max = max(word_num_list)
def __len__(self):
return len(self.input_data)
def __getitem__(self, idx):
out_data = self.input_data[idx]
out_label = self.output_data[idx]
if self.transform:
out_data = self.transform(out_data)
return out_data, out_label
今回は前処理まで
思ったよりコードが長くなりそうですので、今回は「データの前処理」までとさせていただきます。