はじめに
フューチャー Advent Calendar 2024における4日目の記事となります。昨日は@shibukawaさんのデザインパターンに関する記事でした。
BigQueryはData WareHouse(DWH)サービスとして非常に優秀です。最近は画像や音声といった非構造化データも扱えるようになってきていることから、データの蓄積もBigQuery側に寄せるData Lakehouse(DLH)サービスとも言われるようになってきております。
ただ、DLHとして扱うのであればセンシティブなデータを蓄積していくことにもなるので、データセキュリティをしっかりと高めるためにもアクセス制御はしっかりと施しておきたいものです。そこで、本記事ではBigQueryをがっちり守るための代表的な方法を紹介したいと思います。
IAM
Identity and Access Management(IAM)はGoogle Cloudのサービスとしてはアクセス制御の基本となります。使い方としては個人やグループ、サービスアカウントに事前定義のRoleを付与することでリソースへの権限を持たせることが可能になります。事前定義のRoleとはGoogle Cloud側が用意しているユースケースみたいなものになり、各リソース毎で色々設定されています。BigQueryのRoleはこちらの公式ドキュメントに載っています。
また、種類が多く、Role内で定義されている権限もそれぞれ異なるため自分は以下のサイトをよく使って調べています。
※Google公式のページではないので、公式ドキュメントと併用して使いましょう。
BigQuery向けでは、以下の単位に対してRoleの利用が可能です。
- プロジェクト:プロジェクトに存在する全てのBigQueryリソースが対象
- データセット:特定のデータセットが対象
- テーブル:特定のデータセットに存在する特定のテーブルが対象
IAM Conditionsとタグ
特定のデータセット・テーブルのみデータを閲覧許可したい場合、上記で挙げたように特定のリソースに対してIAMを付与することができますが、量が増えてくると管理が大変になってきます。
## 複数人へデータセットの権限付与を行う例
resource "google_bigquery_dataset_iam_member" "viewer" {
for_each = ["test1@example.com", "test2@example.com", "test3@example.com"]
dataset_id = google_bigquery_dataset.dataset.dataset_id
role = "roles/bigquery.dataViewer"
member = "user:${each.value}"
}
そこでIAM Conditionsとタグ機能を利用して、タグの条件を満たす場合のみIAMのPermissionが利用できるような形にするとかなり楽になります。
(日本語ドキュメントだとPreviewになっていますが、英語ドキュメントではGAになってます。1)
例えば、部門を表すteamというキーとそのキーに対してfrontendというバリューを作ります。
resource "google_tags_tag_key" "team" {
parent = "projects/${local.project_id}"
short_name = "team"
}
resource "google_tags_tag_value" "frontend" {
parent = "tagKeys/${google_tags_tag_key.department.name}"
short_name = "frontend"
}
作ったキーとバリューをBigQueryのデータセットへ付与します。
resource "google_bigquery_dataset" "dataset_frontend" {
project = google_project.project_one.project_id
dataset_id = "dataset_test"
location = "asia-northeast1"
resource_tags = {
"${google_project.project_one.project_id}/${google_tags_tag_key.team.short_name}" = "${google_tags_tag_value.frontend.short_name}"
}
}
タグが付与されたデータセットは以下の画像のようにTagsに表示されます。
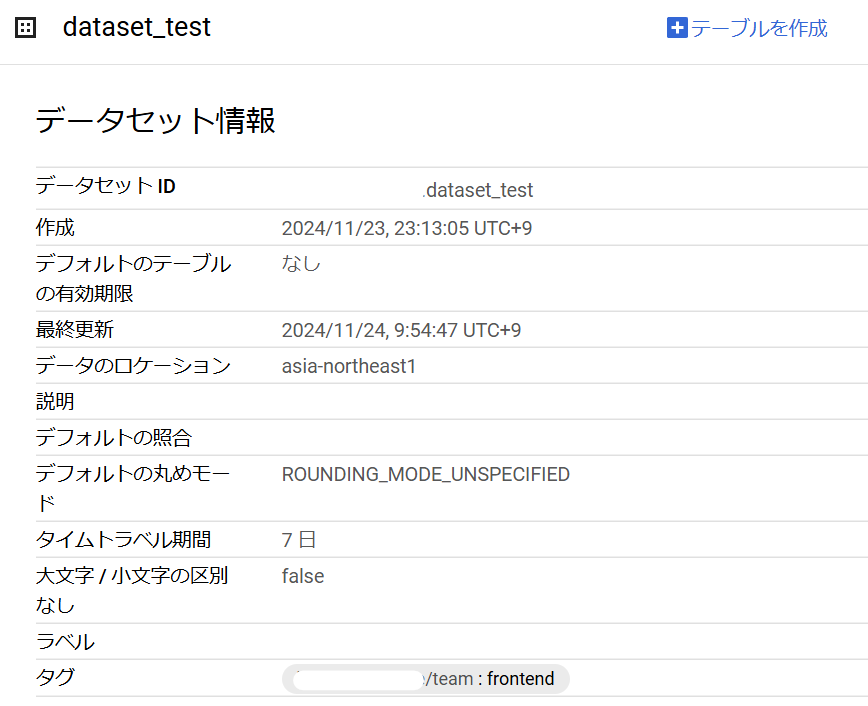
この状態でIAM Conditionsを利用したIAMを付与します。
resource "google_project_iam_member" "test_user" {
project = google_project.project_one.project_id
role = "roles/bigquery.dataViewer"
member = "user:test1@example.com"
condition {
title = "Tag Condition"
expression = "resource.matchTagId('${google_tags_tag_key.team.id}', '${google_tags_tag_value.frontend.id}')"
description = "Allowed attached tag: ${google_tags_tag_value.frontend.short_name}."
}
}
これによって条件と合致するタグが付与されたデータセットのみが閲覧できるようになり、閲覧させたいデータセットが増えた場合はタグを付与していくだけの運用となります。データセット毎の権限だと「データセット」→「共有」→「権限の管理」と遷移する必要がありましたが、タグは「データセット情報」から確認することが可能なので、可視性も高いです。
ちなみにIAM Conditions自体はタグだけではなく、データセット名やリソースの種類にも適用可能です。そしてこの機能はBigQueryに限られず、他のサービスでも利用可能です。
ただ、難点としては同じキーに対して1つのバリューしか付与できないという制約があります。例えば既にキー:team、バリュー:frontendが付与されているデータセットに対して、キー:team、バリュー:backendを付与することができません。
そのため、タグの付与運用に関してはデータセットに対して一意に決まるものを付与する運用がよさそうです。例えば、sensitive/non-sensitiveといった情報の機密度合いやtokyo/virginia/frankfurtといったRegionなどが挙げられます。
VPC Service Controls
VPC Service Controlsを利用するとプロジェクトやフォルダに存在するGoogle Cloudのサービス自体に対してアクセス制御を施すことができます。制御する際はAccess Context Managerを利用し、IPアドレス、個人アカウント(メールアドレス)、グループのメールアドレス、サービスアカウント、デバイス情報などと幅広いラインナップが対象になっております。
ただし、すべてのGoogle CloudサービスにおいてVPC Service Controlsの利用が可能というわけではないため、利用する前に公式ドキュメントを確認する必要があります。
詳しい設定方法は過去の拙著記事に載っておりますので割愛しますが、これまでVPC Service Controlsを運用してきた経験に基づく要点を紹介したいと思います。
アクセスレベルが一番強い
VPC Service Controlsを設定する際にアクセスレベルの設定があります。

Terraformだと以下になります。
resource "google_access_context_manager_service_perimeter" "project_one_perimeter" {
parent = "accessPolicies/${google_access_context_manager_access_policy.access_policy.name}"
name = "accessPolicies/${google_access_context_manager_access_policy.access_policy.name}/servicePerimeters/test_perimeter"
title = "TEST"
status {
// 境界を作るサービスを列挙する
restricted_services = [
"bigquery.googleapis.com",
]
// 境界を作るプロジェクト
resources = [
"projects/${local.projects_num.project_one}",
]
// アクセスレベル
// ここが一番強い
access_levels = [
google_access_context_manager_access_level.authorized_context.name
]
# // 以下はアクセスレベルではねられた場合に適用される
ingress_policies {
// ...
境界が設定された際にこのアクセスレベル(access_levels)が一番最初に評価されるため、アクセスレベルで許可されているIPアドレスやPrincipalsは制限付きサービス(restricted_services)に対してIngress/Egress問わずアクセスが可能となります。もし社内環境に対してアクセス可としたい場合には、このアクセスレベルで設定しているAccess Context Managerのアクセスレベルにて社内IPアドレスを許可する設定を入れるとよさそうです。
LookerStudioでデータを使いたい
BigQueryをVPC Service Controlsで守りたいが一部のデータはBIツールであるLooker Studioで利用したい、といった需要は結構あるかと思います。その場合、Service Accountを利用することで解決できます。
まず、LookerStudioで使いたいService Accountに対してVPC Service Controlsの設定でBigQueryへのIngressを許可します。
// VPC Service ControlsのPerimeterを設定する内容から一部抜粋
ingress_policies {
ingress_from {
identities = [
"serviceAccount:test@test-project.iam.gserviceaccount.com",
]
sources {
access_level = "*"
}
}
ingress_to {
resources = ["*"]
operations {
service_name = "bigquery.googleapis.com"
# method_selectorsは要調整
# データの参照のみであればbigquery.jobs.*は必要ない
dynamic "method_selectors" {
for_each = [
"bigquery.datasets.get",
"bigquery.tables.get",
"bigquery.tables.list",
"bigquery.tables.getData",
"bigquery.jobs.create",
"bigquery.jobs.update"
]
content {
permission = method_selectors.value
}
}
}
}
}
// ...
次にLookerStudioで参照したいデータセットに対してService Accountへ閲覧権限を付与します。
# dataset_idが複数ある場合は、for_eachを使うとよさそう
resource "google_bigquery_dataset_iam_member" "looker_studio" {
dataset_id = google_bigquery_dataset.non_sensitive_dataset.dataset_id
role = "roles/bigquery.dataViewer"
member = "serviceAccount:test@test-project.iam.gserviceaccount.com"
}
この閲覧権限の付与に関しては、IAM Conditionsとタグを利用するとより効率化できそうです。
最後にLookerStudioにおけるBigQueryからデータを参照する際の認証情報を変更します。
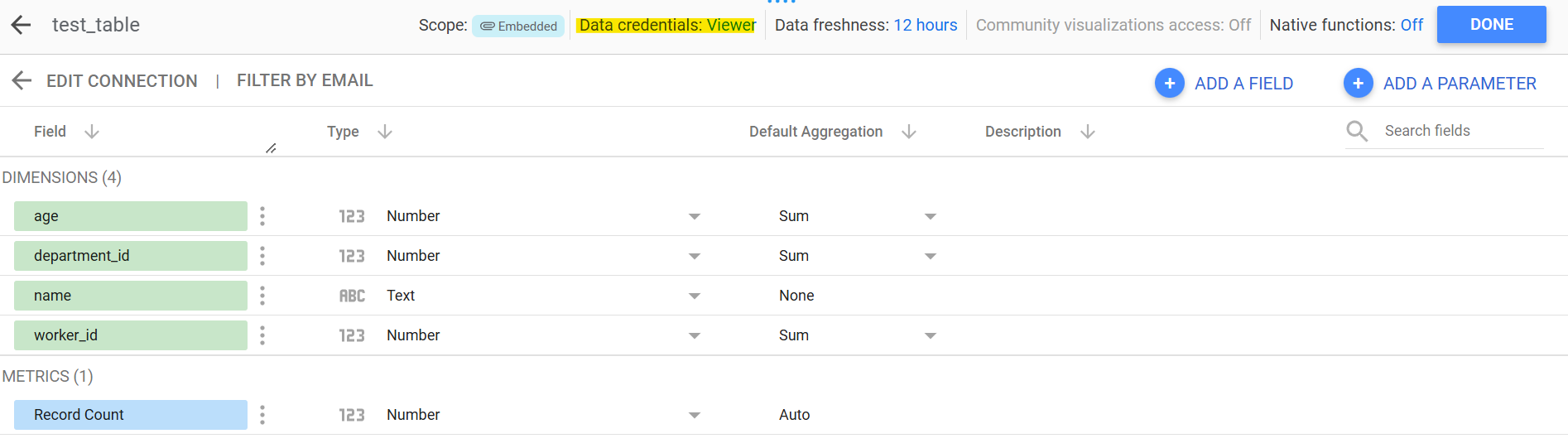
マーカー部分のようにService Accountを認証情報として利用することが可能となっております。

※この機能を利用する前にLookerStudioのService Agentに対して権限付与が必要になります。詳しくは以下のドキュメントを参照してください。
この設定によって、BigQueryがVPC Service Controlsによって守られていたとしてもLookerStudioにて参照することが可能となります。
Google Spreadsheetへのエクスポートを塞ぐ
VPC Service ControlsでIngress/Egressを守っていたとしても、データの持ち出しに関してはSpreadSheetに出力という抜け道があります。

(Google Driveに対してはVPC-SCで守られます)

この機能を制限したい場合はDrive SDK APIの利用を禁止することで穴を塞ぐことは可能なのですが、社用Google Workspaceに対してこの設定を行うと全社員に対して影響が出てしまうため、なるべく影響は小さくしたいです。
そこでドメインを持っていれば無料で使えるIDaaSであるCloud Identityを利用し、データアクセス用のアカウントを作るという方法をとります。
まずはCloud Identityで作ったIDに対してDrive SDK APIを禁止します。これで完全にGDriveやSpreadSheetへの出力は塞がれます。

次にデータアクセス用のアカウントを作ります。
アカウントのグループも作ることができるため、今回はグループを利用します。

グループにIAMを付与します。
resource "google_project_iam_member" "group-a" {
for_each = toset([
"roles/bigquery.dataViewer",
"roles/bigquery.jobUser"
])
project = local.project_id
role = each.value
member = "group:test-group@test.com"
}
Groupのみをアクセスレベルで許可するように編集します。
resource "google_access_context_manager_access_level" "authorized_context" {
parent = "accessPolicies/${google_access_context_manager_access_policy.access_policy.name}"
name = "accessPolicies/${google_access_context_manager_access_policy.access_policy.name}/accessLevels/authorized_context"
title = "Authorized Context"
basic {
// ここはデフォルトがANDなので注意
combining_function = "AND"
conditions {
ip_subnetworks = [
"XXX.XXX.XXX.XXX/29"
]
}
conditions {
members = [
"group:test-group@test.com"
]
}
}
}
これによってVPC Service Controlsに守られたBigQueryに対しては社用のIPアドレスかつ、指定されたグループに所属していないとアクセスできないようになりました。また、この条件を満たしていたとしても、Drive SDK APIが無効になっているので出力できなくなります。

まだローカルへの保存という抜け道があるのですが、Windows VMを立てて、そのVMからのみBigQueryへのアクセスを許可するという方法を取ることでローカル保存の穴も塞げます(Remote Desktop⇔ローカルへのコピペはWindowsの機能で禁止できます)。
まとめ
本記事ではデータ分析環境としてのBigQuery運用経験に基づいて、主にアクセス制御に関する豆知識をまとめて紹介しました。セキュリティ事故を防ぐためにも、適切かつ最小限のアクセスのみを許可した環境に保ちたいものです。
ただ、ローカルでスクショを撮られたり、PCの画面に対してスマホなどで撮影される場合はGoogle Cloudの機能だけではどうしようもないのが現状です。アクセスを許可するユーザーのバックグラウンドチェックでリテラシーやモラルを確認する必要があり、最終的には性善説に則って運用することが求められます。
2024年も遂に12月ということで家や職場の大掃除と兼ねて、アクセス制御についても一度棚卸してみてはいかがでしょうか?
明日は@kaedemaluさんの記事になります。お楽しみに!
-
Google公式ドキュメントあるある。英語ドキュメントでPreviewと記載されているものが本当にPreviewです。 ↩