はじめに
この記事の目的
ServiceNowには、IntegrationHub Importというデータインポートタスクを自動化するための統合インターフェースが存在します。
この機能を業務で利用してみたので、どのような業務要件に適しているか、開発者視点で見て利用しやすいかといった観点をこの記事で紹介してみたいと思います。
本記事は筆者個人としての投稿であり、いかなる組織の公式な見解ではありません。
また、守秘義務および情報管理の観点から、具体的な業務要件や実際に利用した外部ツールの名称は抽象化して記載します。
業務要件
- スケジュール:月次(手動)
- 件数:数千〜数万件
- 連携元:外部SaaSツール
- 連携方法:REST API
- 備考:
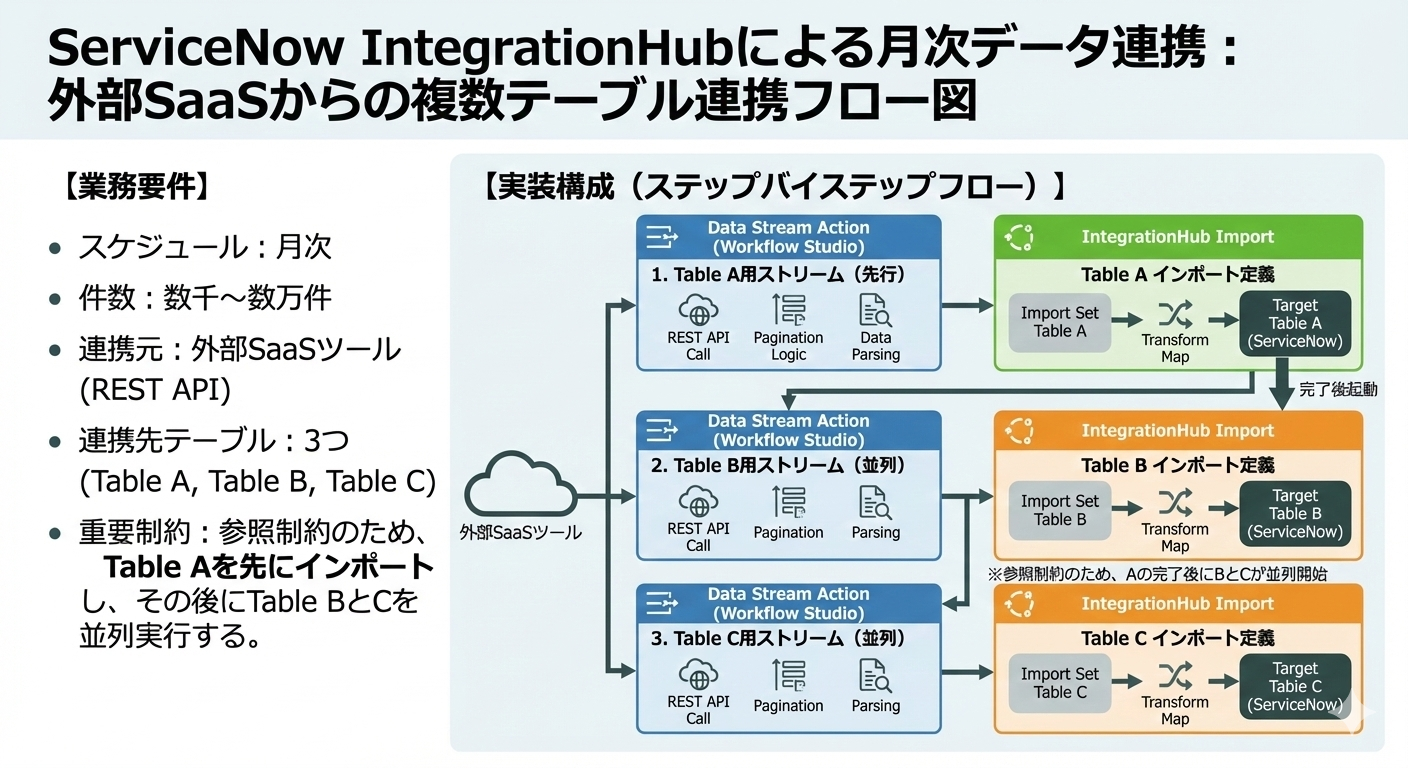
- 単一テーブルではなく、テーブルAをインポートした後にテーブルB, Cをインポートする必要がある(テーブルB,Cは並列実行しても問題ない)
- インポートデータの重複は許容されない
- 連携時エラーとなったレコードや空のままインポートされた項目があれば、それらを簡単にチェックできるようなインターフェースが必要
- 同様のインポート処理をREST MessageとBusiness Ruleの組み合わせで実装された実績があるが、可能であればインポート処理実行時間を短縮したい
業務要件としては上記の通りですが、IntegrationHubライセンスを利用できる状況だったため、今回はIntegrationHub Importを初めて選択してみました。
実装構成
実装構成としては、外部ツールのデータセットをインポートセットに取り込むパート(1)と、取り込んだデータをServiceNowのテーブルにマッピングするパート(2)の二つに分けられます。
それぞれ、以下の機能を利用します。
▼パート(1):Data Stream Action(Workflow Studio)
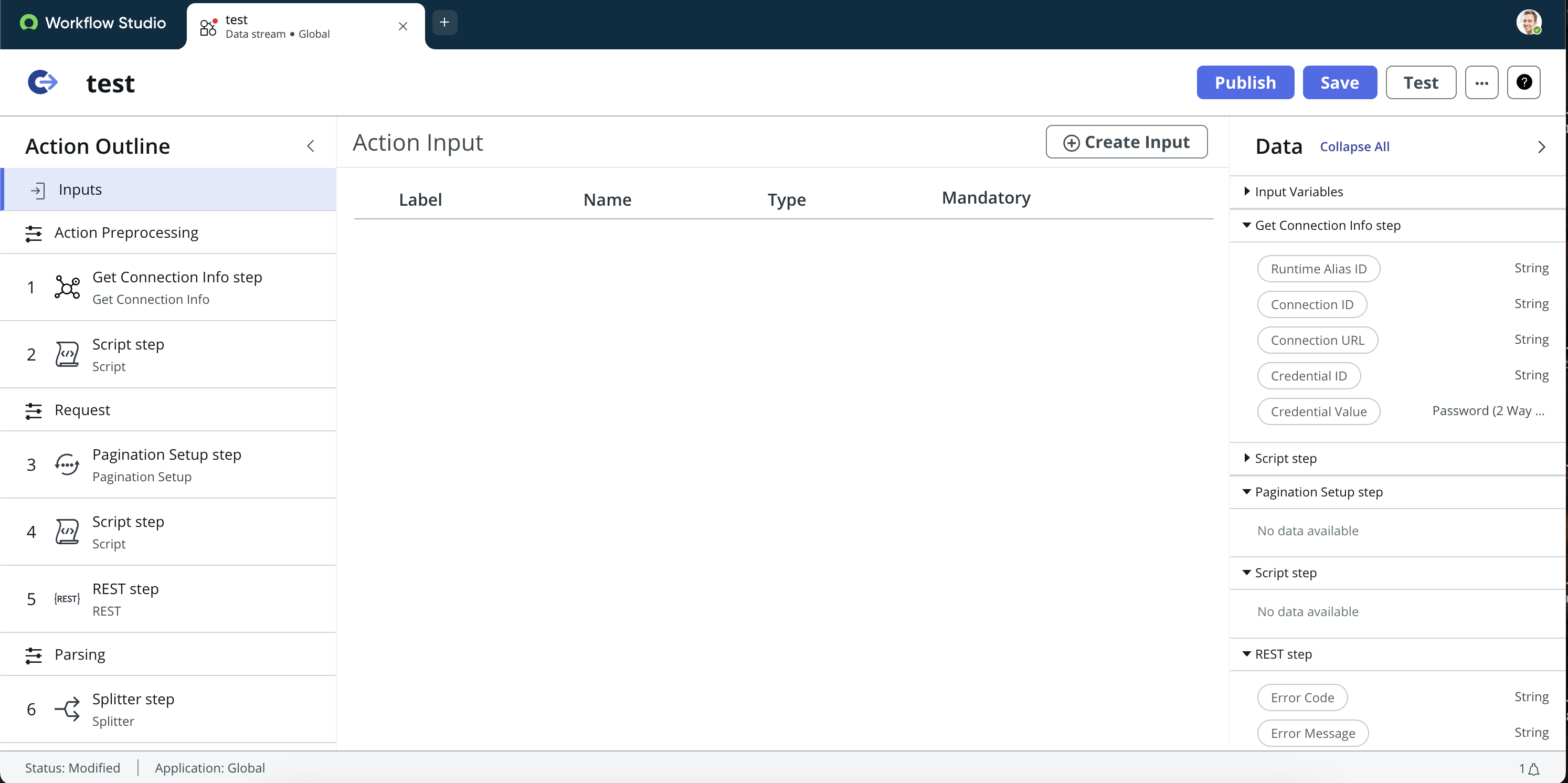
PDIでData Stream Actionが表示されない方は、こちらのフォームに沿ってIntegrationHubの専用プラグインを有効化してください。
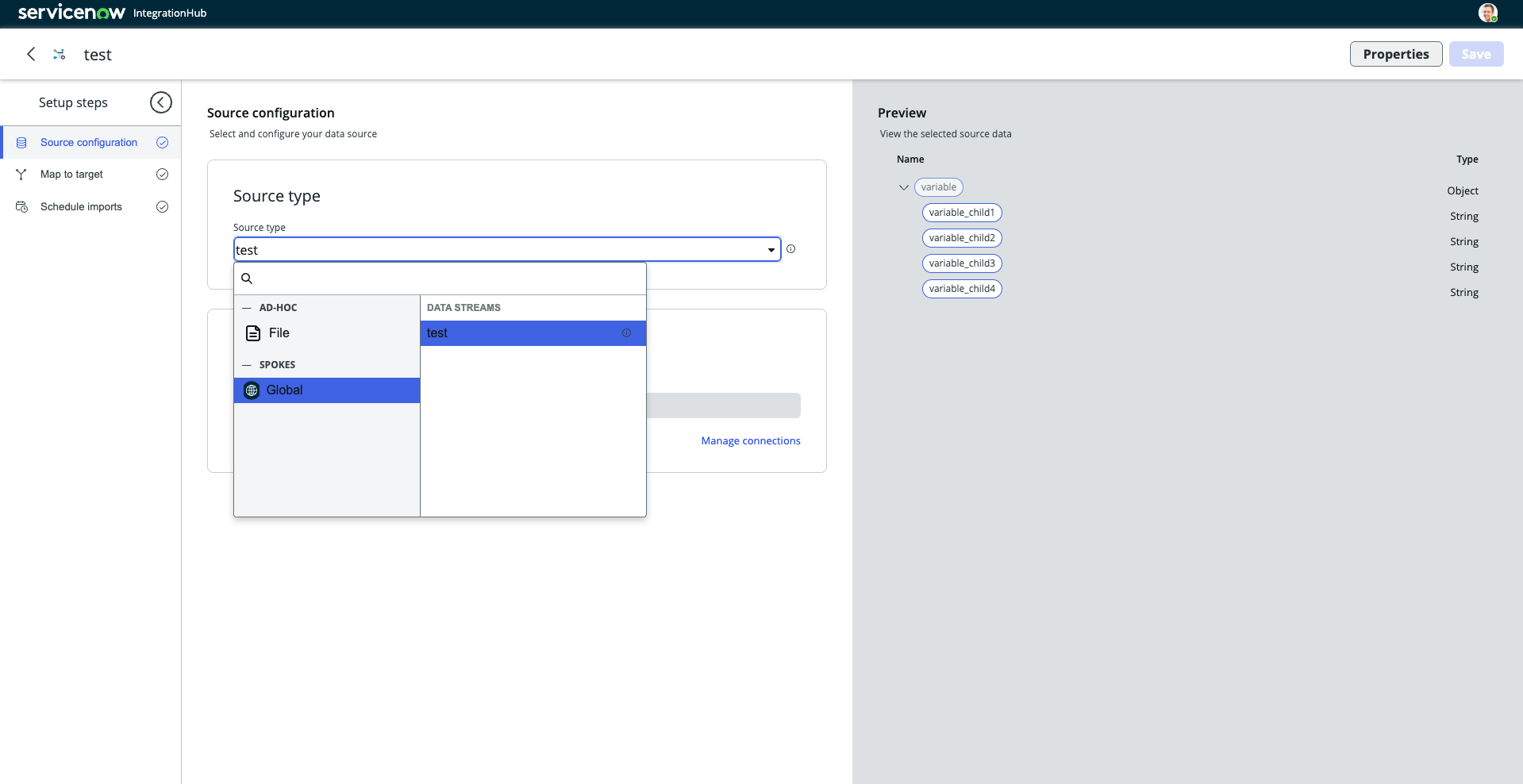
▼パート(2):IntegrationHub Import
なお、Data Stream ActionをPublishすることにより、Data Stream Actionで取得したデータセットを IntegrationHub Importのインプットとして連携させることができます。
▼PublishされたData Stream Actionがあれば、IntegrationHub Importで選択可能
これまでの話をまとめると、以下の画像のようになります。
なお、IntegrationHub ImportからData Stream Actionにデータは流れないので、その向きの矢印は無視でお願いします。
▼業務要件と実装構成のまとめ(Powered by Nano Banana🍌)
REST Message(フルスクラッチ実装)との比較
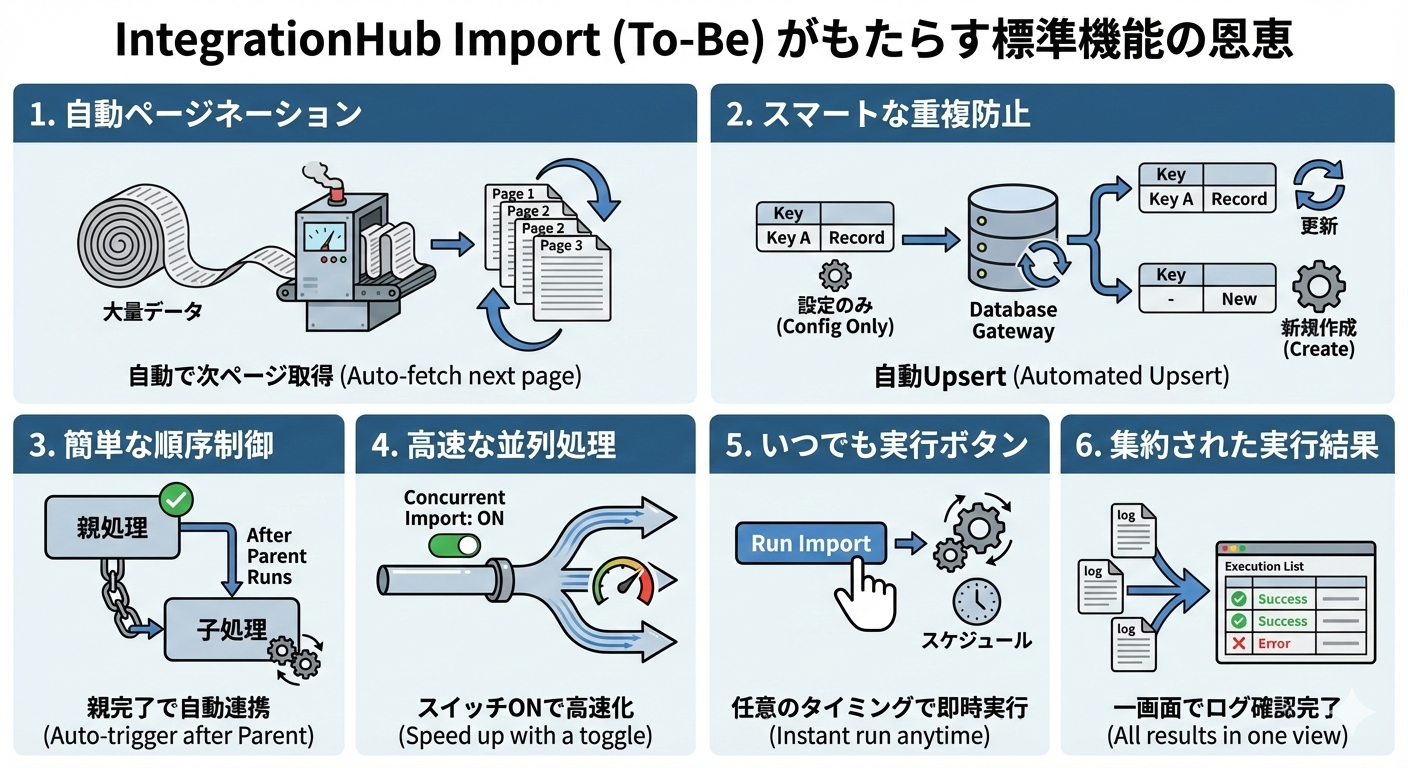
REST Messageでの実装と比べて特によかったことは、標準機能のカバレッジがとにかく広く、結果として実装コスト・運用コストが著しく下がるという点です。
以下、具体的にどのような標準機能がカバーされているのか紹介します。
1. ページネーション
そもそもの話として、多くの外部APIでは1回のAPI要求で取得できるデータ量に上限が設けられています。
そのため、実際の連携では1回の要求ですべてのデータを取得するのではなく、複数回のAPI要求を行い、段階的に全体を取得するという手順を踏むのが一般的です。
Data Stream Actionでも、API仕様に合わせてどの条件で次ページを取得するかといったページングの判定ロジック自体はスクリプトで書く必要があるのですが、次ページが必要な場合にはData Stream Actionが自動的に次のAPI要求を送信します。
以下の画像は、ページング条件を定義するスクリプトの実装例です。
多くの場合、必要なロジックは数行程度のシンプルな記述で完結するため、処理の見通しが良く、API仕様の把握や修正もしやすい構成になります。
▼Workflow Studioでのページネーション実装画面
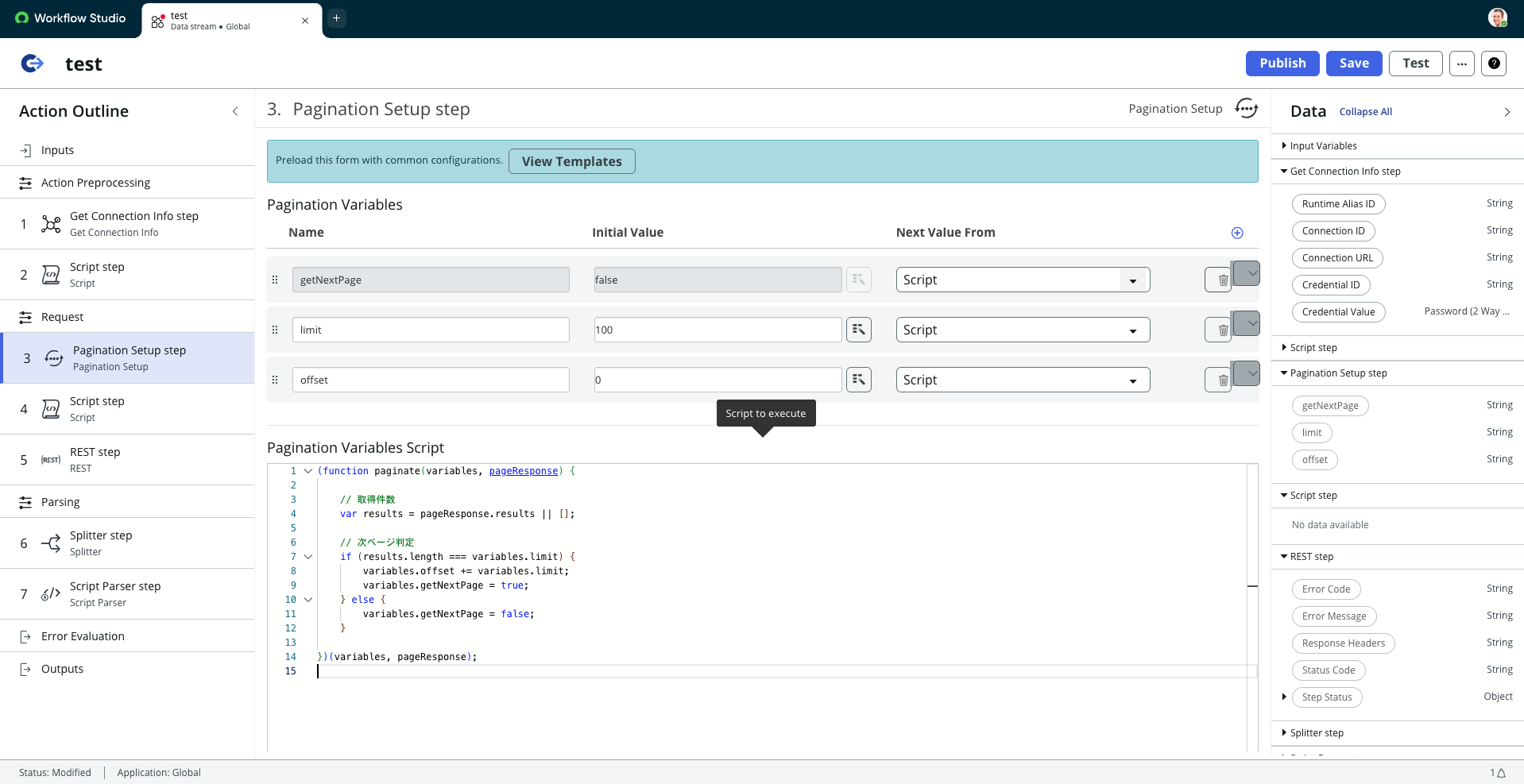
Data Stream Actionを利用するにあたっては、1ページ分のAPI要求ごとに1トランザクションとしてカウントされることに注意してください。
なお、トランザクションはIntegrationHubの課金単位です。
2. 重複防止
REST Messageによる実装では、外部SaaS側のレコードIDなどをキーとしてGlideRecordで既存レコードを検索し、すでに取り込まれているかどうかを判定することで、重複したレコードが登録されないように制御するケースが一般的です。
そのため、検索処理や更新・新規作成の分岐ロジックをスクリプトで明示的に実装する必要があります。
一方、IntegrationHub Importでは、取り込み時にキーを指定することで、そのキーに一致するレコードが存在しない場合は新規作成、存在する場合は更新を行う、いわゆるUpsert処理を標準機能として実行してくれます。
この仕組みにより、重複防止のための検索や分岐ロジックをスクリプトで記述する必要はなく、設定だけで対応できる点が大きな違いです。
▼IntegrationHub Importでのマッピング実装画面(青いトグルでキー指定)
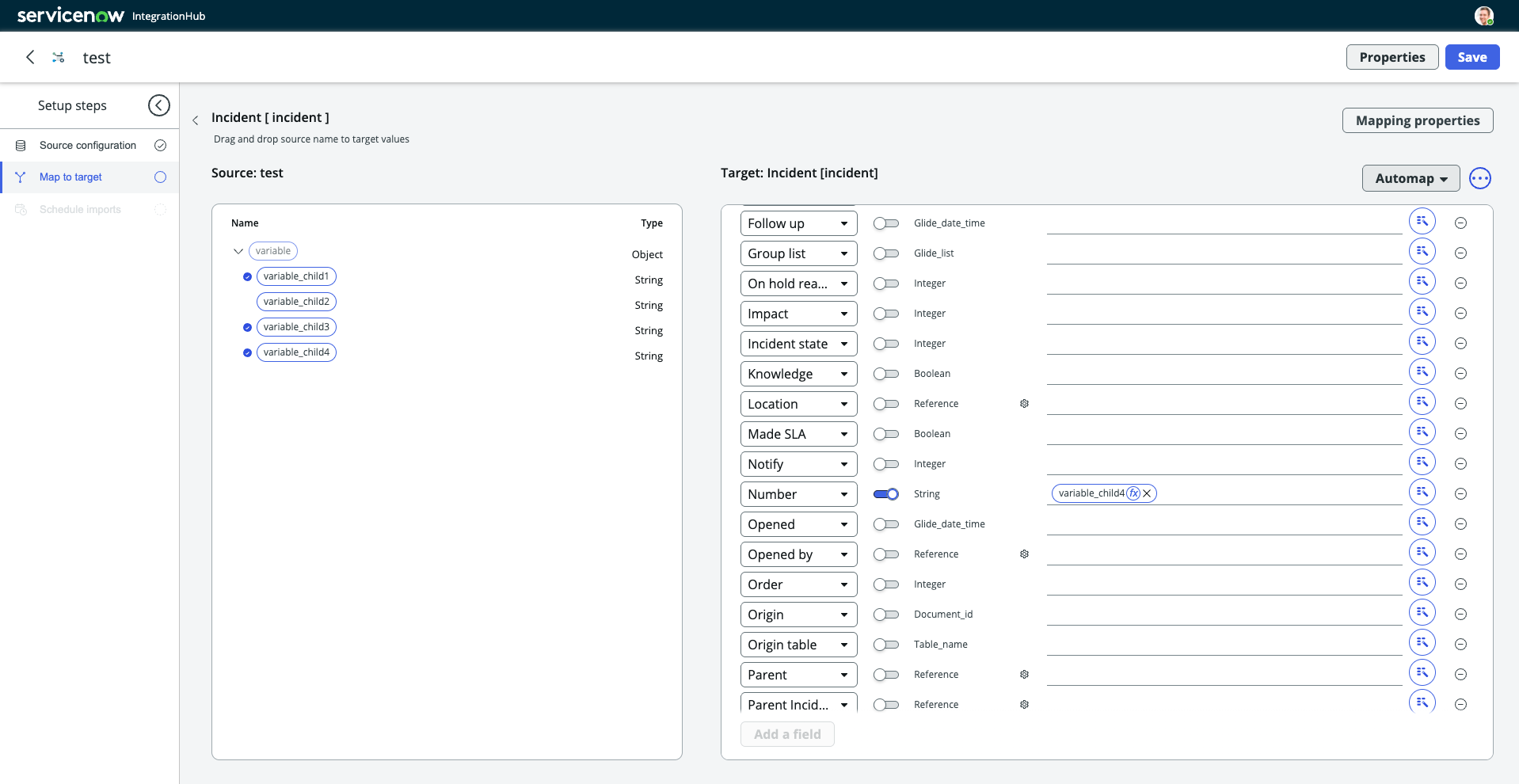
あわせて、マッピング機能についても触れておきます。
IntegrationHub Importのマッピングでは、固定値の付与や文字列の組み立て程度であれば、データピルと文字列を連結するだけで対応できます。単純な補完や整形であれば、スクリプトを書く必要はありません。
一方で、複雑な計算や型変換が必要な場合や、ある特定のデータに対してだけインポートを無視したい場合に、インポート前後に実行される onBefore / onAfter の Business Rule を利用することもできます。ただし、これらは同期処理として実行されるため、件数が多い場合は実行時間への影響に注意が必要です。
公式ドキュメント-変換設定
3. 順序制御
スクリプト実装の場合、複数のBusiness Ruleやカスタムテーブルを用いてインポート処理のトリガー実行をチェーンのようにつなぎ、処理間の依存関係や実行順序を自前で制御する、といった実装パターンが想定されます。
このような構成では管理対象が多く、処理モデルも複雑になりがちなため、運用・開発コストが大きく増加します。加えて、依存関係管理のためにカスタムテーブルを多用するケースもあり、結果としてライセンスコストの増加につながることもあります。
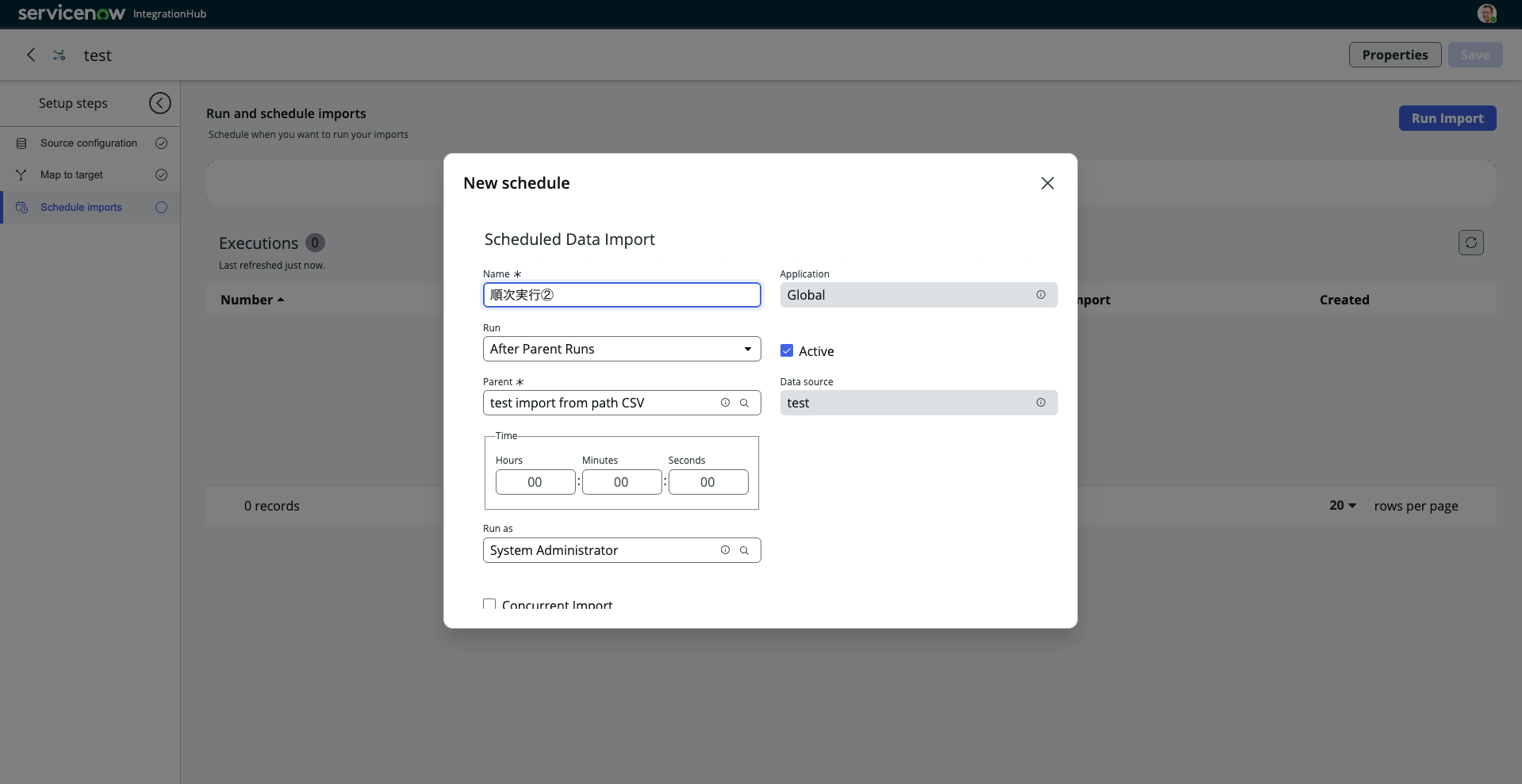
一方、IntegrationHub Importでは、スケジュール設定画面で実行タイミングを「After Parent Runs」に設定し、先行するインポート(親)を選択するだけで、親のインポート処理が完了したタイミングで自動的に後続処理を実行できます。
インポート処理間の順序制御は想像以上に大変なので、開発者的には一番嬉しい機能だと感じています。
▼IntegrationHub Importでのスケジュール設定画面
4. 並列処理
同一階層のテーブル内ではレコード間に処理順序の依存関係がない場合、並列実行によって高速にインポートする選択肢も考えられるでしょう。
IntegrationHub Importでは、このような場合にConcurrent Importのトグルを有効化するだけで、並列処理によるインポートを行うことができます。
▼IntegrationHub Importでのスケジュール設定画面
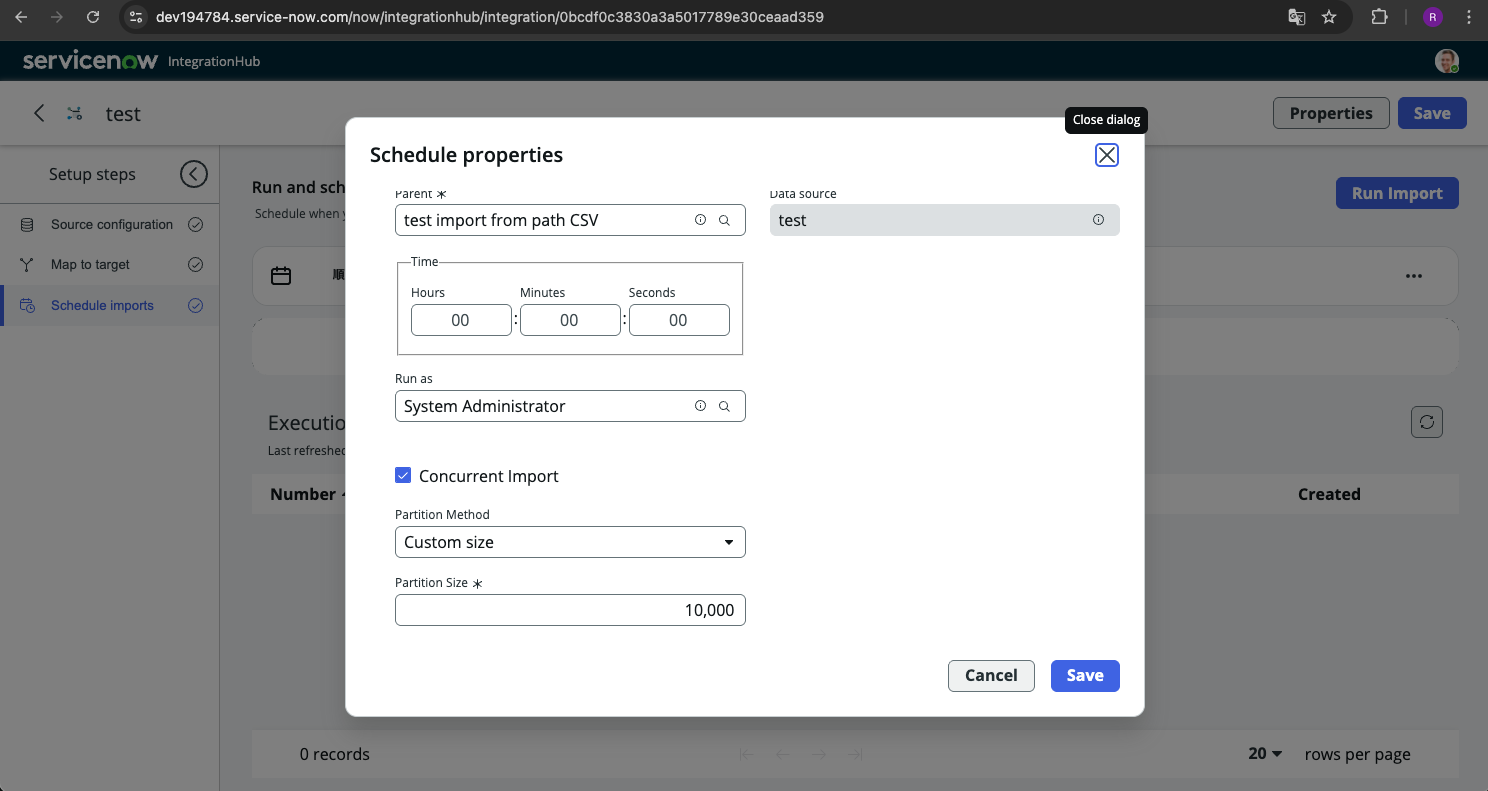
データの分割方法としては、カスタムサイズとラウンドロビンのオプションがあります。公式ドキュメントに細かく書かれてないので確定的なことは言えませんが、おそらく実行ノードにロットで振り分けていくか、1個ずつ順番に振り分けていくかだと思ってます。
また、大量データで試したことがないのですが、デフォルトとしては10ノード(20スレッド)利用出来るとのことで、レイテンシーを加味して10~20倍程度の実行速度の向上が見込めそうです。
5. 実行ボタン
IntegrationHub Importの統合インターフェースでは、スケジューラーで定義したタイミングに実行できるほか、「Run Import」ボタンから任意のタイミングで即時実行もできます。
このため、実行トリガーのためだけにUI Actionやスケジュールジョブを別途用意する必要がなくなります。
▼IntegrationHub Importでのインポート実行画面
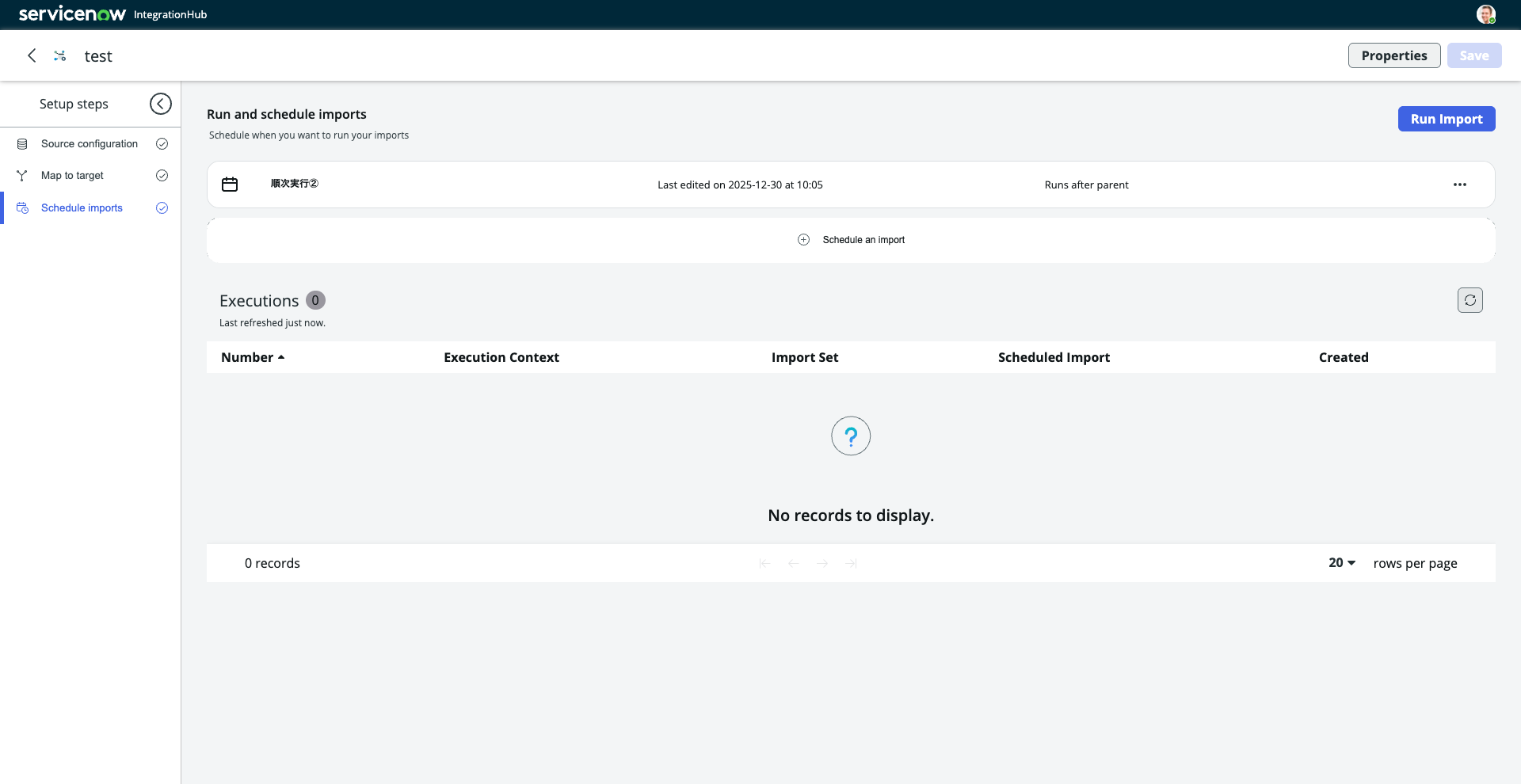
6. 集約された実行結果
最後に、IntegrationHub Importでは実行結果もインポート実行画面の中で簡単に確認することができます。毎回システムログのテーブルを見にいく必要はありません。
▼IntegrationHub Importでのインポート実行画面(Executionリストに実行結果が集約)
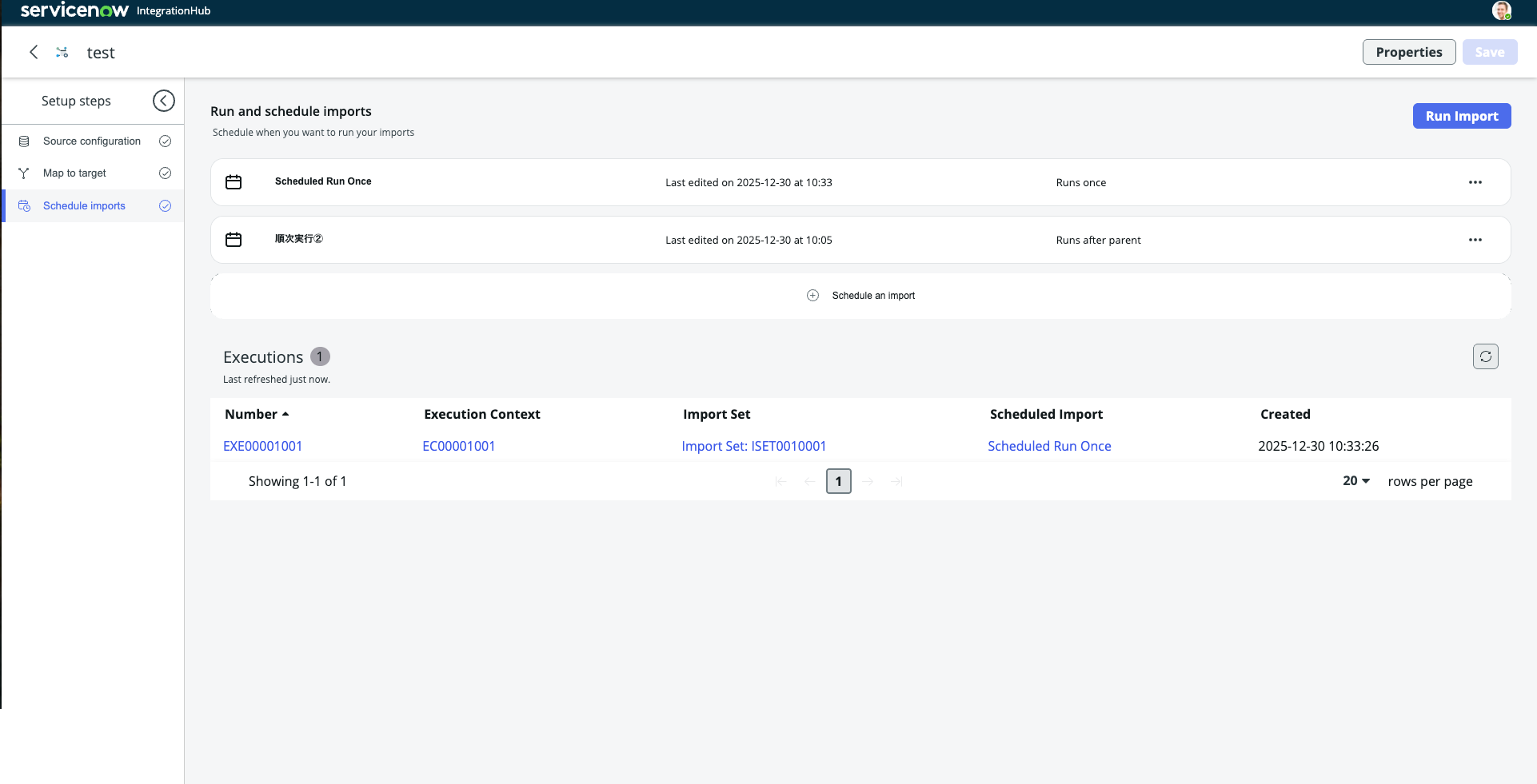
以上、主要な標準機能について個別に紹介させていただきました。
今回私が実務で直面した業務要件と照らし合わせると、以下のようになります。
- 1回のAPI要求に収まらない大量データのインポート $\rightarrow$ 1. ページネーション
- インポートデータの重複が許されない $\rightarrow$ 2. 重複防止
- テーブル間の依存関係によりインポート順序が決まっている $\rightarrow$ 3. 順序制御
- インポート処理実行時間を短縮したい $\rightarrow$ 4. 並列処理
- 手動での月次実行のためボタンが必要 $\rightarrow$ 5. 実行ボタン
- エラー確認用インターフェースが必要 $\rightarrow$ 6. 集約された実行結果
これら全て標準機能によって対応できたという面に加え、UI/UXの面でも優れており、特に画面操作で迷うこともなかったので、要件・設計確定後の実装自体はおおむね1日程度で完了しました。
▼REST Messageとの比較のまとめ(Powered by Nano Banana🍌)
詰まった点
一方で、実装時に一度つまずいた点もあります。
Import時に別テーブルで管理されているコードをもとに検索し、その結果のsys_idを外部参照フィールドに設定するといった処理をそのまま組み込もうとすると、検索処理が重くなり、全体の処理時間に悪影響を及ぼす可能性がありました。
この回避策として、外部キーは一時的に値を保持するためのカラムに格納し、インポート完了後にasync(非同期)のBusiness Ruleで参照・補完処理を行う構成にしました。
この方法では即時反映はされませんが、画面が固まることなく、結果として正確な値を安定して反映させることができました。
▼詰まった点のまとめ(Powered by Nano Banana🍌)
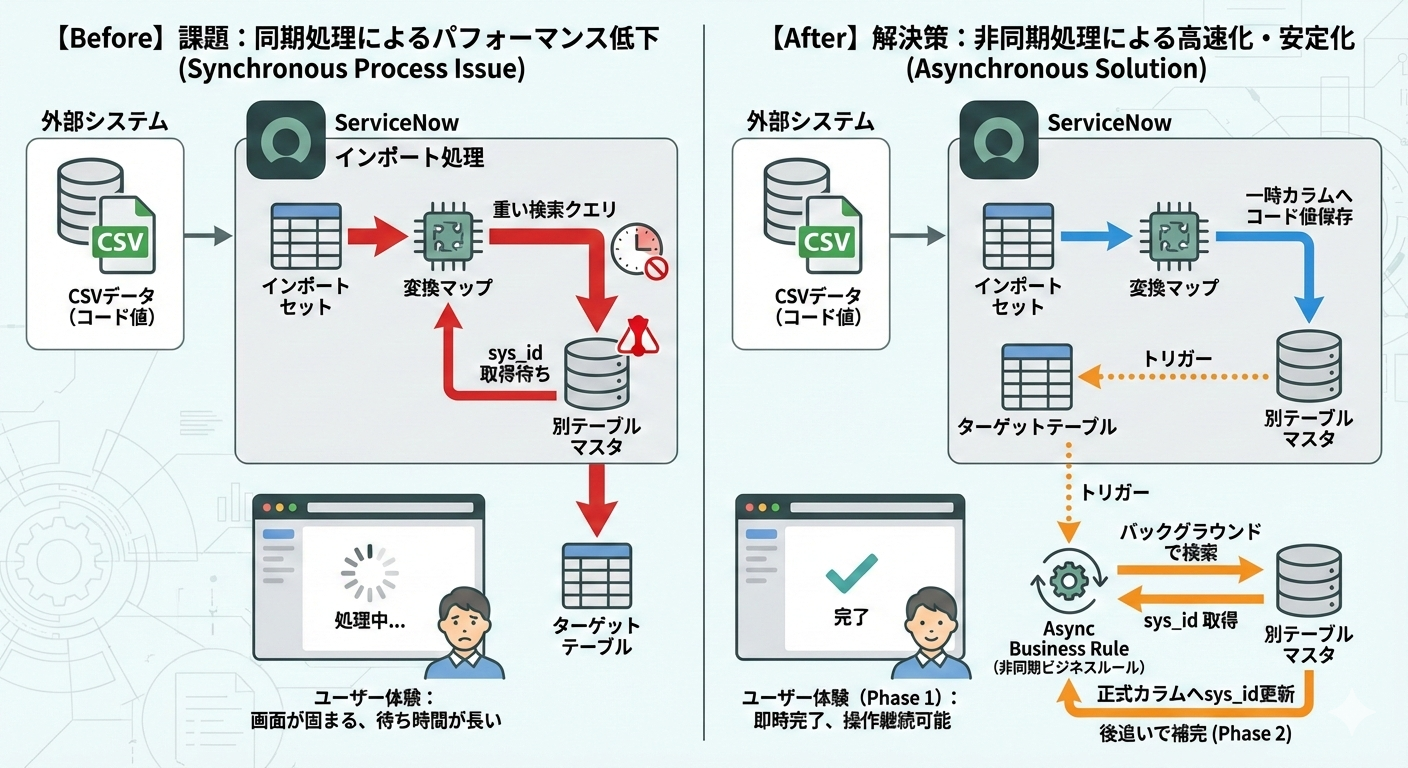
細かいところが若干アレですがニュアンスとしてはこういうことです
まとめ
総評として、ServiceNowへの外部データ連携において開発・運用保守コストを下げたい場合、IntegrationHub Import機能は非常に有力な選択肢になると感じました。
ネガティブな面を強いてあげるとするなら、費用の面はともかくとして、ServiceNow独自の標準機能を学習する必要があるということくらいですが、そんなに覚えることが多いわけでもなく難しいわけでもないので、1週間もあればマスターできると思います。
参考までに、私が本機能を利用するにあたって学習したServiceNow Universityのコンテンツを紹介します。
IntegrationHub 学習コンテンツ(ServiceNow University)
- Integration Hub Fundamentals [日本語]
- Integration Hub: Advanced - Xanadu [日本語]
- Integration Hub: Create Data Stream Actions [日本語]
おわりに
長い記事でしたが、ここまで読んでいただいた方々ありがとうございます。
今日は大晦日ですが、来年もイベント等でお会いすることがあればどうぞよろしくお願いします。
それでは、よいお年を〜!