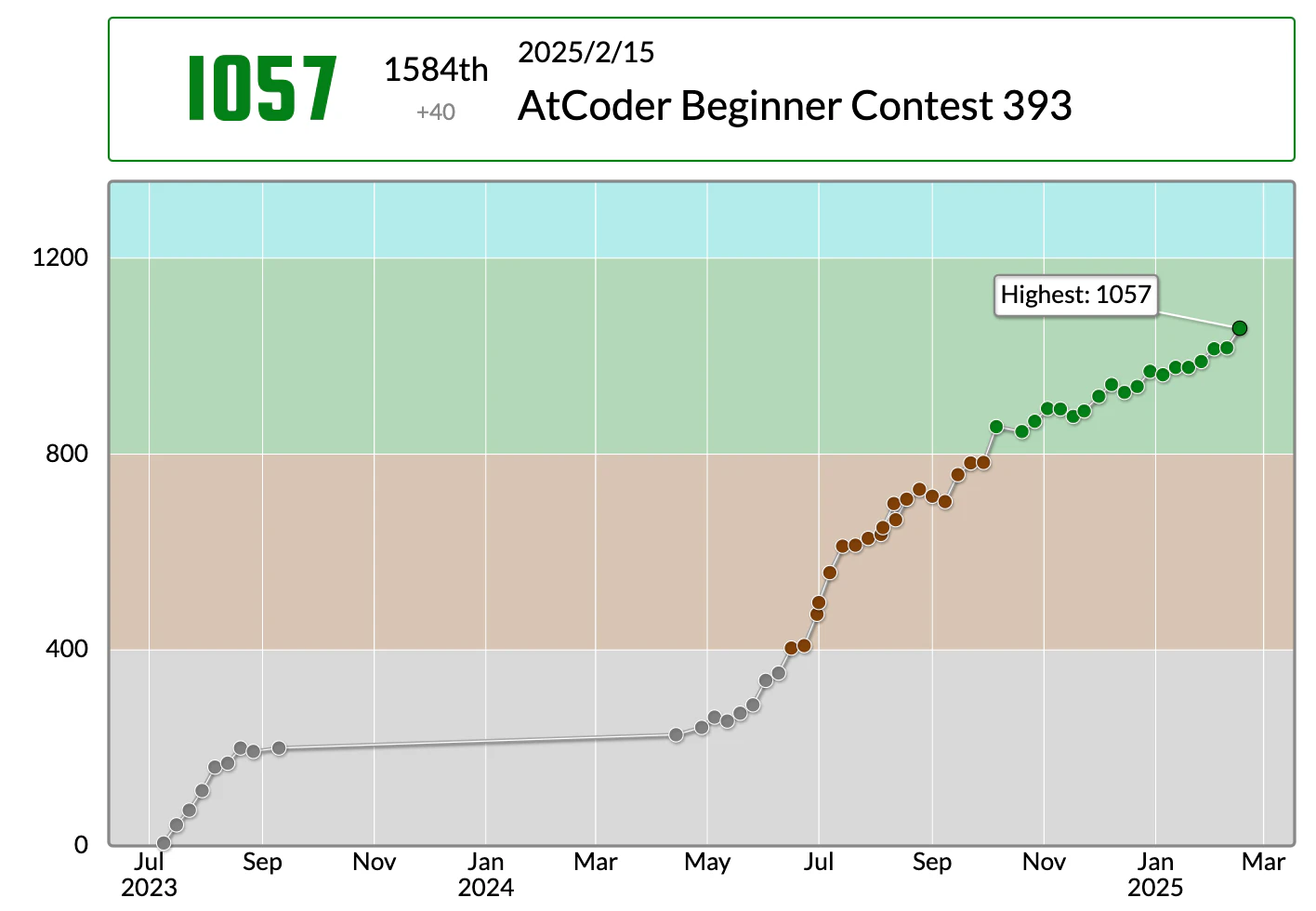
AtCoder Beginner Contest 393
ABCDFの5完(68分0ペナ)でした。
1362perfでレートは1017->1057(+40)となりました。
E問題はGCDや約数列挙に苦手意識があり問題文を読んで1分で飛ばしF問題に取り組みました。
F問題はクエリの問題で、セグ木やイベントソートについては自信があったので考えていった結果、以前鉄則本でやったことのある二分探索でのLISをクエリ先読みした上でやるだけだと気づくことができ、なんとACしてしまいました。レート盛り盛りで嬉しいです。
というわけで今回はA~Fをまとめます。
A - Poisonous Oyster
以下の表に従って場合分けをして出力しましょう。
| $S1 \backslash S2$ | sick |
fine |
|---|---|---|
sick |
$1$ | $2$ |
fine |
$3$ | $4$ |
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const s = input[0].split(" ");
if (s[0] === s[1] && s[0] == "sick") console.log("1");
else if (s[0] === s[1] && s[0] == "fine") console.log("4");
else if (s[0] === "sick") console.log("2");
else if (s[1] === "sick") console.log("3");
}
Main(require("fs").readFileSync(0, "utf8"));
B - A..B..C
A,B,Cが等間隔に並んだ箇所のパターンは、初項の位置と隣接項の距離によって一意に決まります。これを全探索すると$O(|S|^2)$となりますが、本問題では$|S|≦100$であるため十分に間に合います。
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const S = input[0];
let ans = 0;
// Aの位置と、A-B, B-Cの間隔によって組み合わせは一意に決まる
for (let i = 0; i < S.length; i++) {
if (S[i] !== "A") continue;
for (let len = 1; len <= S.length - i; len++) {
if (S[i + len] == "B" && S[i + len * 2] == "C") ans++;
}
}
console.log(ans);
}
Main(require("fs").readFileSync(0, "utf8"));
C - Make it Simple
辺を最初から順番に見ていき、同一の辺または自己ループを除いた辺の個数を調べましょう。
具体的には、unordered_setなどを利用して、自己ループではない互いに異なる辺のみを数えるようにします。
例えば、$[1,3]$という辺があったとすると、$[1,1]$(自己ループ)や$[3,1]$、$[1,3]$(同一の辺)は追加しないようにします。
その上で、最後に元々あった辺全体から、自己ループではないユニークな辺の個数を引くことにより、求められた答えが導出できました。
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const [N, M] = input[0].split(" ").map(Number);
const [u, v] = [[], []];
for (let i = 0; i < M; i++) [u[i], v[i]] = input[i + 1].split(" ").map(Number);
let ans = new Set();
for (let i = 0; i < M; i++) {
[u[i], v[i]] = [u[i] - 1, v[i] - 1];
if (u[i] > v[i]) [u[i], v[i]] = [v[i], u[i]];
// 自己ループ、またはすでにカウント済みの辺は無効としてスキップ
if (u[i] == v[i] || ans.has(`${u[i]} ${v[i]}`)) continue;
ans.add(`${u[i]} ${v[i]}`);
}
// 辺全体から有効な辺の数を引く
console.log(M - ans.size);
}
Main(require("fs").readFileSync(0, "utf8"));
D - Swap to Gather
「マンハッタン距離の総和を最小化するときは中央値を利用する」方法、「Slope Trickというデータ構造を利用する」方法もありますが、本記事では累積和を利用した解法を説明します。
配列$lcost$を「今いる場所より左の1を全て、今いる場所に寄せた時のコスト」、配列$rcost$を「今いる場所より右の1を全て、今いる場所に寄せた時のコスト」のように定義します。
もしこの配列を定義できれば、あとは$lcost+rcost$が最小となる場所を探せば良いだけです。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| $S$ | 0 |
1 |
0 |
1 |
0 |
0 |
1 |
| $lcost$ | - | 0 |
- | 1 |
- | - | 5 |
| $rcost$ | - | 4 |
- | 2 |
- | - | 0 |
| $lcost+rcost$ | - | 5 |
- | 3 |
- | - | 5 |
では、$lcost$と$rcost$の構築方法を考えましょう。
上の図をしっかりと観察してみましょう。
例えば、4→5に進んだ時、$S_2$と$S_4$の1はどちらも相対的に$1$ずつ遠くなるため、$lcost$は$2$だけ増加します。
ここで、次に移動する位置の文字が0のとき、蓄積するコストはこれまで見て来た1の個数だという予想が立ちます。証明は省略しますが、実際にこれに論理的な矛盾はなく、正しいことがわかります。
そして、次に移動する位置の文字が1のとき、これまで見て来た1を動かすコストは変わりません。
したがって、この場合は蓄積したコストを$lcost$に足すだけで問題ありません。
あとは、以上の考察を実装に落とし込むだけで良いのですが、累積コスト変数や両側から走査するのを正確に実装するのは少し厄介です。
左側から走査しても、右側から走査してもやることは基本的には変わらないので、このような場合は処理を共通化したメソッドを作るのが良いです。
ACコードの例では、第二変数に左側からの走査なのか、右側からの走査なのかをboolで受け取れるようにしています。添字管理に注意してください。
以上で、この問題を$O(N)$で解くことができました。
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const N = Number(input[0]);
const S = input[1].split("").map(Number);
// sum: 1の個数の累積和
const sum = Array(N + 1).fill(0);
for (let i = 0; i < N; i++) sum[i + 1] = sum[i] + (S[i] === 1 ? 1 : 0);
// getCostArray: 1が書かれた点ごとに、そこに左の1を寄せた時のコストを求める。
// 右側の1を寄せる場合は、rev = trueを指定すると取り出せるようにする
const getCostArray = (S, rev) => {
let new_S = rev ? [...S].reverse() : [...S];
let res = [];
for (let i = 0; i < N; i++) {
if (new_S[i] === 1) {
// 寄せるコストの差分更新。前回1があった場所からの距離 * 1の数のぶんだけ増加する
let [prev_cost, prev_i] = res.at(-1) || [0, i - 1];
let ones = rev ? sum[N] - sum[N - i] : sum[i];
res.push([prev_cost + ones * (i - prev_i - 1), i]);
}
}
// インデックスはコスト計算のみに用いるため、除去してコストだけを返す
res = res.map((v, i) => v[0]);
return rev ? res.reverse() : res;
};
// ある位置について、左側の1を寄せるコスト(lcost)と右側の1を寄せるコスト(rcost)の和の最小を求める
let lcost = getCostArray(S, false);
let rcost = getCostArray(S, true);
console.log(Math.min(...lcost.map((v, i) => v + rcost[i])));
}
Main(require("fs").readFileSync(0, "utf8"));
E - GCD of Subset
この問題は約数ゼータ変換という典型で処理することができます。
$f(d)$を「配列$A$の中で$d$を約数にもつ要素の個数」と定義します。
$\text{max}(A)$までの$f(d)$がわかっている場合、任意の$i$について $f(d)≧K$を満たす、$A_i$の約数$d$のうち最大の値$F(A_i)$は簡単に求めることができます。
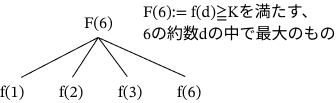
これだけでは何を言っているかわからないと思うので、上の図をみてください。
例えば、$K=2,A=[1,3,4,6]$とします。このとき、$f(1)=4,f(2)=2,f(3)=2,f(4)=1,f(6)=1$です。
ここで$4$番目の解$F(6)$について考えてみましょう。$6$の約数は$1,2,3,6$ですが、前述の$f(d)$の計算結果により、$f(d)≧2$を満たす最大の$6$の約数$d$は$3$であることがわかります。よって、$F(6)=3$です。
このように、$x$の全ての約数$d$についての基底関数$f(d)$を利用して、何らかの規則に従って累積関数$F(x)$を求める処理を約数ゼータ変換といいます。
これを、全ての$A_i$について行います。
愚直に約数全列挙で行うことができれば簡単なのですが、$N,K≦1.2×10^6$と大きいので高速化の方法を考えないとこの問題に正解することはできません。
(C++の場合は限界まで定数倍高速化することにより通るらしいのですが、JavaScriptやPythonだと厳しいと思います。)
したがって、「1. $f(d)$の導出」と「2. $F(x)$の導出」の2ステップに分けて、具体的な高速化手法を考えていきます。
1. f(d)の導出
まず最も愚直な方法として、$A_i$が与えられた時に都度試し割り法で約数を列挙する方法が考えられます。しかし、$M =\text{max}(A)$とすると、計算量は$O(N\sqrt{M})$となり、$N≦1.2×10^6$かつ$M≦10^6$より容易にTLEすることが予想されます。
そこで、第二の方法としてはエラトステネスの篩を利用する方法が考えられます。
| $d$ | 1 | 2 | 3 | 4 | 5 | 6 | $f(d)$ | $A$のうち$d$を約数にもつ要素 |
|---|---|---|---|---|---|---|---|---|
| 1 | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | 4 | $1,3,4,6$ |
| 2 | ⚪︎ | ⚪︎ | ⚪︎ | 2 | $4,6$ | |||
| 3 | ⚪︎ | ⚪︎ | 2 | $3,6$ | ||||
| 4 | ⚪︎ | 1 | $4$ | |||||
| 5 | ⚪︎ | 0 | ||||||
| 6 | ⚪︎ | 1 | $6$ |
上の具体例($A=[1,3,4,6]$のケース)を見てください。$d=1,...,M$について、$d, 2d,3d,...,kd(k≦M/d)$と表せる要素がいくつあるかを調べています。
仮に$A$に重複があったとしても、事前に$N$回のループで、ある数$d$が何回現れたかを表す配列$\text{freq}[d]$が求められていれば、$f(d) = \sum_{k=1}^{\lfloor M/d \rfloor} \text{freq}[kd]$として$f(d)$を求めることができます。
各$d$のループ回数は$M/d$であるため、全体のループ回数は$M/1+M/2+…+M/M$であり、これは調和級数であるため計算量を$O(MlogM)$で上から抑えることができます。
以上で、$1$から$M$までの$f(d)$をくまなく高速に求めることができました。
2. F(x)の導出
$1$から$M$までの$d$について$f(d)$が求められたので、次に$N$行に渡り$F(A_i)$を高速に求めることを考えます。
任意の$A_i$が与えられた時に、即座に昇順ソートされた約数配列にアクセスできれば良いのですが、あいにく$f(d)$の導出時にそれを構築していないため叶いません。(ステップ1で$O(MlogM)$で約数全列挙しておくことは可能ではありますが、配列に要素を格納する処理が遅いのでTLEする可能性が高いです。なお、C++のような高速な言語だとこれでもACできるようです)
そこで、ここでもエラトステネスの篩を使って$d$の$1$から$M$まで順に$f(d)$を問い合わせ、$f(d)≧K$であれば$F(x)$を更新します。
これも図を見た方がわかりやすいでしょう。$K=2,A=[1,3,4,6]$のケースでは$F(6)$は以下のように遷移します。
| $d$ | 1 | 2 | 3 | 4 | 5 | 6 | $f(d)$ | $F(6)$ |
|---|---|---|---|---|---|---|---|---|
| 1 | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | ⚪︎ | 4 | 1 |
| 2 | ⚪︎ | ⚪︎ | ⚪︎ | 2 | 2 | |||
| 3 | ⚪︎ | ⚪︎ | 2 | 3 | ||||
| 4 | ⚪︎ | 1 | 3 | |||||
| 5 | ⚪︎ | 0 | 3 | |||||
| 6 | ⚪︎ | 1 | 3 |
- $d=1$について、$6d=6$かつ$f(1)=4≧2$より、$F(6)=1$
- $d=2$について、$3d=6$かつ$f(2)=2≧2$より、$F(6)=2$
- $d=3$について、$2d=6$かつ$f(3)=2≧2$より、$F(6)=3$
- $d=4,5$については$kd=6$となるような整数$k$が存在しないのでスキップ
- $d=6$について、$1d=6$であるが、$f(6)=1<2$のためスキップ
以上より、$F(6)=3$であるとわかりました。
このようにすることで、$1$から$M$までの任意の$x$について、$F(x)$を$O(MlogM)$で求めることができます。
$1$から$M$までの任意の$x$について、$F(x)$がわかったので、あとは$N$行にわたって$F(A_i)$を出力すれば良いのですが、実はここにも大きな落とし穴があり、$N$が非常に大きいため、$N$回console.logをしてしまうと標準入出力のI/O操作がボトルネックとなり、なんとそれまでのアルゴリズムが正しくてもTLEしていまいます。
これを回避するためには、解答を配列に格納しconsole(ans.join(“\n”))のようにjoin関数で文字列結合するなどしてconsole.logの回数を$1$回に抑える必要があります。
ここまで非常に長い道のりでしたが、以上で全体計算量が$O(MlogM+N)$となり、この制約下で十分高速にこの問題を解くことができました。
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const [N, K] = input[0].split(" ").map(Number);
const A = input[1].split(" ").map(Number);
const max = Math.max(...A) + 1;
// freq[i]:= iの出現頻度
const freq = new Array(max).fill(0);
for (let i = 0; i < N; i++) freq[A[i]]++;
// f[i]:= 配列Aのうち、iを約数に持つ数の個数を表す基底関数
const f = new Array(max).fill(0);
for (let i = 1; i < max; i++) {
for (let j = i; j < max; j += i) f[i] += freq[j];
}
// g[i]:= f[j]≧Kを満たす、iの約数jのうち最大のものを表す累積関数
const g = Array(max).fill(1);
for (let i = 2; i < max; i++) {
if (f[i] < K) continue;
for (let j = i; j < max; j += i) g[j] = i;
}
// N行console.logするとN回I/O操作が発生するため非常に遅くなるので注意
const ans = [];
for (let i = 0; i < N; i++) ans.push(g[A[i]]);
console.log(ans.join("\n"));
}
Main(require("fs").readFileSync(0, "utf8"));
余談ですが、これは本当に1200 diffなのでしょうか?数学的にも、実装的にも難しいポイントがかなり多いと感じました。
問題としては、約数ゼータ変換を納得いくまで理解することができたので、非常に素晴らしい問題だと思いました。
この典型を使えば、$M$を上限とする任意の整数$n$について、色々な約数関数$\sigma_k(n)$を$O(MlogM)$で評価できます。興味がある方は、約数の二乗の和や、逆数和などを自分で計算してみると面白いかもしれません。
F - Prefix LIS Query
F問題はLISを知っているか知らないかで難易度が大きく変わってくるため、LISを知らない人はまずLISを学習してください。参考
最初に種明かしをすると、クエリ先読みをすることによって、$R$の小さい順にイベントソートして、$R_1≦R_2≦…≦R_Q$のような順番にクエリを入れ替えておきます。
このようにすると、$1$から$R_i$までのプレフィックスでLISを構築した後に、構築したLISを$1$から$R_{i+1}$までのLISを求める際に使いまわすことができるようになります。
LISの構築方法は、私は二分探索で構築しましたが、多分セグ木でも構わないと思います。
以上で、$O((N+Q)logN)$でこの問題を解くことができました。
function Main(input) {
input = input.split("\n").map((line) => line.trim());
const [N, Q] = input[0].split(" ").map(Number);
const A = input[1].split(" ").map(Number);
const [R, X] = [[], []];
const query = [];
for (let i = 0; i < Q; i++) {
[R[i], X[i]] = input[i + 2].split(" ").map(Number);
query.push([R[i], X[i], i]);
}
// クエリをRでソートしておくことで、Rを進めながら都度都度クエリに答えることができるようにする
query.sort((a, b) => a[0] - b[0]);
const ans = Array(Q).fill(0);
// L[i]:= 長さi+1の増加部分列の最後の要素の最小値
const L = [];
let pos = 0;
for (let i = 0; i < N; i++) {
// Lが空の場合は、A[i]が長さ1の増加部分列の最後の要素となるのでそのまま追加
if (L.length === 0) L.push(A[i]);
else {
// A[i]の挿入(置換)位置を二分探索で求める
let pos = lower_bound(L, A[i]);
if (pos === L.length) L.push(A[i]);
else L[pos] = A[i];
}
// 次のRまで、尺取法の要領でクエリを進め、都度都度クエリに答える
while (pos < Q && query[pos][0] <= i + 1) {
const [r, x, idx] = query[pos];
let res = lower_bound(L, x + 1);
ans[idx] = res;
pos++;
}
}
console.log(ans.join("\n"));
}
const isOK = (arr, mid, key) => arr[mid] >= key;
const lower_bound = (arr, key) => {
let ng = -1; //「index = 0」が条件を満たすこともあるので、初期値は -1
let ok = arr.length; // 「index = a.size()-1」が条件を満たさないこともあるので、初期値は a.size()
while (ok - ng > 1) {
let mid = Math.floor((ok + ng) / 2);
if (isOK(arr, mid, key)) ok = mid;
else ng = mid;
}
return ok;
};
Main(require("fs").readFileSync(0, "utf8"));
記事執筆までかなり時間が空いてしまいすみません。
E問題が難しすぎて、約数まわりやゼータ・メビウス変換の内容理解、ライブラリ整理を納得いくまで行っていました。
さて、レートの方は躍進中で、もしかしたら5月くらいには入水できるかもしれない程度の期待感が持てるようになりました。
引き続き、コンテストの参加と記事の執筆を頑張ってまいりますので、皆様も是非一緒に頑張りましょう。