概要
ジェスチャ認識をするための記録です。
一番認識したかったボディービルのポーズを認識しました。
手認識が実用レベルに到達した件を読んで、Move Mirrorについての記事を参考に実装を行いました。
posenet-pythonにコードを追加する形でジェスチャ認識を行っています。
試してくださる方はposenet-pythonをダウンロードして、フォルダ上に私の書いたファイルを移動お願いします(詳しくはGithubを参照してください)。
記事で参考にした部分を解説したいと思います。
環境
OS X: 10.15.1
Python: 3.7.5
※ posenet-pythonを使うために必要なライブラリがいくつかあります。
詳しくはposenet-pythonのreadmeをみていただくのが良いですが、私の環境でversionを変更した2つを記しておきます。
Tensorflow 1.13.1(2系だとエラーを吐きます)
opencv-python 3.4.5.20(4系だとエラーを吐きます)
できたもの

指定ファイルの中に入れた好きな画像のなかで最も近いフォルダ名を出力する仕様になっています。
PoseNetについて
PoseNetでは17点のキーポイントと呼ばれるパーツの座標(x,y)とその点の信頼度のスコア、そして全体の信頼度のスコアが返ってきます。
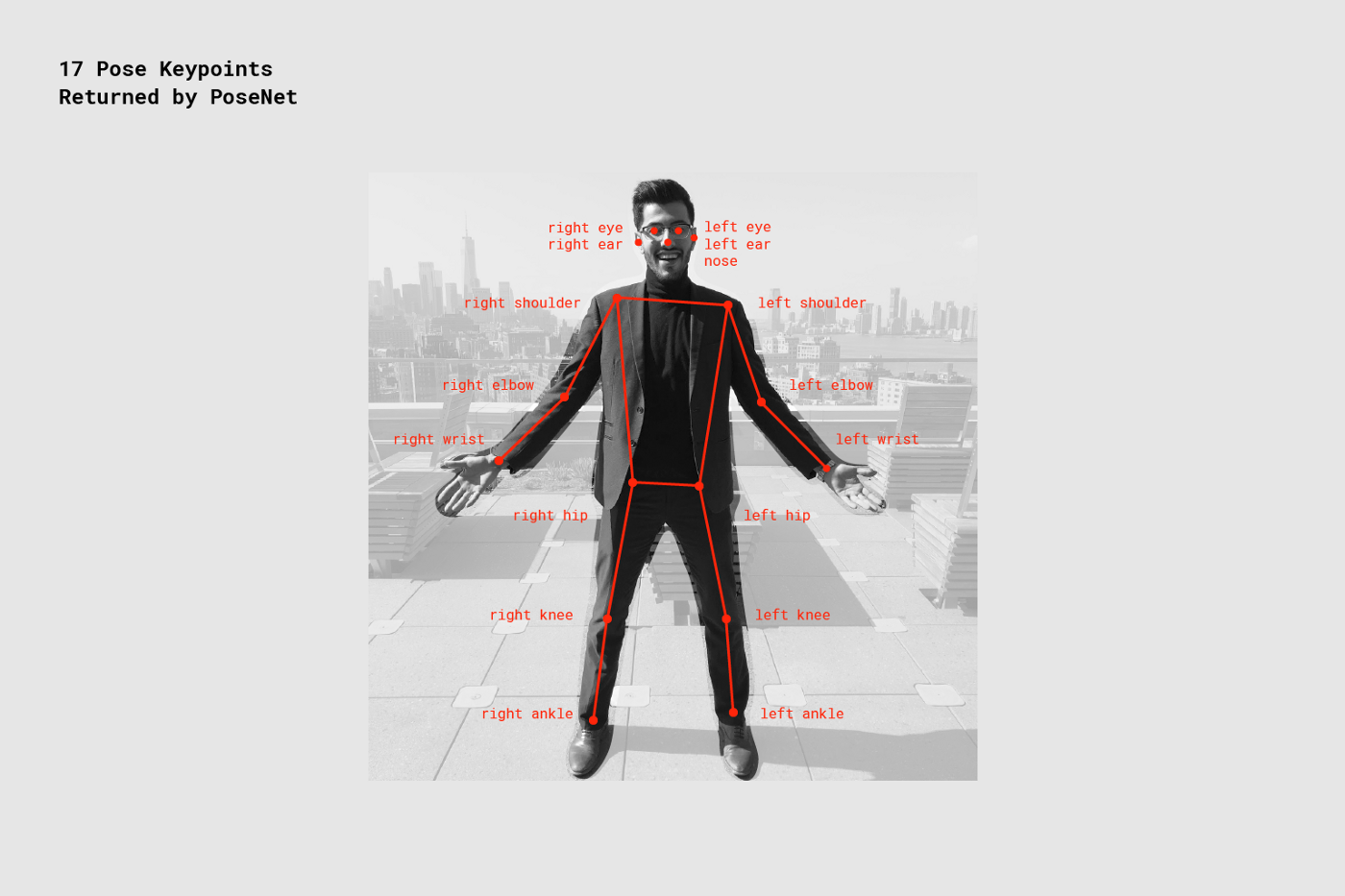
(参照 https://medium.com/tensorflow/move-mirror-an-ai-experiment-with-pose-estimation-in-the-browser-using-tensorflow-js-2f7b769f9b23)
今回はこの情報を使って、ジェスチャ間の距離を測っていきます。
クリッピングと正規化(normalization)
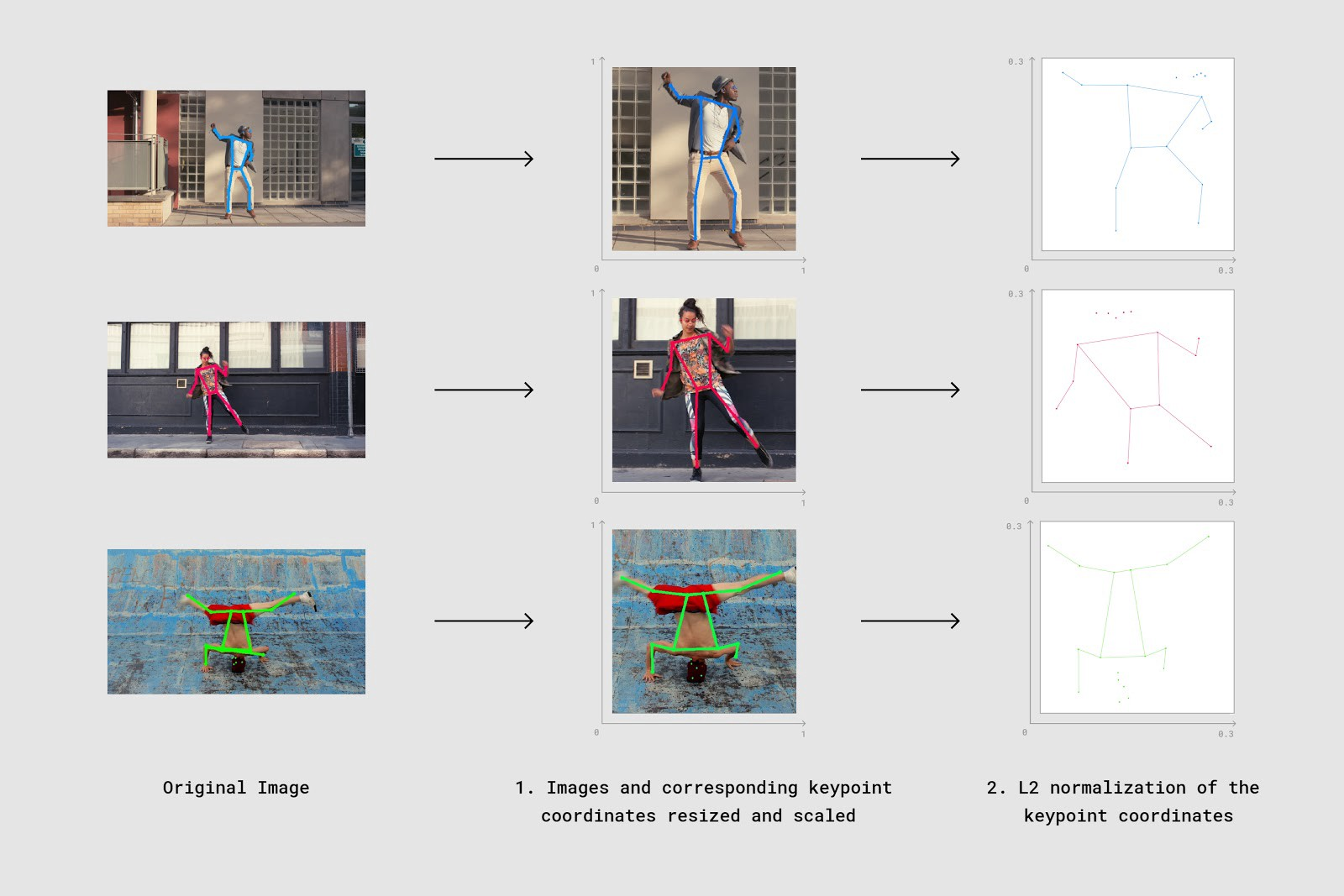
動画や画像のサイズに影響を受けたり、認識したい人がいる位置の影響を軽減するために、クリッピングと正規化を行います。
クリッピング
上記の画像は大変分かりやすいですが、今回の実装ではざっくりクリッピングを行いました。
17点のキーポイントのうちでもっと小さなx座標を持つ点のx座標をx=0に、もっと小さなy座標を持つ点のy座標をx=0にしました。
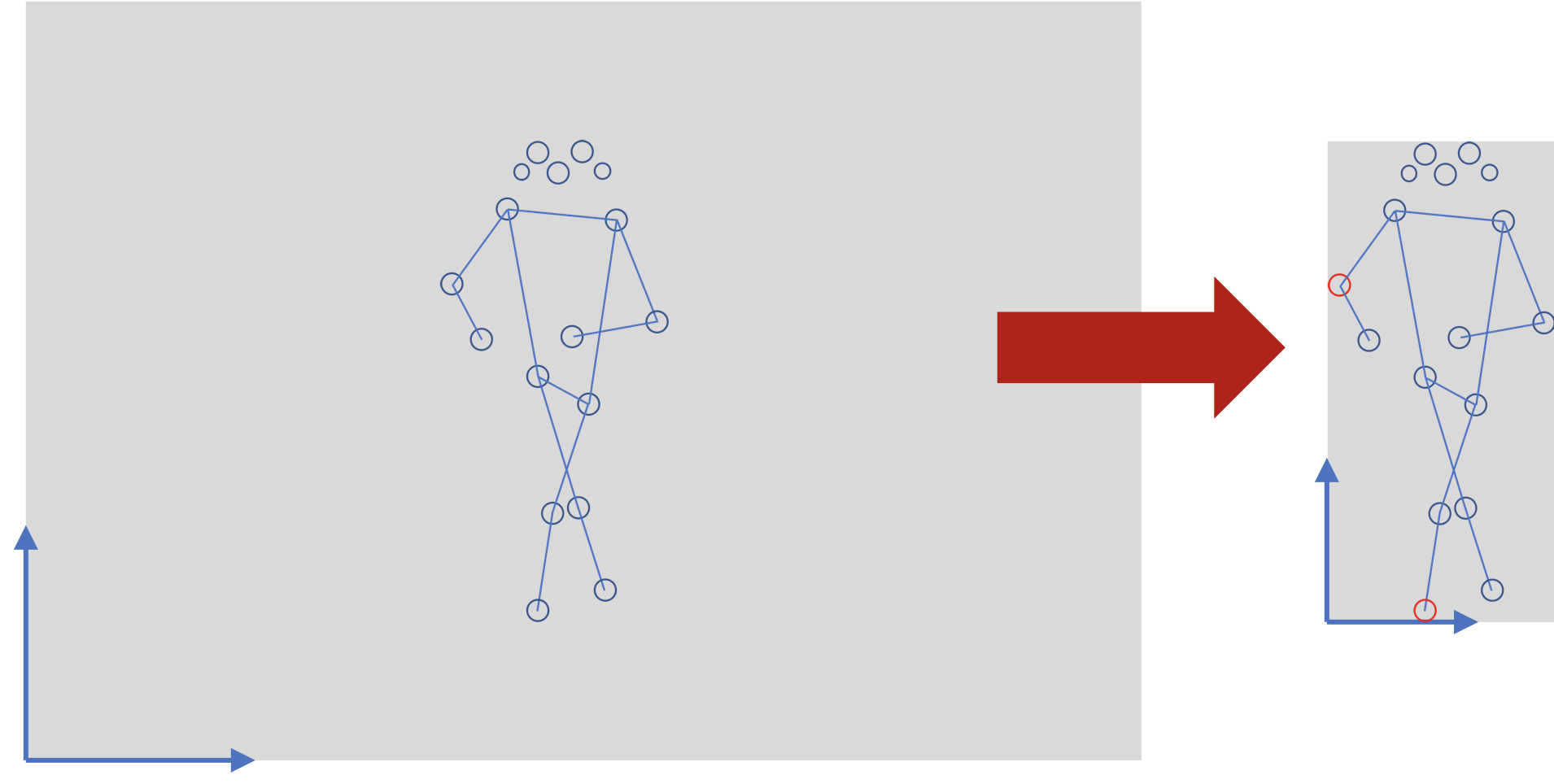
コードだとこんな感じです。
# clip
keypoint_coords[0,:,0] = keypoint_coords[0,:,0] - min(keypoint_coords[0,:,0])
keypoint_coords[0,:,1] = keypoint_coords[0,:,1] - min(keypoint_coords[0,:,1])
L2 正規化(normalization)
正則化(regulation)じゃないので注意してください。
numpyのライブラリを使って、各座標軸ごとに正規化を行いました。
参考 https://qiita.com/panda531/items/4ca6f7e078b749cf75e8
# normalization
x_l2_norm = np.linalg.norm(keypoint_coords[0,:,0],ord=2)
pose_coords_x = (keypoint_coords[0,:,0] / x_l2_norm)
y_l2_norm = np.linalg.norm(keypoint_coords[0,:,1],ord=2)
pose_coords_y = (keypoint_coords[0,:,1] / y_l2_norm)
距離の計算
コサイン類似度で元々は近さをみていたようですが、信頼度を考慮した以下の式を使っているみたいです。
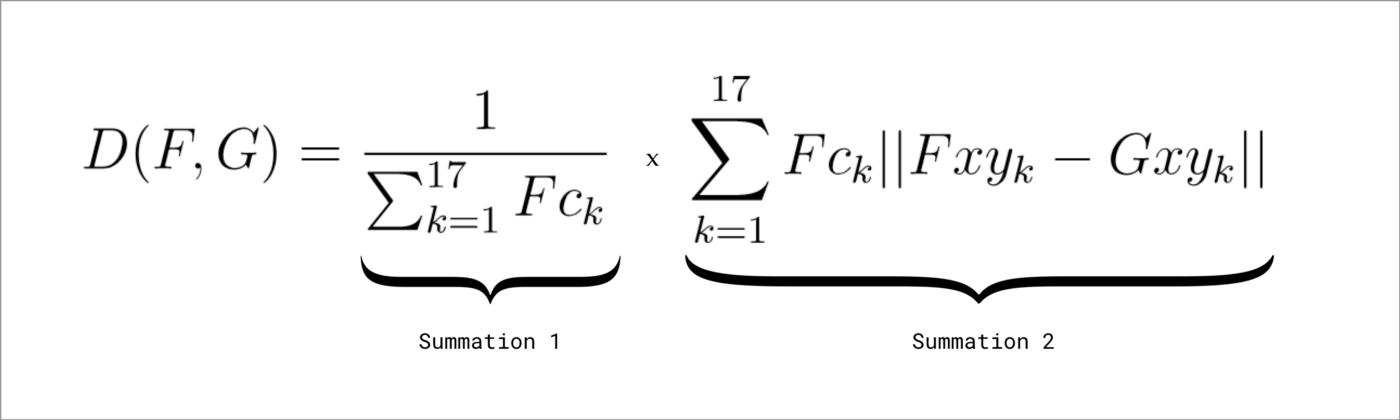
FとGは、L2正規化後の2つのポーズベクトルです。Fckは、Fのk番目のキーポイントの信頼スコアです。FxyとGxyは、各ベクトルのk番目のキーポイントのx位置とy位置を表します。
記事の中にある理解を助けるためのjsのコードです。
// poseVector1 and poseVector2 are 52-float vectors composed of:
// Values 0-33: are x,y coordinates for 17 body parts in alphabetical order
// Values 34-51: are confidence values for each of the 17 body parts in alphabetical order
// Value 51: A sum of all the confidence values
// Again the lower the number, the closer the distance
function weightedDistanceMatching(poseVector1, poseVector2) {
let vector1PoseXY = poseVector1.slice(0, 34);
let vector1Confidences = poseVector1.slice(34, 51);
let vector1ConfidenceSum = poseVector1.slice(51, 52);
let vector2PoseXY = poseVector2.slice(0, 34);
// First summation
let summation1 = 1 / vector1ConfidenceSum;
// Second summation
let summation2 = 0;
for (let i = 0; i < vector1PoseXY.length; i++) {
let tempConf = Math.floor(i / 2);
let tempSum = vector1Confidences[tempConf] * Math.abs(vector1PoseXY[i] - vector2PoseXY[i]);
summation2 = summation2 + tempSum;
}
return summation1 * summation2;
}
私が書いたpythonのコードです。
クリップして、正規化したベクトルを引数として与えることで近さを計算します。
def weightedDistanceMatching(poseVector1_x, poseVector1_y, vector1Confidences, vector1ConfidenceSum, poseVector2):
# First summation
summation1 = 1.0 / vector1ConfidenceSum
# Second summation
summation2 = 0
for indent_num in range(len(poseVector1_x)):
tempSum = vector1Confidences[indent_num] * ( abs(poseVector1_x[indent_num] - poseVector2[indent_num]) + abs(poseVector1_y[indent_num] - poseVector2[indent_num + len(poseVector1_x)]))
summation2 = summation2 + tempSum
return summation1 * summation2
Gifや動画はないですが、コサイン類似度でジェスチャ認識も行ってみましたが、あまり精度が高くないように感じました。
マッチング
本家はVP木を使っています。が、私はVP木を知りませんでした。
VP木はKD木に似ているらしいので、私はこのスライドでKD木を勉強した後に、記事中に出てきたサイトと英語のwikiで勉強しました。
今回は対象とする画像の枚数が6枚くらいだったので、ブルートフォース探索(全探索)しました。
pythonはVP木のライブラリもあるので、興味がある方は是非試してみてください。
※ 上記の関数は引数にとるvectorの順序に依存しているので、修正をかける必要があります。
まとめ
posenet-pythonを使ってジェスチャの認識をしました。
シンプルな理論で比較を行っているので、今後はモバイルアプリでも作ってみたいなーと思います。
ただ、相対的な距離で選択を行っているため、データ数をかなり増やすかニュートラル(何もしていない時)の画像を入れるかしない限りはジェスチャが振り分けられてしまうため、考慮が必要だと感じました。
また、近いポーズの認識はかなり厳しいなと感じました。
平滑化フィルターをかけたり、ラベル用の画像を増やすことで精度をあげるのも面白いかもしれません。
Github