はじめに
不動産情報サイトにおいて、Google Cloud を用いてリアルタイムデータ分析基盤を(部分的に: 詳細は後述)構築したので、その詳細を紹介します。
構築目的
不動産情報サイトでのデータ活用
不動産情報サイトでは、ほとんどのユーザは初回訪問でコンバージョン(Web での問い合わせ等)します。
そのためセッション内での訴求が必要となり、行動ログ等のユーザデータをリアルタイムで取得、さらにセッション内の行動を計測できるようにすることが望まれます。
Google アナリティクスの代替
今回の対象サイトでは、ユーザ行動ログを取得するため Google アナリティクス(GA)を使用しています。
しかし、ユニバーサルアナリティクス(UA)から Google アナリティクス 4(GA4)への移行に伴い以下の理由から、自社で行動ログを取得/分析するシステムを構築しました。
-
BigQuery Export 機能を使っているが、エクスポートされるタイミングが遅くなる
-
UAでは平均で翌日午前6:00にはエクスポートが完了しているが、GA4では午後になる場合が多い
UA のデータが平均で何時にエクスポートされたかを算出$ bq query --nouse_legacy_sql ' SELECT AVG( TIMESTAMP_DIFF( TIMESTAMP_MILLIS(creation_time), PARSE_TIMESTAMP("%Y%m%d", SPLIT(table_id, "_")[OFFSET(2)], "Asia/Tokyo"), HOUR ) - 24 ) AS creation_hour_avg, FROM `<project>.<dataset>.__TABLES__` WHERE table_id LIKE "ga_sessions_%" ;' +-------------------+ | creation_hour_avg | +-------------------+ | 5.854503464203237 | +-------------------+GA4 のデータが平均で何時にエクスポートされたかを算出$ bq query --nouse_legacy_sql ' SELECT AVG( TIMESTAMP_DIFF( TIMESTAMP_MILLIS(creation_time), PARSE_TIMESTAMP("%Y%m%d", SPLIT(table_id, "_")[OFFSET(1)], "Asia/Tokyo"), HOUR ) - 24 ) AS creation_hour_avg, FROM `<project>.<dataset>.__TABLES__` WHERE table_id LIKE "events_%" ;' +--------------------+ | creation_hour_avg | +--------------------+ | 13.077540106951869 | +--------------------+ -
上記は今回の対象サイトの数値であり、ご参考まで
-
-
ストリーミングエクスポート機能もあるが、要件に合わない
- 翌日以降にエクスポートされたレコードと比較すると、レコード欠損がある
- ストリーミングエクスポートの方が、翌日以降にエクスポートされたレコードより、2〜3割程度少ない
- 上記は今回の対象サイトの数値であり、ご参考まで
- リアルタイムではなく、10〜15分おきのエクスポートである
- 翌日以降にエクスポートされたレコードと比較すると、レコード欠損がある
- UA → GA4 の移行に伴う作業工数が大変
- カラム構成も大きく変わるため、データマート作成用のクエリ改修等が必要
- 今後もバージョンアップがあった場合(GA5?)、都度工数が発生
ただし、過去データとの整合性や、Google アナリティクスの全機能を自社で構築するのは不可能なため、
- リアルタイム〜数日程度前のデータは自社システムを参照
- それより前のデータは Google アナリティクスを参照
という方針を取っています。
全体構成
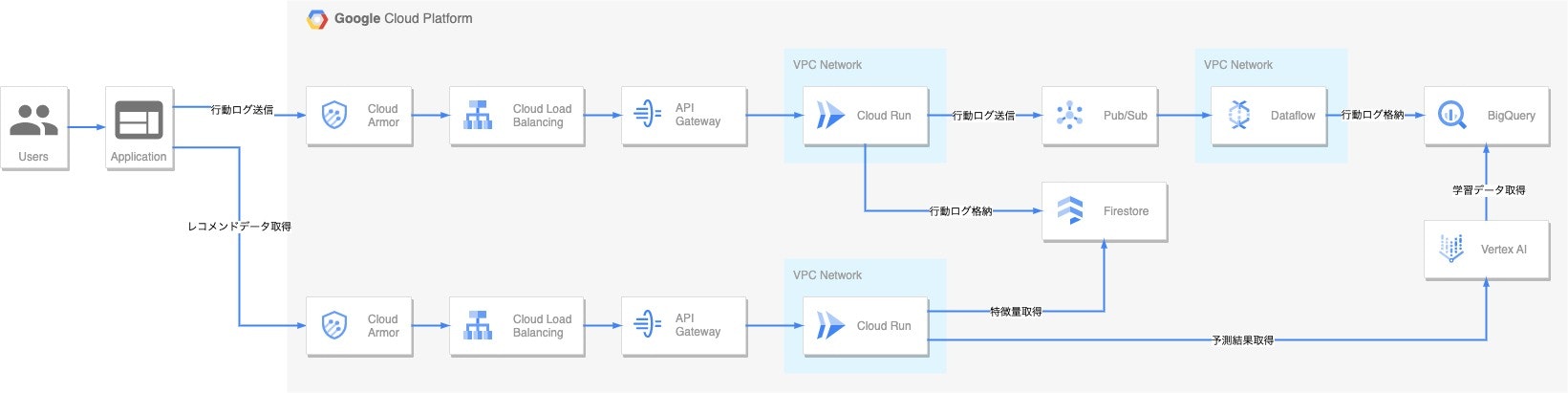
- 行動ログを格納する機能
- レコメンドデータを返却する機能
を、APIとしてアプリケーションに提供しています。
なお現時点では、行動ログを格納する機能のみがリリース済みで、レコメンドデータを返却する機能は絶賛開発中となります・・・。
各サービスの説明
行動ログを格納する機能
API の URL にパラメータを付与してアプリケーション側から叩いてもらいます。
パラメータの項目は以下の通りです。
| URL パラメータ | 備考 |
|---|---|
| ユーザ ID | アプリケーション側で発行している ID 。 |
| ユーザエージェント | URL エンコードして付与。 |
| タイプ | ヒット、イベント等。このログが何なのかを明示。 |
| カレント URL | 現在ページの URL 。URL エンコードして付与。 |
| リファラ | リファラ URL 。URL エンコードして付与。 |
Cloud Armor
DDos 等の攻撃を防御します。
Cloud Load Balancing
現時点で使用しているバックエンドサービスは、後述する Cloud Run のみであり、使用リージョンも1つだけですが、将来的な拡張を見据え導入しています。
API Gateway
API管理のために導入しています。
GCPは他にもAPI管理サービスがありますが、今回はバックエンドとして Cloud Run を使用しているため、API Gateway を採用しています。
Cloud Run
API のバックエンドサービスとして使用しています。
運用が非常に楽なため、採用しました。
言語は当初、個人的に使い慣れている Python を使用していましたが、以下と同様の現象が起きてしまい、Go を使用しています。
- 参考
Pub/Sub 〜 Dataflow 〜 BigQuery
Google Cloud でストリーミング処理を実現する際に定番の構成です。
最終的な BigQuery のテーブル構成は以下の通りで、Dataflow で動的にテーブル名を指定できないため、シャーディングではなく、1テーブルでパーティショニングしています。
| フィールド | 型 | 備考 |
|---|---|---|
| ユーザ ID | STRING | Cloud Run で取得したパラメータ。 |
| ユーザエージェント | STRING | Cloud Run で取得したパラメータ。 |
| タイプ | STRING | Cloud Run で取得したパラメータ。 |
| カレント URL | STRING | Cloud Run で取得したパラメータ。 |
| リファラ | STRING | Cloud Run で取得したパラメータ。 |
| アクセス時間 | TIMESTAMP | Cloud Run で生成。パーティショニング対象のフィールド。 |
また、Google 提供のテンプレートや BigQuery サブスクリプションの使用も検討しましたが、以下の理由から Python で自作したテンプレートを使用しています。
- Google 提供のテンプレートでは、パーティショニングされたテーブルが作成できない(テーブル作成時にオプションパラメータが渡せない)
- BigQuery サブスクリプションでは、データ型として DATE 、TIMESTAMP 、DATETIME が使用できない
- 前述したフィールド「アクセス時間」でのパーティショニングが実現できない
- 参考
Firestore
行動ログデータは、前述の通り BigQuery にストリーミングで格納されるのですが、完全なリアルタイムではありません。(ウィンドウ単位で格納するため。)
リアルタイムでのデータ取得のため、Firestore にも Cloud Run から データを直接送信しています。
また、必要なのは直近のデータのみであるため、TTL ポリシーで古いデータを自動削除できる Firestore を採用しています。
格納されるデータは BigQuery とほぼ同じですが、削除時間のフィールドを追加しています。
| フィールド | 備考 |
|---|---|
| ユーザ ID | Cloud Run で取得したパラメータ。 |
| ユーザエージェント | Cloud Run で取得したパラメータ。 |
| タイプ | Cloud Run で取得したパラメータ。 |
| カレント URL | Cloud Run で取得したパラメータ。 |
| リファラ | Cloud Run で取得したパラメータ。 |
| アクセス時間 | Cloud Run で生成。 |
| 削除時間 | アクセス時間 + 2 days 。Cloud Run で生成。 |
レコメンドデータを返却する機能
こちらは絶賛開発中ですので、設計思想のみお伝えします・・・。
Cloud Armor 〜 Cloud Run
行動ログを格納する機能と同様です。
Vertex AI
Two-Tower モデルを使用する想定です。
BigQuery に格納された過去の行動ログを学習データとし、Firestore にある直近の行動ログを基に、アイテム(物件)を推薦します。
今後の展開
A/B テスト機能や、複数の学習モデルの出し分け機能も提供できれば・・・と考えてします。
最後に
私が所属している Red Frasco では一緒に働く仲間を募集しています!
不動産業界を対象に、BigQueryをはじめとした Google Cloud サービスを利用したデータ分析、活用支援を行っています。ご興味ある方は以下からご確認ください!