はじめに
物理学専攻である私はふとこんなことを思った。
『arXivにアップされる論文のアブストを毎日自動でLINEに通知して欲しい。』
ということで、そんなシステム作れないかと思い諸々を用いて以下で実装しました。
中身に興味がなく、このシステムのみを実行したい人は、「⑤⑥:IFTTTの設定」の節から手を動かしてください。
したこと
実装するにあたり以下の2つの記事を主に参考にしました。
1.「自動でArxivから論文を取得して、日本語に直してLineに投稿すれば、受動的に最新情報が収集できるかも!」@sugupさん
2.「サーバーレス + Pythonで定期的にスクレイピングを行う方法」GAMMASOFTさん
私が追加でしたことは、
・1.の和訳部分をgoogle翻訳からDeepLに変更
・1.で選択する論文を1日分にし、その日の論文のみを収集
・以上で改良した1.のコードを、2.を参照にしながらCloud Functionsに載せる
・さらに、Cloud Schedulerを用いて毎日日本時間午前11時半に実行
です。
システム構成
以下の図のように実装しました。
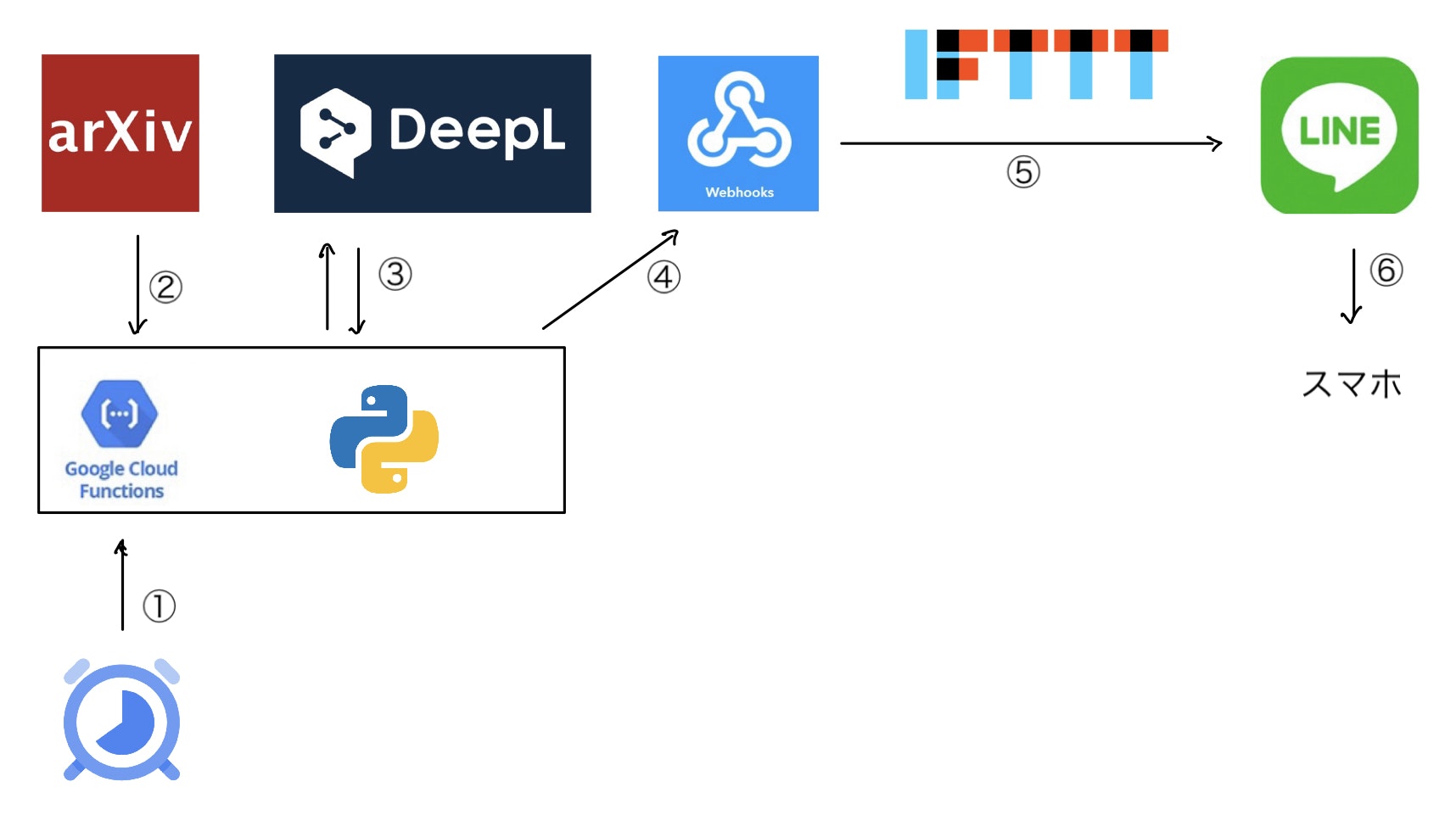
それぞれの段階で何をしているのか簡潔に述べておく。(詳細やコードについては後述)
① Cloud Schedulerで1日に1回コードを実行するトリガーを発生させ、Cloud Functions上の関数の実行を開始を指示する。
② 自分が指定した条件(分野など)の論文をarXivから取得してくる。
③ 今日の論文のアブストをDeepLで翻訳する。
④ 論文の情報(翻訳したアブストを含む)をIFTTTのwebhooksにPOSTする。
⑤ IFTTTを用いて論文の内容をLINEに転送する。
⑥ 自分のスマホに通知し、論文の情報をゲット!
このシステムを実行するために、皆様には次のことをしてもらう必要があります。
・自分が欲しい論文の条件(分野やキーワードなど)をQUARYに挿入
・DeepLの登録(free版で良い)&APIキーの取得
・IFTTTの登録&webhooksとLINEをつなげるAppletの個人用キーを取得
・Google Cloud Platformの登録&Cloud Functionsにコードを載せる&Cloud Schedulerの設定
これをすれば誰でも実行可能です。
それでは、それぞれの項目について見ていきましょう!
(便宜上、順番は⑤⑥→②〜④→①の順で説明します。)
⑤⑥:IFTTTの設定
やることは参考文献1.の「④、⑤:IFTTT設定」「IFTTTでの個人用KEY取得」の節で説明していることと全く同じです。
そこに書かれている作業をしてください。
「イベント名」と「そのイベントの個人用キー」を取得したら次に進みましょう。
②〜④:諸々の設定と実装コード
コード自体は以下のmain.pyですが、個人で設定しなくてはならないことがあるので、それを先にします。
まず、自分が取得したい論文の条件(クエリ)を与えましょう。
公式のマニュアルかArxiv API(@KMDさんの日本語記事)を参照して自分が欲しい論文の条件を決めます。
以下のmain.pyのコード内では次のようにクエリを与えました。
# 論文の条件を設定する
QUERY = "(cat:hep-lat)" #僕は格子やってるので。
このクエリではhep-latの分野の論文と指定しています。
次に、DeepLのfree版の登録をしてAPIキーを取得します。
https://www.deepl.com/pro#developer で「DeepL API Free」に「無料で登録」します。
(途中クレカの情報聞かれるが、自動で有償版には変わらない。)
さて登録が全て完了後、次にDeepLのAPI KEYを取得します。
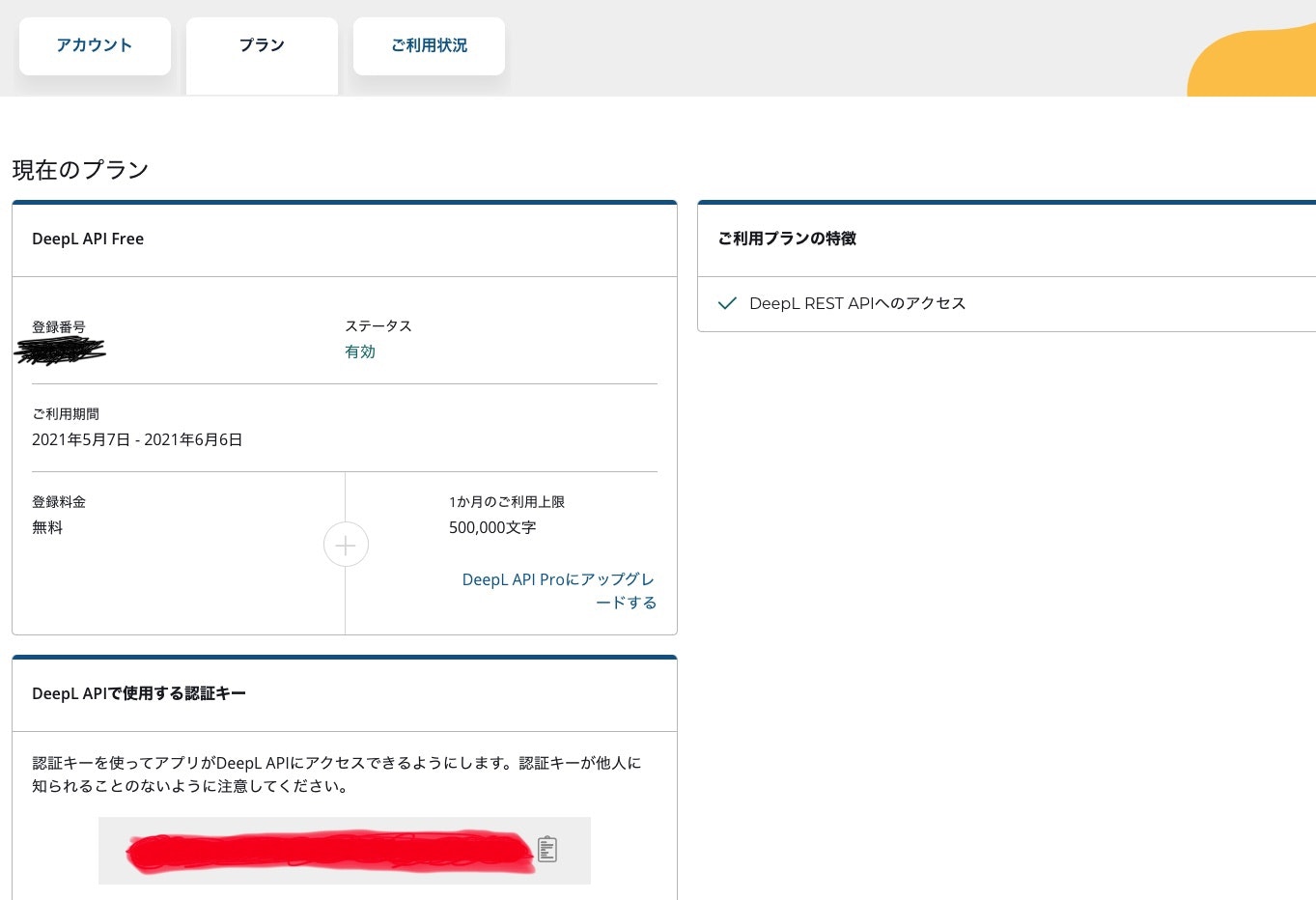
DeepLにログインをして右上の項目から「アカウント」というページに飛びます。(次の画像のようなページなる。)

上の写真の真ん中ら辺に「アカウント」「プラン」「ご利用状況」というタブがあるので、「プラン」を選択します。
そうすると次の画像の画面になり、赤く塗りつぶしている箇所にAPI KEYがあるのでコピーして取得する。
このAPI KEYは、以下のmain.pyのコード内で次の箇所にペーストしてください。
# 翻訳のためのAPI KEY(DeepL翻訳版)
# **にはご自分で発行されたdeepL API KEYを入れてください
DeepL_API_KEY = '**'
いよいよ次がコードに書き加える最後の設定です。
前節で設定したIFTTTの「イベント名」と「個人用キー」を以下のmain.pyの次の箇所にコピペしてください。
# IFTTTを用いてarXivとLINEを繋ぐ
# webhook POST先URL
API_URL = "https://maker.ifttt.com/trigger/<IFTTTに設定するイベント名>/with/key/<IFTTTでの個人用KEY>"
# <IFTTTに設定するイベント名>は自分で決める。<IFTTTでの個人用KEY>はIFTTTの設定後にsettingからコピペする。
さて設定をしっかり行い、以下のmain.pyを実行することで②〜④をできるようにしました。
# モジュールをimport
import datetime, re, requests
# 論文の条件を設定する
QUERY = "(cat:hep-lat)"
# 翻訳のためのAPI KEY(DeepL翻訳版)
DeepL_API_KEY = '**'
# IFTTTを用いてarXivとLINEを繋ぐ
# webhook POST先URL
API_URL = "https://maker.ifttt.com/trigger/<IFTTTに設定するイベント名>/with/key/<IFTTTでの個人用KEY>"
# 日付取得
today = datetime.date.today()
yesterday = today - datetime.timedelta(days=1)
# 指定したHTMLtagの情報を返す e.g. Input :<tag>XYZ </tag> -> Output: XYZ
def parse(data, tag):
pattern = "<" + tag + ">([\s\S]*?)<\/" + tag + ">"
if all:
obj = re.findall(pattern, data)
return obj
# 論文を探してきてwebhooksにPOSTする関数
def search_and_send(query, api_url):
while True:
counter = 0 #何個今日の論文があったかのカウンター
url = 'http://export.arxiv.org/api/query?search_query=' + query + '&start=0&max_results=100&sortBy=submittedDate&sortOrder=descending'
# arXiv APIから指定したURLの情報を受け取る
data = requests.get(url).text
# 各論文ごとに分ける
entries = parse(data, "entry")
# 各論文に対し情報の分離と翻訳を行う
for entry in entries:
# Parse each entry
url = parse(entry, "id")[0]
# 情報の分離
title = parse(entry, "title")[0]
abstract = parse(entry, "summary")[0]
date = parse(entry, "published")[0]
if date[0:10] == str(yesterday.strftime('%Y-%m-%d')): #今日の分の論文だけ得るという条件
# abstの改行を取る
abstract = abstract.replace('\n', '')
# deepLで日本語に翻訳
# https://deepblue-ts.co.jp/nlp/deepl-api-python/ を参照
# DeepLのURLクエリに仕込むパラメータを作っておく
params = {"auth_key": DeepL_API_KEY, "text": abstract, "source_lang": 'EN', "target_lang": 'JA'}
# DeepLに翻訳してもらう
request = requests.post("https://api-free.deepl.com/v2/translate", data=params)
#Pro版ならクリエを出すURLは、https://api.deepl.com/v2/translate
result = request.json()
abstract_jap = result["translations"][0]["text"]
message = "\n".join(["<br>Title: " + title, "<br><br>URL: " + url, "<br><br>Published: " + date, "<br><br>JP_Abstract: " + abstract_jap])
# webhookへPost
response = requests.post(api_url, data={"value1": message})
counter += 1
else:
if counter==0 :
messageend = "今日の論文は無しです。"
requests.post(api_url, data={"value1": messageend})
return 0
else:
messageend = "今日の論文は以上です。"
requests.post(api_url, data={"value1": messageend})
return 0
def main():
# setup
# IFTTT APIを設定
api_url = API_URL
# arXiv APIのクエリ
query = QUERY
# start
# LINEに時間を送る
dt = datetime.datetime.now().strftime("%Y/%m/%d") + ": arXiv 2 LINE"
requests.post(api_url, data={"value1": dt})
# 今日の論文をLINEに送る
search_and_send(query, api_url)
# main関数を実行(Cloud functionsでは不要)
# main()
Goolgle colaboratoryなどで実行してちゃんとLINEに通知がきたらオッケー!
①:Cloud Functions&Cloud Scheduler
あとは、この関数をクラウド上で定期的に実行させれば良さそうなのでやっていく!
具体的には、Cloud Functionsにmain.pyを載せ、Cloud Schedulerで定期的にトリガーを出すことで関数を定期実行する。
やることは、参考文献2.の「Google Cloud Platform(GCP)への登録」〜「Cloud Scheduler ▶ ジョブの実行」です。
なので、このサイトを見て順番に一つ一つやっていきましょう。
変更点は、次の3点です。
・Cloud Functionsのmain.pyには上記のmain.pyをコピペ
ただし、コード中のmain()をmain(event, context)に書き換える。(Schedulerとの関係による)
・requirements.txtの内容は次のように変更
datetime
requests==2.23.0
・Cloud Schedulerの「頻度」は、「30 11 * * *」に設定(お昼ごはん前にデータを得る。)
まとめ
このように、arXivの論文の和訳されたアブストを毎日LINEに通知してくれるシステムができました。(少しめんどいかもですが)
LINEの代わりにIFTTTをいじればslackとかにも通知することができるのでそちらもお試しあれ。
最後に注意点といたしましては、DeepL API Freeには文字制限があるのであまりに多くの論文は訳せないです。
また、GCPも無料で使える範囲かどうかは各個人の責任でお願いいたします。
個人的には、初めてIFTTTやGCPに触っていい勉強になりました。
もっと多くのAPIを触ってみたいです。