動機
The Rust Performance Book という書きものを見つけました。いろいろなパフォーマンス改善テクニックが書かれているわけですが、実際に普段書いてる Rust コードの中で一体何がパフォーマンスに与える影響が大きいのか?という点が気になってベンチマークを取ってみました。
今回パフォーマンスを計測するプログラムはビットマップ画像(1600px x 1200px)をグレースケールに変換する処理です。I/O のパフォーマンスは無視します。&[u8]から RGB をそれぞれ 1byte ずつ(合計 3bytes)取ってきて、それをグレースケールの 1byte に変換してVec<u8>にする時間を計測します。イメージとしては下記のような関数です。
// source が カラーのビットマップ画像のデータ
fn sample(source: &[u8]) -> Result<Vec<u8>> {
let mut v = vec![];
// source から 3bytes ずつ取り出す
for d in source.chunk(3) {
// グレースケールに変換して v: Vec<u8> に追加
v.push(to_grayscale_f32(d)?);
}
// グレースケール画像のデータを返す
Ok(v)
}
グレースケールへの変換はグレースケール画像のうんちくの CIE XYZ を参考にしました。コードは下記の通りです。
(#[rustfmt::skip]アトリビュートを付けておくとrustfmtで整形されなくなります。可読性のためにわざとインデントを入れたりしていて整形されたくない場合に便利です。)
# [rustfmt::skip]
fn to_grayscale_f32(bgr: &[u8]) -> Result<u8> {
Ok(
(
0.0722 * bgr.blue()? as f32 +
0.7152 * bgr.green()? as f32 +
0.2126 * bgr.red()? as f32
)
as u8
)
}
環境
rustc 1.57.0
Windows 10 64bit
Core i5 8200Y 1.3GHz
メモリアロケーションによる影響
実装
メモリアロケーションが頻繁に発生する状況を想定しています。↓こんなコード書く人はいないと思いますが…。
fn lots_of_allocation_f32(source: &[u8]) -> Result<Vec<u8>> {
let mut v = vec![];
for d in source.chunks(3) {
// 無意味に Vec に Vec を追加
v.push(vec![to_grayscale_f32(d)?]);
}
// Vec<Vec<u8>> を Vec<u8> に変換
let v = v.into_iter().flatten().collect();
Ok(v)
}
比較としてVec::with_capacityでメモリアロケーションを抑えた実装を書きました。
fn less_allocation_f32(source: &[u8]) -> Result<Vec<u8>> {
// あらかじめグレースケール画像サイズ分のメモリ領域を確保しておく
let mut v = Vec::with_capacity(1600 * 1200);
for d in source.chunks(3) {
v.push(to_grayscale_f32(d)?)
}
Ok(v)
}
もう一つ比較としてイテレータを用いた実装です。すっきり書けて気持ちいい!
fn use_iterator_f32(source: &[u8]) -> Result<Vec<u8>> {
source.chunks(3).map(to_grayscale_f32).collect()
}
結果
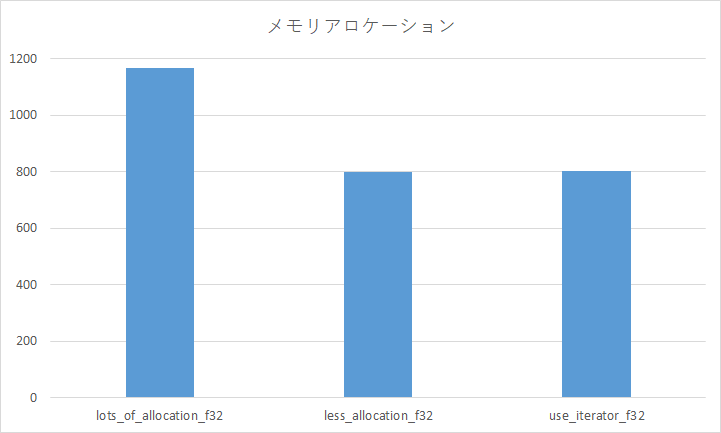
グラフの縦軸の単位は msec で、関数一回の実行時間です。当たり前ですがメモリアロケーションが頻繁に発生する状況では遅くなります。それにしても 1600 x 1200 x 3bytes ≒ 6MB のビットマップ画像をグレースケールに変換する処理にしては全体的に遅すぎますね。メモリアロケーション以外にも何か良くないことが起こっていそうです。(もちろん--releaseオプション付きです。)また、イテレータを使ってもパフォーマンスに差はでないのですね。以後のパフォーマンス比較ではイテレータを使うことにします。
遅延評価による影響
リンク先にも書いてある通り、Option::ok_orはエラーではないときにもok_orの中が評価されます。なので、関数が返すOptionをok_orでResultに変換するときはok_orの中で高コストな処理はしてはいけません。もしくはok_or_elseを使ってエラーのときだけ処理が実行されるようにするべきです。
実装
RGB の 3bytes [u8; 3] から 1byte ずつ抜き出す処理は下記のように実装していました。エラーではないときもanyhow!マクロが評価されてしまいます。
use anyhow::{anyhow, Result};
impl GetByte for &[u8] {
fn byte(&self, index: usize) -> Result<u8> {
self.get(index).copied().ok_or(anyhow!("error"))
}
}
遅延評価されるようにok_or_elseに変えてみます。
use anyhow::{anyhow, Result};
impl GetByte for &[u8] {
fn byte(&self, index: usize) -> Result<u8> {
self.get(index).copied().ok_or(anyhow!("error"))
}
fn byte_lazy(&self, index: usize) -> Result<u8> {
self.get(index).copied().ok_or_else(|| anyhow!("error"))
}
}
さらにanyhow::Contextを使った場合と、unsafe な実装もパフォーマンス比較用に準備しました。
use anyhow::{anyhow, Context, Result};
impl GetByte for &[u8] {
fn byte(&self, index: usize) -> Result<u8> {
self.get(index).copied().ok_or(anyhow!("error"))
}
fn byte_lazy(&self, index: usize) -> Result<u8> {
self.get(index).copied().ok_or_else(|| anyhow!("error"))
}
fn byte_context(&self, index: usize) -> Result<u8> {
self.get(index).copied().context("error")
}
fn byte_unchecked(&self, index: usize) -> u8 {
unsafe { *self.get_unchecked(index) }
}
}
結果
左から順に、遅延評価しない場合、遅延評価した場合、anyhow::Contextの場合、エラーチェックしない場合です。圧倒的な差です。遅延評価するようにしましょう。(cargo clippyすると遅延評価するように教えてくれます。)
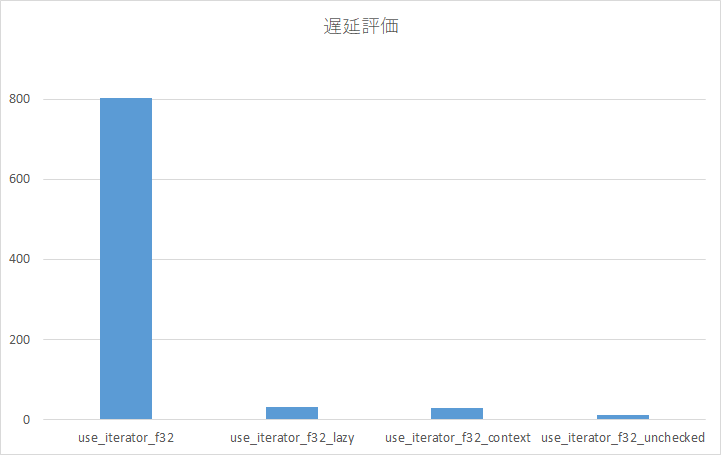
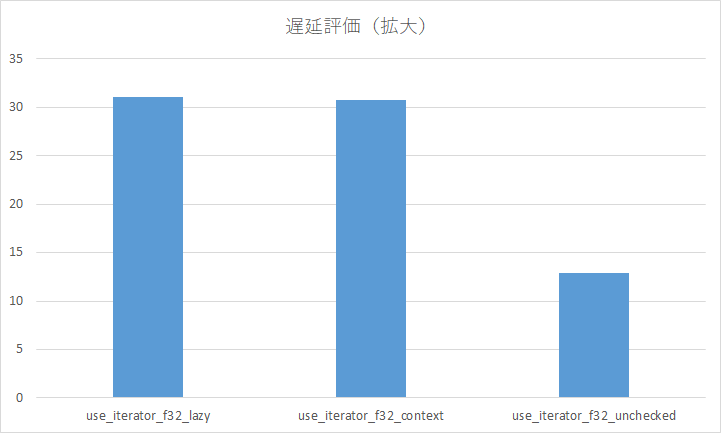
右三本が見えないので拡大しました。unsafe パワーは魅力的ですが、ちゃんとエラーチェックはしましょう。
浮動小数点数による影響
浮動小数点数演算は幾分かコストが掛かります。これは Rust に限った話ではなく、他の言語でも同じですね。
グレースケール変換で浮動小数点数f32を使っていますが、整数u16で変換するように書き換えてみます。
実装
整数演算してからビット演算>>8でもって 256 で割っています。
// 浮動小数点数演算
# [rustfmt::skip]
fn to_grayscale_f32(bgr: &[u8]) -> Result<u8> {
Ok(
(
0.0722 * bgr.blue()? as f32 +
0.7152 * bgr.green()? as f32 +
0.2126 * bgr.red()? as f32
)
as u8
)
}
// 整数演算
# [rustfmt::skip]
fn to_grayscale_u16(bgr: &[u8]) -> Result<u8> {
Ok(
(
((19 * bgr.blue()? as u16) >> 8) +
((183 * bgr.green()? as u16) >> 8) +
((54 * bgr.red()? as u16) >> 8)
)
as u8
)
}
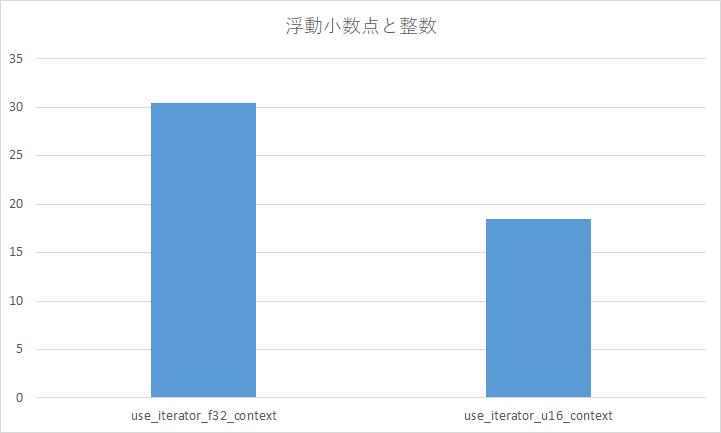
結果
なるべく整数演算しよう。
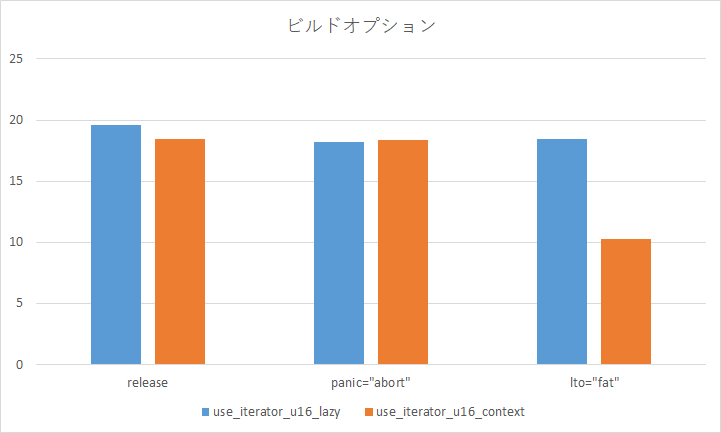
ビルドオプションによる違い
実装
--releaseをオプション付けただけのビルドと、さらにpanic="abort"を設定したときと、lto="fat"を設定したときのパフォーマンスを比較します。
[profile.release]
panic = "abort"
[profile.release]
lto = "fat"
codegen-units = 1
panic = "abort"
結果
anyhow::Contextを使って、lto="fat"を設定した場合が異常に早いです。何かアグレッシブな最適化が働いているのでしょうか?謎です。コンパイル時間は長くなりますが、lto="fat"を設定しよう。
まとめ
Option::ok_or の中に高コストな処理を書いてはいけない。
今回は The Rust Performance Book の中のほんの一部分だけですが、パフォーマンスに与える影響を調べてみました。他にもいろいろなテクニックが書いてあるので目を通しておくとよいでしょう。おわり。