はじめに
現在の会社で、半年ほど前からログ分析基盤の構築に取り組み、昨日試験的に本番運用を迎えました。
これを機にアーキテクチャの振り返りを会社のブログにて公表しましたので、こちらでも紹介したい思います。
基本的には内容は同じですので、見やすい方で見ていただければと思います。
また、リンクを辿っていただければ、他の社員が書いたブログもたくさんありますので、興味持っていただければ幸いです。
解決したかった課題
当社では、ここ1,2年ユーザ行動ログ等のさまざまなデータを機械学習等の分析につなげようという動きが多くなっておりますが、主に以下の二つにより、分析、及び分析の結果を用いたアプリの作成が制限されてしまっておりました。
- ログが一台のサーバのPostgresにhstore形式にて格納されている
- Postgresは分析に適していない
- スケールしない(複数サーバによりクラスタリング構成を組めない)
- 日次の夜間のバッチ処理で前日分のログがデータベースに格納されるので、リアルタイムな分析やアプリケーションを作成することができない
- 仮に秀逸なレコメンドモデルをデータサイエンティストが作成したとしても、一日前のデータなので精度が落ちるといったことがおこりうる
これらを解決する構想は1年ほど前からあったのですが、しばらく手をつけることができず、2018/10月頃から実際に始動しました。
構想から1年、着手から約半年がたち、とうとう昨日から試験的に本番運用されたため、これを機に全体のアーキテクチャを振り返りたいと思います。
想定する読者
- Hadoop, Spark等を導入したいけど、社内に知見があるひとがいない
- Hadoop界隈のOSSが非常に入り乱れていて諦めそう
といった過去の自分のような人が当時にあったら非常に助かったであろう情報を目指します。
そのため、勘違いしやすいポイントやハマりどころをメインに書きますが、ネットで調べればすぐわかる情報はあえて書きません。ただ、良質なソースはどんどん紹介していきます。
一方、私自身今回紹介するOSS全て半年前まで触ったことがないくらいなので、ログ分析基盤専門でされている方には何をいまさらと言われかねませんが、ログの収集から分析まで振り返るきっかけになればと思います。
全体の流れ
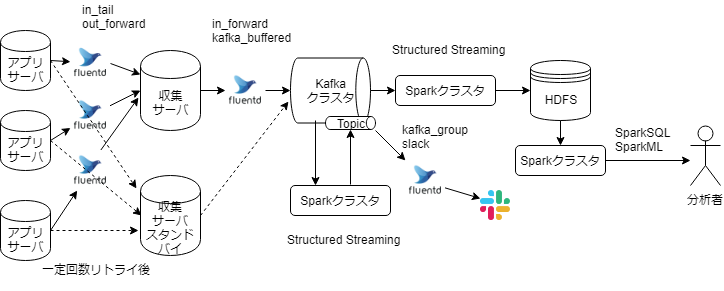
オーソドックスな構成かと思います。おおまかに、
- 各アプリサーバから収集サーバへ送ります。収集サーバ障害時はスタンドバイが利用されます
- 収集サーバでfilter処理(フィルタリングや情報の追加など)後、Kafkaに送ります。このとき、アプリによってTopicを変えます。KafkaにはJSONにて格納します。
- KafkaクラスタからConsumeします
- HDFSにためます
- Structured StreamingにてHDFSにparquet形式で書き込みます。
- その後、バッチ処理やアドホックな分析に利用されます。
- リアルタイムな分析に利用されます
- アプリのメトリクスをもとにStructuredStreamingにて処理後、トピックに書き戻します。
- トピックをfluentdが読み込み、バッチで計算した閾値をこえた場合、リアルタイムにslackに検知します。
- HDFSにためます
図では省いてますが、クラスタマネージャとしてMesos、Kafkaの縁の下の力持ちとしてZookeeperが稼働してます。
なお、わかりやすさの都合上、図ではクラスタが別サーバ群で構成されてますが、現在は試験運用中のため、同一クラスタ上で構成されてます。
システム全体を見通した信頼性
各OSSでの説明に入る前に、全体を通した信頼性について述べます。
- システム全体としてどの程度の信頼性が必要なのか
- それぞれのOSSはどの程度までサポートしているのか
- そのOSSは他のOSSと組み合わせた場合にどうなるのか
といったことを念頭に入れたほうがいいでしょう。
観点としては、
- 順序を保証するか
- データ到達の保証
- at most once
- データロストを許容
- at least once
- データ重複を許容
- exactly once
- データロスト、データ重複ともに許容しない
- at most once
- 可用性をどの程度保証するか
等があります。
システム全体の信頼性は各ミドルウェア、及びその組み合わせでの信頼性に依存します。Fluentdはat least once、KafkaおよびSparkStructuredStreamingはexactly onceを保証すると主張していますが、これらを組み合わせて使う場合、例えばSparkStructuredStreamingの処理結果をKafkaに書き込む場合は、at least onceとなるため、システム全体としては必然的に at least once以下になります。
アプリケーション側の工夫にて、exactly onceを保証できる場合もありますが、一般にデータフロー全体を通して、exactly onceを保証するのはかなり難しいようです。
今回の設計においては、順序の保証を必要とはせず、データ到達の保証はat least onceを要件とします。
Fluentd(1.3.3)
学習方法
fluentdを今から導入する場合には、td-agent3を利用するかと思いますが、2019年4月現在だと、Qiitaなどの日本語記事はほとんどがtd-agent2系を元に説明されております。
td-agent2系からは仕様がかなり変わっているため、私の場合は参考にしようとして逆に混乱しました。
fluentdは覚えることも少ないですし、これから勉強する人は、そういった記事を読まず、本家のマニュアルのみを基本的には参照するというのもアリかと思います。
とはいっても、マニュアルは量が多すぎるよ!という人もいるかと思いますので、独断と偏見で選ぶと、以下を2、3回くらい読むと基本は抑えられると思います。ざっと1回読むのであれば、5、6時間でしょうか。
- OverView
- Configuration (特に重要)
- Input Plugins ~ Buffer PluginsのそれぞれのOverView
-
in_tail,in_forward,in_http,out_file,out_forward,out_copy,out_stdout,filter_grep,filter_record_transformer
Bufferについて
大抵のことは、マニュアルを読めばわかるのですが、Buffer Pluginsのところはよくわからず、どのようにオプションを設定したら良いかわからないという状況になるかと思います。
に非常にわかりやすく書かれています。
特に「chunkをenqueする」部分にてenqueするタイミングの設定周りがややこしいので、少し触れますと、それぞれの場合で、いずれかの条件を満たすとenqueします。
-
chunk keyとしてtimeが指定されている場合- chunkのレコード数が
chunk_limit_recordsに達した - chunkのレコード容量が
chunk_limit_size*chunk_full_thresholdに達した場合 -
timekey時間経過ごと(厳密には、timekeyの時間幅の終端に達し、+timekey_wait経過した時刻)
- chunkのレコード数が
-
chunk keyとしてtimeが指定されてない場合- chunkのレコード数が
chunk_limit_recordsに達した - chunkのレコード容量が
chunk_limit_size*chunk_full_thresholdに達した場合 - chunkが作られてから
flush_interval時間経過時
- chunkのレコード数が
それぞれのデフォルト値は、
-
chunk_limit_size: Default: 8MB (memory) / 256MB (file) -
chunk_full_threshold: Default: 0.95 -
flush_interval: Default: 60s -
chunk_limit_records: なし -
timekey_wait: 10s
です。
なお、上記はデフォルトの挙動であり、flush_mode=intervalを指定することで、timekey指定はしつつflush_intervalを有効にしたり、flush_mode=immediateを指定することで、バッファリングを使用しない設定が可能です。
他には以下のような設定があるため、場合によっては設定を検討しましょう。
-
flush_thread_interval(Default: 1秒 バッファをキューに入れる処理のインターバル) -
flush_thread_burst_interval(Default: 1秒 キューから取り出し、送信する処理のインターバル) -
flush_thread_count(Default: 1 キューから取り出し、送信する処理のスレッド数) -
queued_chunks_limit_size(Default: No limitだが、こちらによると実質的にはflush_thread_countのよう。 キュー内のchunk数の上限。Fluentd v1.1.3 has been releasedを参照するかぎり、flush_interval経由でのenqueのみ抑制できるよう)
in_tailプラグインのハマりどころ
in_tailのpathに時間のformat文字列を含む指定をしたかつ、read_from_head(デフォルトfalse)をtrueに変更していない場合は、初期のデータの読み込みをスキップしログを取りこぼしてしまう可能性があります。
日付が変わるなどして新しい日付のファイルにrotateされても先頭から読んでくれないので、ご注意ください。
一方、パスが変わらずにrotateされるタイプの場合はデフォルトで先頭から読むことになります。
詳細はfluentdのin_tailプラグインの動作について理解するを参照ください。
信頼性について
Fluentd High Availability Configurationにあるように、バッファに書き込む前にクラッシュした場合は為す術がないですが、その他の場合は各種プラグインを使うことで高い可用性を保証できます。
なお、exactly onceはそもそもサポートしてません。
bufferプラグイン
デフォルト設定では、リトライの回数には上限がなく、リトライの時間の上限には72時間(retry_timeout)が設定されています。
ただ、リトライ間隔は、デフォルトでは、2秒、4秒、8秒、16秒と倍々に伸びていくのでretry_max_intervalにてリトライ間隔の上限を設けたほうがいいでしょう。
参考までに、計算してみたところ、デフォルト設定では、リトライ上限直前のリトライ間隔は18.2時間となりました。
secondaryプラグイン
- outputプラグイン内に記載することができ、リトライしても出力できなかった場合に行う処理を書ける。
- サーバに接続できなかったため、ローカルのファイルに書き込むなど。
forwardプラグイン
- require_ack_response
- Default: false
- at-least-onceを指定できます
fluent-plugin-kafka
fluentdからkafakへの流し込みは、buffered-output-pluginを利用しました。
ただ、ドキュメントがあまり充実しておらず、
partition_keyってなんだ?
partition_key_keyなんてものもあるぞ?
と混乱必須です。
正直ソースを眺めたほうが早いです。私自身Rubyの文法は何一つわからないですし、fluentdプラグイン作成のお作法等何も知らないですが、設定値の意味くらいは4,5分で理解することができました。
まず、partition_keyは何者かですが、同様の概念が本家のJavaクライアントにない気がして本家のDefaultPartitionerの実装を確認しましたが、やはり、ありませんでした。
どうやら、fluent-plugin-kafkaの内部で利用されているkafkaのrubyクライアントruby-kafkaでは、partition_keyの指定がある場合は、メッセージのキー(通常のkafkaの文脈で使われるメッセージのkey、valueのkeyのこと)ではなく、partition_keyを元にハッシュを計算してランダムにパーティションされるようです。ruby-kafkaの該当ロジックはここです。
これにより、ruby-kafkaのドキュメントにあるように、トピックのキーは存在するけど、キーの値が偏っているなどの理由で、その値でパーティションを決定させたくない場合は、partition_key: rand(100)などを指定することができ、そういう意味で、本家よりも柔軟な指定ができると言えます。(当然、自前でPartitioner を実装すればJavaでも同様のことはできます)
partition_keyが何者かわかったので、partition_key,partition_key_keyを説明しますと、レコードのpartition_keyの値が、partitionとして採用され、レコードのpartition_key_keyの値がpartition_keyとして採用されます。前者の値は整数で、後者の値は文字列。前者の「key」はレコードのキー、後者の「key_key」はpartition_keyのkeyとレコードのキーです。ややこしい笑。
両方指定された場合は、ruby-kafkaの挙動で、partitionがpartition_keyより優先されます。
上記が理解できれば、その他関連オプションは以下のソースで理解できるかと思います。
topic = (@exclude_topic_key ? record.delete(@topic_key) : record[@topic_key]) || def_topic
partition_key = (@exclude_partition_key ? record.delete(@partition_key_key) : record[@partition_key_key]) || @default_partition_key
partition = (@exclude_partition ? record.delete(@partition_key) : record[@partition_key]) || @default_partition
message_key = (@exclude_message_key ? record.delete(@message_key_key) : record[@message_key_key]) || @default_message_key
トピックもレコードによって動的に振り分けることができるんですね!
他には、デフォルト値が、
max_send_retries が1、required_acksが-1となっていたり、Java本家と微妙にデフォルトの設定値が異なる場合があるので、確認が必要です。
ZooKeeper(3.4.13)
KafkaのBroker、トピック、パーティションに関するメタデータを格納するのに利用します。
Kafka0.9以前はConsumerグループのオフセット書き込みなどもしていたようですが、現在は書き込みが発生するのは、Consumerグループのメンバー変更時、もしくはKafkaクラスタ自体に対する変更のみでトラフィックはかなり限定的であるようです。
その性質上、クラスター構成は奇数台が望ましく、多くの場合は3台で構成すれば良さそうです。
Kafka(2.1.1-cp1)
学習方法
-
Apache Kafka 分散メッセージングシステムの構築と活用
- お勧めです。まず読むのはこちらでしょう。
- ソースも豊富なので、実際にコードを動かしましょう
- StructuredStreamingとの連携も1章分さかれています
-
Kafka
- ソースはほぼないですが、Kafkaの内部構造等、Deepな部分の理解にはとても良かったです。2周くらい読まないと理解できませんが。。
正直、Kafkaのクライアントコードを自前で書くことはあまりないと思いますし、結局今回もSpark、Fluentdのインテグレーションを利用しましたので、自前では一行も書いてません。
ただ、Kafkaは、Broker, Producer, Consumerと役割が異なる登場人物がいて、個人的にはやや複雑だと思います。本にあるようなサンプルを実際に動かしてみることをお勧めします。
また、ある程度仕組みがわかってないと、Kafkaの設定値をどのように設定すべきかわからないと思うので、そういう意味でもある程度の理解は必要です。
ディストリビューション
開発元のApache Software Foundationが配布しているコミュニティ版ではなく、Schema Registryなどの便利なコンポーネントがデフォルトで含まれているため、Confluent社が配布しているConfluent PlatformのOSS版を利用しました。
また、蛇足ですが、AnsilbeのPlaybookのベースも公開されており、AnsibleのPlaybookを書く際に非常に参考にさせてもらいました。
信頼性について
Topic
- min.insync.replicas
- 最小のin-syncレプリカ数(デフォルト1)
Broker
- unclean.leader.election.enable
- out-of-syncレプリカがリーダーになることを許容するか(デフォルトfalse)
Producer
-
retries
- リトライ回数(デフォルト0)
- パーティションリーダ不在など復旧可能なエラーについては、アプリケーション側で実装せずともProducer側でリトライしてくれます(デフォルト100msインターバル後)
- 普通は設定するもののようだが、リトライすると、
max.in.flight.requests.per.connectionが1以上(デフォルト5)だと、メッセージ順序が保たれない一方、1に設定するとスループットが大幅に制限される。
-
acks
- 0
- ProducerはBrokerからの応答を待たずに成功とみなす
- 1(デフォルト)
- リーダーレプリカの受信を成功とみなす(ディスク書き込みは保証しない)
- 成功と判断後、リーダーレプリカにてディクス書き込み前にクラッシュして、メッセージを受信していないレプリカが新しいリーダーに選出された場合、ロストの可能性がある
- all
- in-syncレプリカ(同期しているレプリカ)全ての受信完了を成功とみなす
- レプリケーションが遅延して、in-syncレプリカが1の場合もあり得るので、
min.insync.replicasを2以上に設定することが多いよう。
- 0
Consumer
- auto.offset.reset
- earliest
- 有効なオフセットがない場合、先頭から消費
- メッセージ重複する可能性あり
- latest
- デフォルト
- 有効なオフセットがない場合、末尾から消費
- メッセージロストする可能性あり
- earliest
- 設定値ではないですが、オフセットのcommitはアプリケーション側に委ねられている部分で、実装によって、重複、ロスト等しやすい部分なので気をつけましょう。
今回は、
- min.insync.replicas: 2
- acks: all (fluent-plugin-kafka、Structured Streaming + Kafka Integrationでの設定)
- retries: 10 (fluent-plugin-kafka、Structured Streaming + Kafka Integrationでの設定)
を設定しました。
Kafka単体ではKafka.0.11よりexactly-onceをサポートしましたが、この仕組みだけで外部システムに正確に1回だけ書き込むことができるわけでないです。
exactly onceを外部システムへの書き込みまで含めてサポートするには、プライマリーキーをサポートするデータストアに冪等書き込みするように設計する(同じkeyと同じvalueで複数回書き込みがおきても問題ないようにする)か、トランザクションをサポートするデータストアでオフセット管理も行う(Kafka p.81参照)などアプリケーション側での工夫が必要になります。
繰り返しになりますが、今回はexactly onceは求めません。
Kafkaでのフォーマット
- JSON
- Apache Avro
が選択肢に上がりましたが、JSONを採用しました。
KafkaではJSONの他に、Avro, SchemaRegistryを組み合わせて使うのが一般的で、AvroはJSONの以下の問題を解決します。
- データ作成側が自由にフィールドを追加、削除等の変更ができるので、利用側が解釈できなくなる可能性がある。
- フィールドや型情報はファイル内では同一であるにもかかわらず、レコードごとに記載するので、冗長である。
Avroでは、スキーマ情報を1つのみファイルの冒頭に格納します。また、SchemaRegistryを使えば、スキーマの一元管理、互換性チェック等を行えます。
そのようなメリットが運用コストを上回るかを天秤にかけた場合、当社のような専門チームが存在せず、属人化しやすい環境ではAvroは避けたほうがいいと思い、JSONを採用しました。
なお、Avroについてはまとまっている情報がなかったので、以前Avro,SchemaRegistryことはじめを書きましたので、検討する際には、参考にしてください。
Apache Mesos(1.7.2)
Apache Mesosについては、Mesos実践ガイドを購入したものの読めてなかったりと勉強不足なので、クラスタマネージャとしてApache Mesosを採用することに否定も賛成もできませんが、YARNのほうが圧倒的に利用されていて、情報が多いことは明らかなので、特にこだわりがなければ、YARNでいい気はします。
Spark2.3からサポートされたKubernetesも現在は発展途上ですが、今後はメジャーになるかもしれません。
Mesosをなんとなくでも理解するには、まずは、MesosUIの見方をジョブを動かしながら理解していくのが一番かと思います。
ひとつ注意点をあげるとすれば、デフォルト設定だとsparkアプリケーションはクラスタのコアを際限なく利用しようとします。後から他のジョブ要求がきたから空気を読んでコアを開放するといったこともありません。
そのため、デフォルトだと同時にSparkジョブを動かすことができないので、必ずジョブ起動時にspark.cores.maxに許容するクラスタ全体のコア数の上限を指定しましょう。
Hadoop(3.1.1)
学習方法
今回は、HadoopのHDFS、MapReduce、YARNの機能のなかで、HDFSのみ利用しています。HDFSの機能のみ利用する分には特に困ることも少なく、学習する優先度としては低いでしょう。
しっかり勉強するには、私は読めてませんが、
のような本を読むべきかと思いますが、ざっと把握する分には、
等をざっと眺めておけばいいと思います。
注意点
注意点があるとすれば、「HDFSは、大量の小さいファイルの扱いには適していない」ことを意識する必要があるということです。デフォルトのブロックサイズも128MBとなっております。SparkがHDFSのブロック単位でパーティションを割り当てることからもサイズには気をつけたほうが良さそうです。
では、実際ファイルサイズはいくつが適切なのか?と気になるところですが、先日参加したHadoop / Spark Conference Japan 2019では、「あくまで目安だが、最低でも100MBが理想」といった説明が口頭でされていたと記憶しています。
今回でいえば、SparkStructuredStreamingにて、HDFSにparquet形式で書き込んでいるのですが、trigger intervalを設定する目安にしました。
HDFS上でのフォーマット
正直この部分は自分が主に調査した部分ではないのですが、
- ORC
- Parquet
が選択肢に上がりましたが、Parquetを採用しました。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜にあるような最適化ができ、データ分析に適したカラムナフォーマットが基本的にはよいかと思います。
カラムナフォーマットの中では、独断と偏見で選ぶHDFSのファイル形式などを参考にするとORC、Parquetどちらも一長一短でありましたが、Sparkのdocumentでも記述が多く、デフォルトのフォーマットでもあるため、Parquetに軍配が上がりました。
SparkStructuredStreaming(2.4.0)
学習方法
-
アプリケーションエンジニアのためのApache Spark入門
- とてもおすすめです。ログ基盤構築のために読んだ本の中では一番良かったです
- ソースが豊富ですぐ動かせる一方、理論的な部分も説明されており、そのバランスが非常に良いです
- 1回通しで読んだ後、手を動かしながら読むことをお勧めします
-
Apache Spark入門 動かして学ぶ最新並列分散処理フレームワーク
- 2015年の本なので、情報はかなり古いです。コードを書くのに参考にするというよりもRDDも少し知っておきたいなという方が眺めるにはいいでしょう。
概要
SparkStreamingより高レベルのAPIで Dataset/DataFrame としてストリームデータを利用できます。マイクロバッチという方式で、100ms~数秒ほどのレイテンシ(exactly-once)があり、そのレイテンシが許容できない場合は、以前は他のストリーム処理フレームワークを利用せざるを得ないようでしたが、Spark2.3からcontinuous-processing がリリースされ、1 ms~のレイテンシ(at-least-once)を実現できます。
ストリーム処理固有の概念等あるので、ストリーム処理OSSを触れたことが無い人は、
structured-streaming-programming-guideに一通り目を通して、以下のような概念を学んだ方が良いでしょう。
- EventTime, ProcessingTime
- TumblingWindow, SlidingWindow, SessionWindow
- Watermark
- Trigger
- OutputMode(Append,Update,Complete)
また、上記の設定値により、出力されるタイミングが直観と異なる場合があり、あれ?なかなか結果が出ないぞとなりえるので、注意が必要です。
例えば、watermarkを設定した場合、DefaultのAppendモードでは出力が遅延されることを、handling-late-data-and-watermarkingの図で確認できます。
(2019/4/24加筆)
ハマったところはそこまでなかったのですが、後々でてきたため、そのあたりを
StructuredStreamingでJOINしているstatic Dataframeの更新を反映させる方法
に書きましたのでよければ。
KafkaStreamsとの比較
分散ストリーム処理エンジンあれこれを見ていただけるとわかるように、OSSがありすぎてカオスになってます。OSSを新たに導入すると設計が重くなってしまうので、StructuredStreaming以外では、KafkaStreamsのみ試しに触ってみました。KSQLは触れてません。
KafkaStreamsが優れている点
-
ドキュメントやすぐに動くサンプルが非常に充実しているので複雑なことをしない限り、「知りたい情報がネットにない」といったことにはまずならない。やはり新しいOSSを触る際にコード例がたくさんあることは非常に助かりますし、触ってみたいという気持ちも高まります。
-
単純にJavaのアプリケーションを複数サーバそれぞれで起動させるだけでストリーム処理クラスタが簡単に構築されます。Spark導入の際のようにYARN,Apache Mesos等を導入する必要性がなく、利用障壁が低いです。
-
StreamとTableの関係とかプログラミングしている感があって触っていて楽しい笑。逆にいうと、ライブラリの使い方を覚える必要がある。
SparkStructuredStreamingが優れている点
- ほとんど、バッチ処理とおなじようなDataframeの操作でストリーム処理が可能なので、勉強のコストが低い。
- SparkSQLやSparkMlibでバッチ処理した結果を利用したりといったことがすぐにでもできる
- UDF(ユーザ定義関数)等をバッチ処理等と共有できる
- 開発スピードが速く、注目度が高い。continuous-processing がサポートされるなど今後も成長していきそう
上記を考慮すると、YARN,Apache Mesos等導入していないが、ちょっとしたストリーム処理をしたいといった場合や、複数人の専門チームでいろいろカスタマイズしたいといった場合にはKafka Streamsは向いていると思いますが、今回は個人的に触りたいという気持ちをおさえ、冷静にStructuredStreamingを採用しました。
また、Kafkaはあくまでデータハブとしての役割のみ担当とした方が設計的にもわかりやすくなると思います。
KafkaConsumer、KafkaProducerとしてのSpark
structured-streaming-kafka-integrationを参照。
特にハマったことはありません。
kafkaをsuffixにつければ基本的にはkafkaの設定をすることができます。
offsetのコミットの管理など面倒なことはSparkがやってくれますので、ユーザは意識する必要はありません。逆に言うと、enable.auto.commit, auto.offset.reset 等の指定が不可です。
シリアライズ、デシリアライズはDataFrameの操作で行われることを想定しているため、同様に指定不可です。
今のところ、kafka.acks=-1、kafka.retries=10のみ指定しています。
なお、kafkaのパーティションがSparkでの入力のパーティションに該当してくれるようなので、適切にkafkaのメッセージkeyを設定しているもしくは何も設定していなければ、偏りはうまれないです。
また、図を見ていただけるとわかりますが、Sparkクラスタでの集計結果を再度kafkaの別のトピックにproduceしており、一見無駄に見えますが、これは、
アプリケーションエンジニアのためのApache Spark入門 単行本 p.194
Kafkaに出力しておき、そこから取得してアラームを通知するプロセスを用意することがシステム全体としてはメンテナンスをしやすく、今後通知したい先を変えたり、増やしたりすることも容易になりますので、今後の拡張を予測するなら、その方がいいと筆者は考えています。
に素直に従った形になります。
HDFSへの書き込み
SparkStructredStreamaingにて、HDFSに対して日付などでパーティションしながらParquet形式にて永続化しています。注意すべき点ですが、デフォルトの設定だと大量のparquetファイルが出来上がってしまいます。実際に指定したパスを確認すると、MesosUIで確認するExecutorの数と同数と思われる数のファイルがマイクロバッチごと(数秒以内)に出来上がり、驚愕しました。
既に書いたようにHadoopは小さい大量のファイルは得意としないので、よほど流量の多いトピックをconsumeするのでない限り、チューニングが必要かと思います。
このあたりの事情はSpark Streaming, output to Parquet and Too Many Small Output Filesに詳しく説明されてました。
まず、大量のファイルができてしまう理由ですが、
- DataFrameのpartitionごとに並列にparquetファイルを書き込む際、それぞれ異なるファイルに書き込む必要がある(HDFSは一つのブロックに同時に書き込みができない)
- StructuredStreamingはマイクロバッチごとにファイルをcloseする
のようです。
手の込んだことを避けて、設定値のみで対応するには、
-
triggerにて、明示的にマイクロバッチ間隔を多めに指定する。当然ですが、レイテンシは大きくなります -
coalesceにてパーティションを少なめに指定する
を行うしかないようです。
クラウドサービスという選択肢も
Amazon Kinesis Streams
Kafkaの代替となりえますが、特に調査しませんでした。SparkとのインテグレーションにおいてはKafkaが圧倒的ですし、fluentdのプラグイン等周辺ツールとのインテグレーションも充実しているため、特にKafka以外を検討する理由がなかったためです。
Amazon S3
HDFSの代替となりえます。HDFSは普段あまり意識しなくていいのですが、いざ障害がおきたら一番困る部分です。そのリスクがないという意味でかなりの安心感があります。S3はデータローカリティがなく、通信のオーバーヘッドがあるので遅いという情報がある一方、最近はネットワーク帯域が十分なので、(特にスループット重視のバッチ処理などの場合)そこまでのデメリットになりえないという話もあります。当社の場合、オンプレ環境が多く、ログをS3にため込む事例が今のところ少ないのですが、そうでない場合は、まずS3を検討するのではと思います。
なお、S3を検討される方は、Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)がおすすめです。私はリアルタイムで聞いてましたが、AWSの方の発表なのでそこは加味して参考にしましょう。
EMR
Amazonが提供するHadoop、Spark等のマネージドサービスです。圧倒的に環境を用意するまでが楽である一方、分析の度に動的にクラスタが割り当てられ、分析終了後ターミネートされる仕組みのため、自由な環境の選択は難しいようです。
ログデータがS3に既にあり、数か月以内などのスパンでSparkで分析したいといった場合は、間違いなく最初に検討するべきではとは思います。
その他参考情報
-
Hadoop
-
「Hadoopの時代は終わった」の意味を正しく理解する
- Hadoopが誕生してから現在に至るまでの歴史を、NoSQLの台頭などを絡めて非常にわかりやすく、説明してくれてます
- 「Hadoopって、Sparkに置き換わるって聞くのに、なんでHadoopって未だに聞くんだろ?」と思っている人にはちょうどいいいです
-
「Hadoopの時代は終わった」の意味を正しく理解する
-
Hbase
-
ユースケースで徹底検証! HBaseでIoT時代のビッグデータ管理機能を試す 記事一覧)
- 2時間ほどで全部よめます
- NoSQLにおけるHBaseの位置付け、およびHBaseの概要とアーキテクチャについてわかりやすく書いてあります。
-
ユースケースで徹底検証! HBaseでIoT時代のビッグデータ管理機能を試す 記事一覧)
-
Zookeeper
-
Apache ZooKeeperを内部解析してみる
- 4つほどの連載を30分ほどで読めますので、縁の下の力持ちのZookeeperが何をやってくれるのかをサクッと把握するにはよい
-
Apache ZooKeeperを内部解析してみる
-
Hadoop / Spark Conference Japan 2019で紹介されていた各社アーキテクチャ事例
-
LINE
- OASISというLINE社製のOSS紹介がメイン
- Hadoop(HDFS), Sparkという構成で、Hadoopクラスタ(メインのクラスタで、他のクラスタもあるが統合予定とのこと)は500ノード、30PB、150以上のHiveデータベース
-
SmartNews
- 2014年頃にアーキテクチャを刷新したとのこと。Hadoop / Spark Conference Japan 2014で古橋さんがPrestoを紹介していたのを機にPrestoを知ったらしい
- 前 S3 + MapReduce + mongoDB
- 後 S3 + Hive(バッチ処理) + Presto(リアルタイム処理)
-
ソフトバンク
- ログ基盤は、Kinesis, Fluentd(AutoScaling), Spark(EMR),S3
- 混雑マップは、Kinesis(ログ基盤とは異なるクラスタにコピー), Fluentd(AutoScaling), Spark(EMR),S3,ElasticSearch
-
Yahoo
- Yosegiという自社製フォーマットのOSS紹介がメイン
- Kafka,Hadoop(HDFS),Spark
-
LINE
OSSへのコントリビューション
ここ半年で、以下のOSSに初めて触れました。
- Apache Spark
- Apache Hadoop(HDFS)
- Apache Mesos
- Apache Kafka
- Fluentd
- Apache Zookeeper
- Ansible(ログ基盤の構成管理に利用)
触っていく中で、ハマって調査した際の気付きベースで、どれも些細な修正ではありますが、以下のようなコントリビュートをしました。
-
[SPARK-26339][SQL]Throws better exception when reading files that start with underscore
- アンダースコアをプレフィックスに持つファイルを読み込む際のSparkの挙動が不親切でしたので修正しました
-
Enable the setting of partition key
- fluent-plugin-kafkaの
partition key指定が無効になっていたので修正しました - ドキュメントに誤りがあったので修正しました
- fluent-plugin-kafkaの
-
Update lineinfile description
- Ansibleのlineinfileモジュールのドキュメントに実際の挙動と不整合がある箇所がありましたので、ドキュメントを修正しました
課題、取り組みたいところ
現状はあくまで試験導入なので、やれていないことはたくさんあります。
例えば、以下のようなものがありますが、興味がある方は是非当社に来て、助けてください笑
HiveMetastoreの導入
Sparkはそもそもストレージを持たず、あくまで計算フレームワークです。
様々なストレージを扱うことができますが、Hadoop互換のファイルシステム(HDFS, Amazon S3)に格納されたデータをテーブルとして抽象化して永続化したい場合は、HiveMetastoreが必要となります。
ただ本番運用するとなると、メタデータの格納にRDBが必須となるなど導入にハードルがあり、まだ導入できておりません。
現在は、生のParquetファイルとして扱っておりますが、データ型、パーティション等ありますし、特に不自由はないとは思いますが、やはりパスに依存するのは気持ち悪いです。
Kafka, HDFS等のメトリクス収集、および検知
例えば、Kafkaでいうと、Kafkaにレプリケーション不足のパーティション(UnderReplicatedPartitions)をまずはモニタリングするようにとあります。実際にモニタリングを実装する際には、Jolokia経由でJMXを利用してメトリクスを取得する例がApache Kafka 分散メッセージングシステムの構築と活用 (NEXT ONE)の8章にあり、非常に参考になりそうです。
アプリサーバにあるマスタ情報の分析基盤への連携
アプリ上のRDBにのみ存在するようなマスタ情報を分析に利用したいが、アプリサーバと分析基盤がネットワーク的に離れているなどの理由でレプリケーションが出来ないような場合にどのように連携するのが一番イケてるのか検討できてません。おそらく、Embulkあたりを利用するのでしょう。
おわりに
振り返ってみると色々盛り込みすぎた感は否めませんが、自分がハマったりわかりずらいと思ったものは同じように思っている人が多いだろうという仮説のもと、出来るだけたくさん書きました。
Hadoop, Spark界隈はあらゆるOSSが存在し、それぞれの役割がわかりずらく、全体を見通した理解というのが難しいと思います。自分自身も最初の数か月はなかなか理解できず、どのOSSを採用すべきなのかもわからず、非常につらい時期がありました。
ただ、その後はそれぞれのOSSの知識がつながり、急に霧が晴れたように理解できるようになりました。今回の記事が少しでも過去の自分のような人の助けになれれば幸いです。