はじめに
分散システムを勉強しているが、有名であるにも関わらず、3PC(Three Phase Commitの略)のまとまった情報を見つけることが難しかった。
3PCがあまり実用的でないという理由からだと思われるが、分散システムの素養としてちゃんと理解したいと思ったので、3PCを発表したと思われる論文などをもとに「3PCは2PCの何を解決し何を解決しないのか」という点を主軸に整理していく。
分散システムを学び初めて半年ほどしか経っておらず完全に素人であるので間違っている部分もあるかもしれない。ただ界隈でかなり信頼されていると思われる以下の情報を元に整理しているので基本的には正しいのではと思う。
参考情報には明記されておらず、正しいか自信がない部分について区別できるように「〜と思われる」のように斜線で書いていく。
-
- おそらく3PCを最初に論文にしたもの
- 一番詳しいしほぼこれを参考にしている
-
一つ前と同じ著者
-
これ自体はPaxosの説明だけど序盤に3PCに触れられている
-
p.24-32のあたり
-
- p.384-394のあたり
-
Database Internals: A Deep Dive into How Distributed Data Systems
- p.257-266のあたり
用語整理
最低限必要と思われる用語整理。後半の難しい用語は後の章において補足しているし、最悪理解しなくても大筋では問題ない。
- 2PC
- Two Phase Commitの略
- 3PC
- Three Phase Commitの略
- Coordinator
- 2PC/3PC等にてプロトコルを管理する役割
- Cohort
- Coordinator以外の役割
- なお、厳密には2PC/3PCにもCoordinator/Cohortと分けずに全ノードが同等であるものも存在するが、基本的に同じ議論が成立するはず。この記事では扱わない。
- Non Blocking Commit Protocol
- ノードの障害時にもCommit Protocolが処理を継続するもの
- 2PCは満たさないが3PCは条件付きで満たす
- Committable State
- 「全ノードがyes/noにてyesにvoteした」ことをノードが把握している状態
- 全ノードの状態ではなく、各ノードに対しての状態に言及していることに注意
- 状態遷移において、Non Blocking Commit ProtocolにするにはCommitable Stateが2つ以上存在しないといけないことが証明されている。2PCは1つ、3PCは2つ存在。
- Noncommittable State
- Committable Stateでないもの
- Abortableと必ずしもイコールにならないことに注意。イコールにならない例として、Committable StateではあるがまだCommitしていないノードが障害でのリカバリーによりAbortされる場合があげられる。
- Synchronous within one state transition
- Commit Protocolでの各ノードの状態遷移において、「最も進んでいるノードと最も遅れているノードの差が最大で1遷移分である」ことがどの瞬間においても成立すること
- 2PC/3PCは成立
- 有限オートマトンに登場する状態
- 論文に合わせて以下のように表現。添字
iにてノードiの状態を意味する。pは3PCのみ -
qinitial state -
wwait state -
aabort state -
ccommit state -
pprepare to commit state
- 論文に合わせて以下のように表現。添字
2PC/3PCの耐障害性
最初に「3PCは2PCの何を解決し何を解決しないのか」の結論のようなものを書いてしまう。
2PC自体はノード故障には保証がないCommit Protocolである。ただ、次の章に詳しく書くが、Cohortの障害には実装次第で対応が可能である。
一方、Coordinatorが故障した場合には基本的にはCoordinatorが復活するのを待つしかない。
正確には、新しいCoordinatorであるRecoveryノードを登場させてCommit Protocolを進ませることが可能なケースもあるし、不可能なケースもあるが、「Coordinatorが復活するのを待つ」とだけ説明しているケースが多い気がする。
一方、3PCはNon Blocking Commit Protocolなので、ノードの障害時にもCommit Protocolの処理を継続できる。
ただし、3PCに限らずそもそもNon Blocking Commit Protocolは「Perfect failure detector」があること(完璧な障害検出の仕組み)を前提とし、以下の仮定が必要になる。
- network partitionがない
- ネットワークの遅延に上限がある
- ノードのレスポンスタイムに上限がある。つまり、プロセスの一時停止等はない。
現実世界では、ノードが健全でも、ネットワーク遅延や処理遅延によりタイムアウトにより障害と判定されてしまう可能性があるので強い仮定をおいている。
また、3PCは「ノード故障した後にそのノードが復活することはない」ことを想定している。仮に復活した場合はいわゆるSplit Brainがおき、ノードの状態がinconsistent(あるノードはCommitし、あるノードはAbortする)になりえる。
これらの前提を専門用語で表現するとsynchronous network with crash-stop failuresとなるらしい。
まとめると、3PCは2PCのBlocking Commit Protocolである点を改善するが、強い仮定をおいており、そのわりにはオーバーヘッドが大きいので現実世界ではあまり使われていないようである。
2PC
2PCの有限オートマトンは以下。

特徴としては、
- 一度、commit/abortに遷移したら戻すことができない。不可逆である。
- cohortはyesを返却したら、後ほどcommitできることを保証しなければならない。
- coordinatorはcommit/abortを一度決断したら覆すことができない。
- 非循環であるため、全ノードは最終的に終了状態に遷移する。
-
cのみがcommitableである。 -
qとcのノードが同時に存在しえないため、Synchronous within one state transition
前章に書いたように、2PCはcommitableな状態が1つのみのため、Blocking Commit Protocolである。
ノード障害がおきたときの挙動をみていく。
なお、2PC、3PC両方に言えることだが、Coordinator、Cohortともに耐障害性のために各操作前にローカルのログに書き込むことを前提とする。
例えば、Coordinatorは最後にcommit/abortを全cohortに送る前にローカルのログにcommit/abortどちらに決定したかを書き込む。これにより一部のcohortにのみcommit/abortを送った後クラッシュしても、復旧時にまだ送ってないcohortに同じ決断を送ることが可能となる。
以降、実際に障害が起きたパターンをもとにどのように遷移途中のCommit Protocolを終了状態にもっていけるかを考えていく。
注意点として、2PC自体はノード故障にはそもそも対応できないプロトコルなので、2PCのプロトコル自体が~のようにリカバリせよと規定しているものではなく、実装として、~の故障パターンでは~のように対応できるくらいの感覚でいた方がいいと思っている。
ちなみに、以下の障害パターンが網羅的にまとまっているところがなかったので、一番整理するのに骨が折れた部分である。全てのパターンを挙げたつもりではある。
投票へのレスポンス前にCohortが故障
以下の通りabortさせればいいだけである。
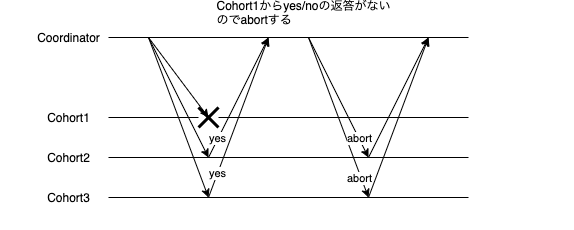
投票へyesレスポンス直後にCohortが故障
commitの決定は覆すことができないので、再送し続けるしかない。
復活したCohortは再送によりcommitを行うまで、ユーザからのリクエストを受け取ることはできない。なぜなら他のCohortとinconsistentな可能性があるからである(この例ではcohort1のみcommitできてない)。
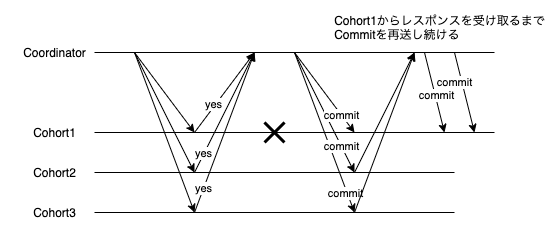
Commit/Abortを送る前にCoordinatorが故障
これ以降Coordinatorの故障が絡んでくる。以降全般でいえることだが、障害時にはRecoveryノードとして新しいCoordinatorが登場する前提で記載している。
「Database Internals」ではCohortが他のCohortに直接問い合わせる例が記載されている。2PCのプロトコル自体にはCohort同士の通信は存在しないが実装次第ではあり得るのだと思う。
いずれにしろ本質的にはあまり差異はないので、Cohort同士の通信のパターンは記載していない。
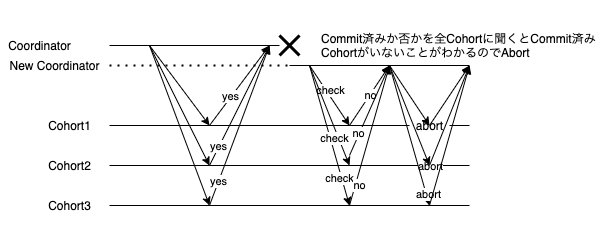
Commit/Abortを一部のCohortにのみ送っている状態でCoordinatorが故障
1つでもcommitを受け取っているCohortがいればcommit。そうでなければabortとする。
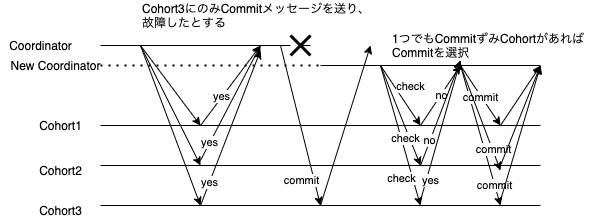
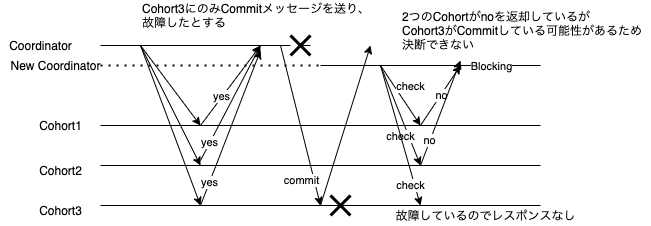
Commit/Abortを一部のCohortにのみ送っている状態でCoordinatorが故障 && Cohortが一台故障
これはBlockingする可能性のある場合である。
新しいCoordinatorは2つのCohortからcommitしていないという情報を得てはいるが、状況がわからないCohortのみcommitしている可能性が排除できないのでcommit/abortどちらにも倒すことができない。
仮にCohort2もcommitを受け取っていた場合はcommitに決断できたはずである。
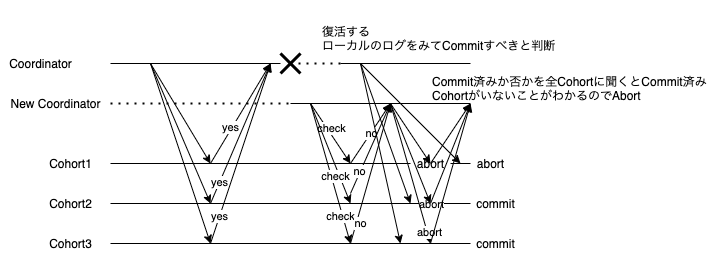
Coordinatorが故障したと思っていたらしていなかった
いわゆるSplit Brainである。前の章に記載したとおり2PCも3PCともに故障したノードが復旧するとInconsistentな最終状態になってしまう可能性がある。この例では、Cohort1のみabortされ、Cohort2/Cohort3はcommitされてしまっている。
3PC
3PCの有限オートマトンは以下。
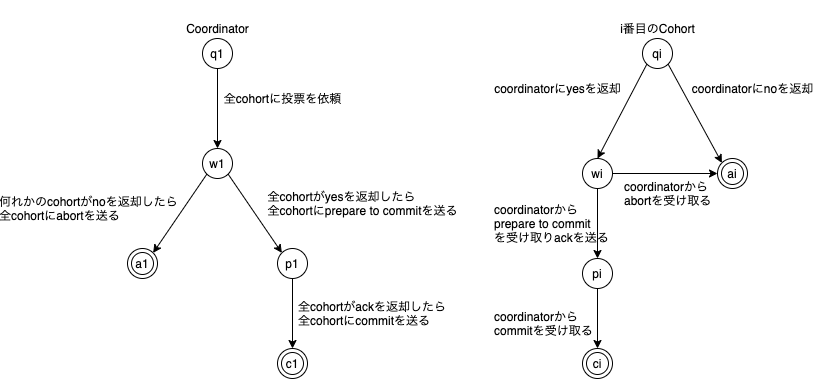
特徴は
- 一度、commit/abortに遷移したら戻すことができない。不可逆である。
-
qとpのノードおよびwとcが同時に存在しえないため、Synchronous within one state transition -
cとpがcommitableであり、隣接している。 cとaの両方に隣接しているノードがない
が挙げられる。注意点としては、abortする場合は2PCと同じフローを踏む。phaseが増えるのはcommitのときのみである。
3PCのrecovery
3PCのrecoveryは非常にシンプルである。以下に従う。
- 利用可能なノードから何らかの方法にてrecoveryを取りまとめるノードを選出
- localのstateが
pであれば、全ノードにまずpに移動するよう指令し、全ノードのackを待つ - localのstateが、
qorworaであればabort、porcであればcommit
1番目の選出方法は事前に順番を決めとくなり、投票するなりなんでもいい。
2番目の処理が必要なのはrecoveryにて障害が発生し、さらにそのrecoveryをした場合、元のrecoveryと異なるcommit/abortの決断をしないようにするためである。
この処理がなかった場合、recoveryノードがp->wと選ばれた場合にはcommit->abortと決断し、一貫性がなくなってしまう。
論文に書かれていたのは上記のように、判断を下すノードがローカルのログからのみ決断するが、他の参考情報では新Coordinatorが各Cohortに状態を聞き決断しているようだった。その場合も判定は上記と同様にされるはずである。
3PCがrecoveryできない例
「2PC/3PCの耐障害性」の章で記載したように、synchronous network with crash-stop failuresでのみ保証する。逆にいうと、条件が満たされないと安全なrecoveryに失敗する可能性がある。
例えば、prepare to commitのフェーズにて一部のCohortにcommitを送っている状態でCoordinatorが故障し、commitを受け立ったCohortとそうでないCohortでnetwork partitionが起きた場合は前者がcommit、後者がabortをおそらく選択することになり、安全なリカバリに失敗する。
network partition等を想定してか3PCにおいてCohortが各自でタイムアウト判定し、自分でcommit/abortの判断する亜種もあるようだ。
また、2PCの章で記載した「Coordinatorが故障したと思っていたらしていなかった」のケースも対応できない。
最後に、prepare to commitにて一部のCohortにてackが帰ってこない場合、有限オートマトンに存在しない遷移なのでおそらくプロトコル違反となるが、abortすることになる。
「n以下のノード障害にのみ対応すればいい」とシステム要件を定めることができれば、n+1ノードで3PCその他のノードは2PCを行えばよく、n+1ノードのackの返却が確認できた時点でフェーズを進めることができるのでこの可能性を少なくできる。
3PC導出の理論的背景
少し難しい話なので、読み飛ばしても問題ないが、せっかく論文を読んだので少し理論を紹介する。
Non Blocking Commit Protocolであること
は、全てのノードについて、1と2両方成立することと同値である。
- そのノード以外においてcommit状態とabort状態共存する瞬間がないこと
- そのノード以外においてcommit状態のノードがある場合は、そのノードはcommitableであること
上記が成立する。
-> は自明ですが、<-はそうではないと思う。論文に証明まではされてない。
上記の定理を認めてしまえば、自然に以下が成立する。
全ノードが1,2の両方の条件を満たすよう遷移していなくても、k(3以上)ノードが満たしていれば、k-1以下のノード故障という前提付きでNon Blockingのままである
複数ノードで同時に故障がおきても、条件を満たせているノードが1つでも生きていれば大丈夫ということ。
kを3以上としているのは、「Blockingされるには2ノード以上の故障が必要なこと」(2PCのblockingの例でも2ノード故障していた)が証明されており、1ノードの故障のみに耐えるならそもそも3PCにする必要がないためだと思われる。
例えば、CohortとCoordinator合わせて10ノードあったとして、prepare to commitに対して3ノードのackをCoordinatorが受け取った時点でcommitに遷移し、残り6ノードからのレスポンスを待たないと決めても、同時に3ノード故障しない限りNon Blockingのままである。
さらに、Synchronous within one state transition(2PC/3PCともに該当)であれば、自然に以下が成立する。
Non Blocking Commit Protocolであること
は、1と2両方成立することと同値である。
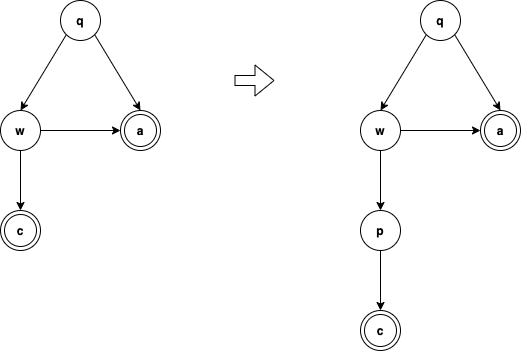
- commitとabortに隣接する状態がないこと
- commitに隣接する状態は常にcommitableであること
2PCであれば、wが1と2両方に違反する。
では、以下のように間に一個状態を挟めばいいのでは?と自然な流れで3PCに導くことができる。
まとめ
Paxos/Raftの前に基本である2PC/3PCをちゃんと理解したいと思っていたが、
Web/本ともに情報が綺麗にまとまっていない印象を受けたので結構な時間を割いて整理した。
主には自分の理解の整理のために書いたが、誰かの役に立ってくれるとうれしい。