目的
・スマホの育成ゲームの結果をデータベースにまとめたい。
・1つずつ手入力するのは手間である。
・AWSに画像上の文字を認識して出力するサービスがあるので利用してみる。
(日本語は無理そうだが、アルファベットや数字は問題なさそう。)
実行内容
①画像の準備(スマホでスクリーンショットで収集)
②画像の加工(OpenCVで大きさや不要な箇所を隠すなど実施)
→文字認識結果をまとめやすくするため
③AWSのRekognitionを使ってテキスト検出を行う。
④結果をデータベースにまとめる
記載内容
今回は③のRekognitionのテキスト検出について記述する。
参考
①Qiita記事(コードの内容)
https://qiita.com/banquet_kuma/items/560787299b83fb924ff7
②AWS_Rekognition公式入門ガイド
https://aws.amazon.com/jp/rekognition/resources/
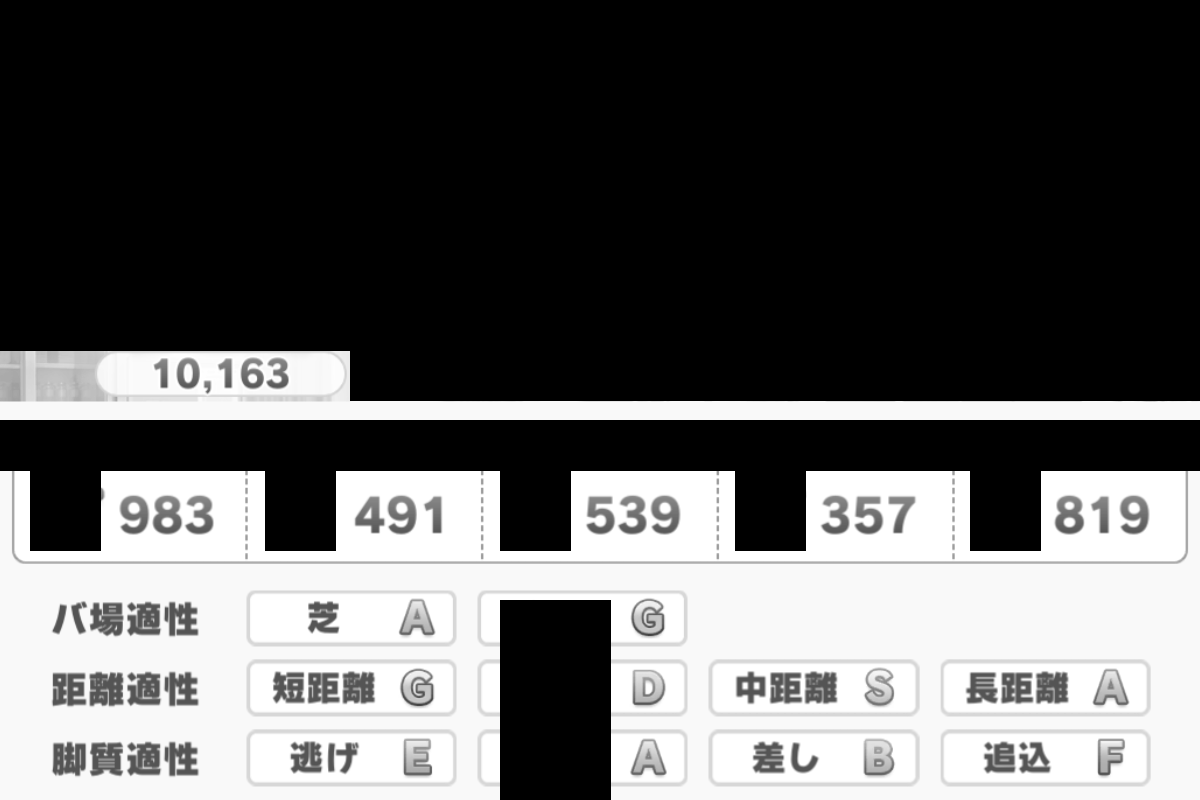
テキスト検出結果
加工した画像
出力結果

※一番最初には読み込んだ画像名を出力してます。(テキスト検出の範囲外)
「NN」という文字はどこから検出したか不明ですが、収集後削除すれば良し。
コード
code
import boto3
import configparser
region = "画像を保存しているS3のRegion"
bucket = "画像を保存しているS3のバケット名"
# アクセスキーが記述されているiniデータから必要な情報を抽出
ini = configparser.ConfigParser()
ini.read("読み込む.iniデータ","utf-8")
access_key = ini["AWS_KEY"]["aws_access_key_id"]
secret_key = ini["AWS_KEY"]["aws_secret_key"]
session = boto3.Session(aws_access_key_id=access_key,aws_secret_access_key=secret_key,region_name=region)
# S3に保存している画像一覧の取得
s3 = session.client("s3")
objects = s3.list_objects_v2(Bucket=bucket)
for filename in objects["Contents"]:
filename = filename["Key"]
idname = filename.split(".")[0].split("/")[1]
# idnameは読み込んだデータ名
data = [idname]
rekognition = session.client("rekognition")
# テキストの検出
response = rekognition.detect_text(Image={"S3Object":{"Bucket":bucket,"Name":filename}})
textDetections = response["TextDetections"]
for text in textDetections:
data.append(text["DetectedText"])
# 収集した結果を出力
print(data)
所感
・精度がよくて、満足。
・育成データの手入力が不要って、すごく便利!!
・知らないうちに世の中がさらに便利になっていく、、、驚きです。
※本記事には記載していないが、収集結果をデータベースにまとめて、欲しいデータをSELECT文で抽出してグラフで表示することまで行った。
以上。