はじめに
ローカルLLMがやってみたいが、たくさんのVRAMが乗ったGPU搭載の高性能PC、あるいはDGX SparkなどAI専用マシンを買うまでの勇気が出ない。AIエージェントなどでコーディング補間自体はGitHub Copilotなどが助けてくれるので普段の生活で困らなく、ローカルLLMの活用イメージがどうしても湧かないからだ。とはいえこの大AI時代においてそろそろ触ってもいいかなという気持ちもあり、Mac miniを購入した。触りながら、エッジ側にあるLLMが何に使えるか試していきたい。今回は手始めに各種ベンチマークを行った。
購入したMac mini
最低グレードのM4のMac miniに、盛れるだけRAMを持った。Mac miniはGPUに比べるとお値打ちなのと、ユニファイドメモリなので、RAMさえ増やしてしまえばVRAMを増やせるのも一つの魅力である。ローカルLLMとして利用する前提なので、家庭内のLANにつなげてSSHで接続するようにしている。
Mac miniのスペック
- 32GBユニファイドメモリ
- 256GB SSDストレージ
- 10コアCPU、10コアGPU、16コアNeural Engine搭載Apple M4チップ

LLM環境
LM StduioがGUI操作で簡単に導入できたが、CLI操作できたりAPIコールしやすい優位性からOllama環境に乗り換えた。手始めにOllamaのGUIからgpt-oss:20bを実行してみた結果を動画に撮った。
Ollama gpt-oss:20b reasoning effort=low
思考の深さ(reasoning effort)がLowだと爆速で回答がでてくる。HighだとGPU使用率が90%近くに貼り付いてしまう様子、全く使い物にならないわけではなさそう。
Ollama gpt-oss:20b reasoning effort=high
考えている時間が少し長く感じる。
LLMベンチマーク
本格的なベンチマークをするために、APIとしての応答レイテンシとトークン生成速度tok/sが何によって依存して変化するのか水準を振りながら確認してみた。実験の試行と生成結果のまとめはもちろんGitHub Copilotに任せた。実験はWindowsのPCから、Mac miniにAPIリクエストを投げて実施した。
Step1 パラメータ依存
num_ctxとnum_predictを変えながらテストした。それぞれコンテキスト長と生成トークン数に相当する。入力したプロンプトはすべて同じにした。
あなたは編集者です。『温度(temperature)』が文章生成に与える影響を、(1)要点、(2)例、(3)注意点 の3セクションで簡潔に説明してください。
-
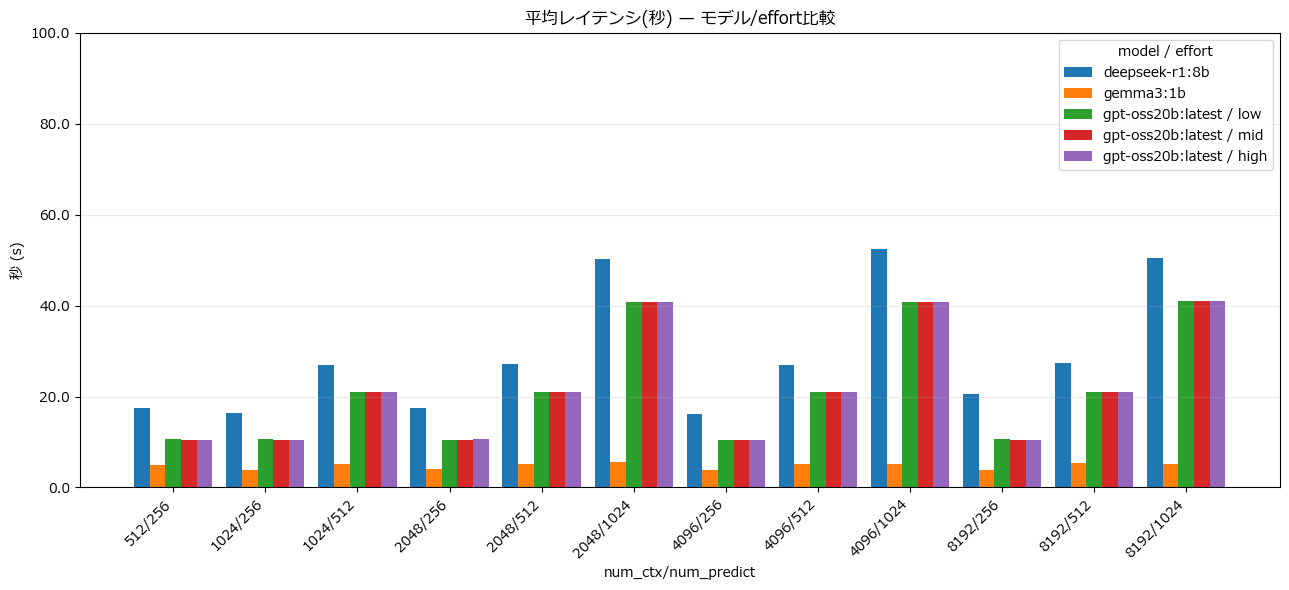
平均レイテンシ
-
平均生成速度(tok/s)
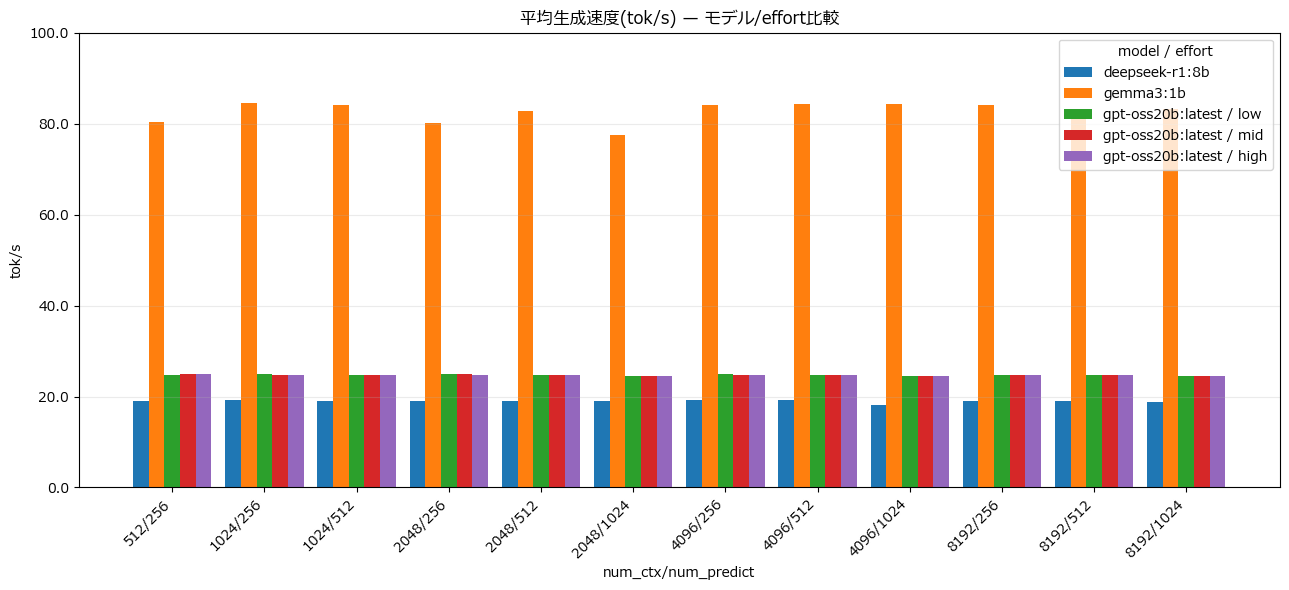
gemma3:1bの応答が飛びぬけて良い。軽量モデルだからこのような結果になるのは想定通りだが、パラメータを多く持つgpt-oss:20bよりdeepseek-r1:8bの方がレイテンシが悪く、トークン生成も遅いのは意外だった。
Step2 入力プロンプト依存
普段ChatGPTなどを使っているとき、長文タスクほどレイテンシは悪くなる印象があるので、コンテキストに応じた入力プロンプト文字数を設定し、実験を行った。
入力したプロンプト。メモ部分が繰り返しになっていてプロンプト長さを調整できるようになっている。
あなたは日本語の編集者です。以下の長文(メモ)を読み、最後の指示に従って回答してください。
※長文が続きます。内容の重複があっても構いません。
【メモ(長文)】
- ローカルLLM導入検討メモ: 運用コスト、レイテンシ、安定性、セキュリティ、モデル更新の手間を比較する。プロンプトは目的(要約/翻訳/抽出/推論)ごとに最適化し、評価指標(成功率、時間、生成速度)を明確にする。特に長い入力では、重要な前提を前半に置 き、後半は詳細やログとして付けると読み取りが安定しやすい。
- 追加メモ: 回答は『結論→根拠→補足』の順にする。曖昧な点は仮定を明記して進める。
- 具体例: 仕様変更の履歴、エラーログ、議事録をまとめて与え、要点を抽出して箇条書きにする。
- ローカルLLM導入検討メモ: 運用コスト、レイテンシ、安定性、セキュリティ、モデル更新の手間を比較する。プロンプトは目的(要約/翻訳/抽出/推論)ごとに最適化し、評価指標(成功率、時間、生成速度)を明確にする。特に長い入力では、重要な前提を前半に置 き、後半は詳細やログとして付けると読み取りが安定しやすい。
- 追加メモ: 回答は『結論→根拠→補足』の順にする。曖昧な点は仮定を明記して進める。
- 具体例: 仕様変更の履歴、エラーログ、議事録をまとめて与え、要点を抽出して箇条書きにする。
- ローカルLLM導入検討メモ: 運用コスト、レイテンシ、安定性、セキュリティ、モデル更新の手間を比較する。プロンプトは目的(要約/翻訳/抽出/推論)ごとに最適化し、評価指標(成功率、時間、生成速度)を明確にする。特に長い入力では、重要な前提を前半に置 き、後半は詳細やログとして付けると読み取りが安定しやすい。
- 追加メモ: 回答は『結論→根拠→補足』の順にする。曖昧な点は仮定を明記して進める。
- 具体例: 仕様変更の履歴、エラーログ、議事録をまとめて与え、要点を抽出して箇条書きにする。
- ローカルLLM導入検討メモ: 運用コスト、レイテンシ、安定性、セキュリティ、モデル更新の手間を比較する。プロンプトは目的(要約/翻訳/抽出/推論)ごとに最適化し、評価指標(成功率、時間、生成速度)を明確にする。特に長い入力では、重要な前提を前半に置 き、後半は詳細やログとして付けると読み取りが安定しやすい。
- 追加メモ: 回答は『結論→根拠→補足』の順にする。曖昧な点は仮定を明記して進める。
- 具体例: 仕様変更の履歴、エラーログ、議事録をまとめて与え、要点を抽出して箇条書きにする。
【指示】
1) 上のメモから重要ポイントを5つ、箇条書きで抜き出してください。
2) 最後に、全体の結論を日本語で2文にまとめてください。
出力形式: (1)箇条書き5点 → (2)結論2文
-
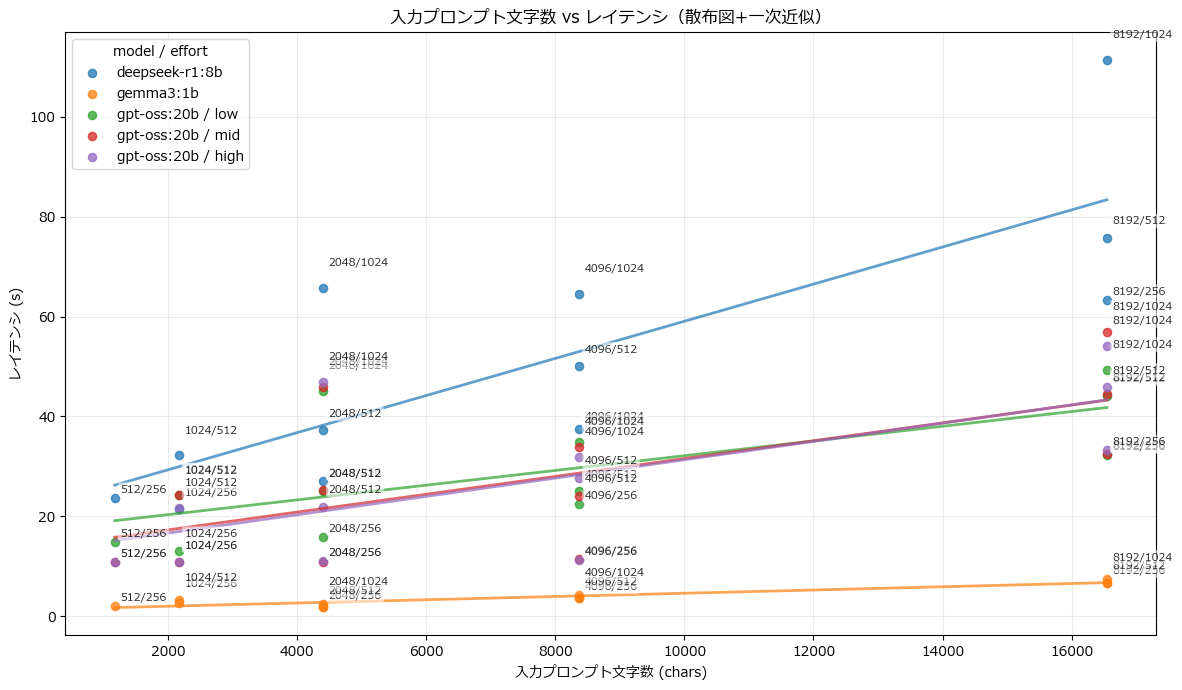
入力プロンプト文字数 vs レイテンシ
-
入力プロンプト文字数 vs 生成速度(tok/s)
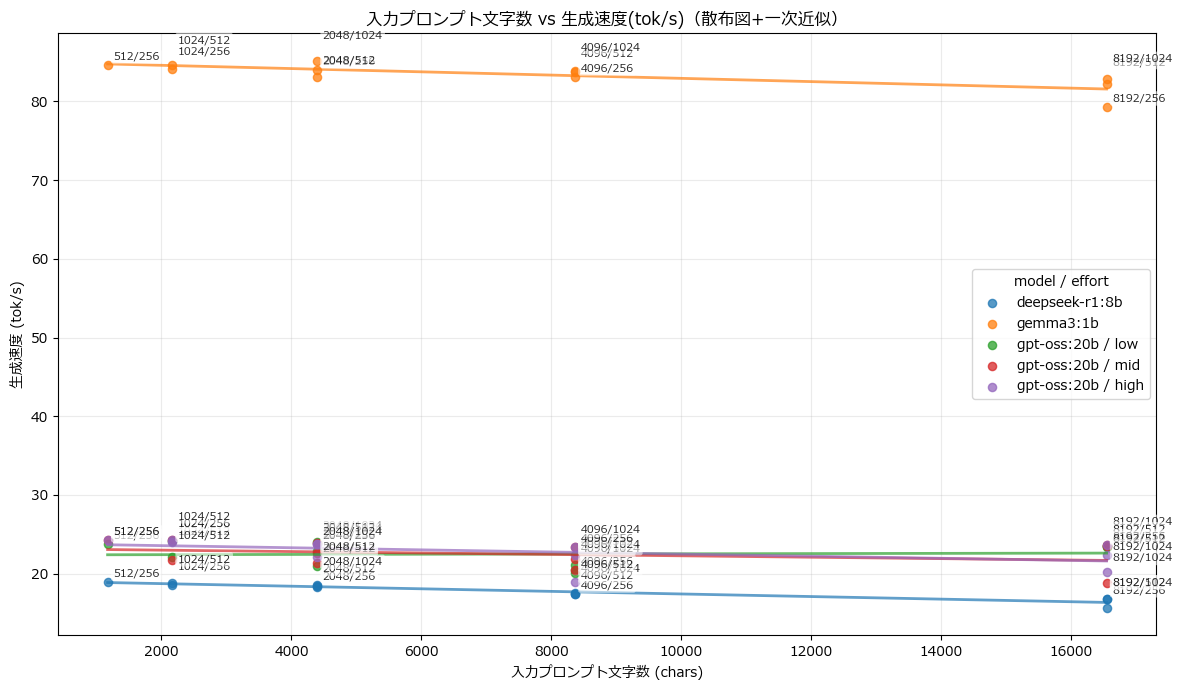
見立て通り、入力プロンプト文字数を多くすればするほど、レイテンシは悪くなり、生成速度が遅くなることは分かった。この実験においても、gpt-oss:20bよりdeepseek-r1:8bの方がレイテンシも悪く、トークン生成速度も遅く、逆転は起きなかった。トークン生成速度はプロンプトが長かろうとあまり関係はなく、GPU性能で律速しているのかもしれない。同じコンテキスト長、同じ入力プロンプトの場合は生成トークン数も絞った方がレイテンシの短縮が見られることも分かった。
最後に
モデル自体の優位性などは各モデルが発表されるたびにAAモデルに対してスコアが良いの悪いのだの発表されているが、ローカルLLMにおいては正答率に加え応答性が自分の感覚に合っているかどうかが大事であり使いやすさにも直結する。今回の試行を通じて有名どころのモデルのレイテンシ・トークン生成速度の肌感をまずは確認できてよかった。モデル内部のパラメータ数がモデル実行性能を決めるわけではないのも一つ発見であった。レイテンシがそれなりに短く、トークン生成が極端に遅くないモデルを使っていくことがインタラクティブな使い方をする場合は重要である。今回は使わなかったが、私の環境においてはgemma3:4bあたりがちょうどいいのではないか(そうなると32GBのRAMは余してしまうが、gpt-ossなどそれなりの巨大モデルも実行できたのでメモリは最大限盛っておいて良かった)。バッチジョブ的な非同期処理をするのであれば、月ごとのトークン制限もないので、レイテンシ結果をよく見つつ、好きなモデルを選んで使い倒せばよい。データの整理タスクや要約タスクなどが向いているように思う。動画においてGPUの使用率が上限でサチレーションしていることからも分かるように、M4チップ自体がボトルネックになっているはずなので(GPUスペックだけでなくメモリ帯域も)、現環境の活用イメージを考えながら次導入するマシンの最適解を考えたい。