記事の内容
Kerasを使った画像判定処理を行いました。
基本的には参考にさせていただいた記事を流用して作成したので、工夫した点のみメモとして記載します。
参考
環境
Python:3.7.4
Keras:2.3.4
tensorflow:1.13.1
構成
今回は「//ネコプラ//」というアイドルグループの画像を学習させました。
メンバーの画像をimgフォルダの下に各メンバーのフォルダを作成し、メンバー毎の画像を配置しました。
やったこと
画像取得
各メンバーの画像をTwitterから取得してきました。
import json
import config
from urllib import request
from requests_oauthlib import OAuth1Session
from time import sleep
# APIキー設定(別ファイルのconfig.pyで定義しています)
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
# 認証処理
twitter = OAuth1Session(CK, CS, AT, ATS)
# タイムライン取得エンドポイント
get_time_line_url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# 取得アカウント
necopla_menber = ['@yukino__NECOPLA', '@yurinaNECOPLA', '@riku_NECOPLA', '@miiNECOPLA', '@kaori_NECOPLA', '@sakuraNECOPLA', '@miriNECOPLA', '@renaNECOPLA']
necopla_name = {'@yukino__NECOPLA': 'yukino',
'@yurinaNECOPLA': 'yurina',
'@riku_NECOPLA': 'riku',
'@miiNECOPLA': 'mii',
'@kaori_NECOPLA': 'kaori',
'@sakuraNECOPLA': 'sakura',
'@miriNECOPLA': 'miri',
'@renaNECOPLA': 'rena'}
# パラメータの定義
params = {'q': '-filter:retweets',
'max_id': 0, # 取得を開始するID
'count': 200}
for menber in necopla_menber:
print(menber)
del params['max_id'] # 取得を開始するIDをクリア
# 最新の200件を取得/2回目以降はparams['max_id']に設定したIDより古いツイートを取得
index = 1
for j in range(100):
params['screen_name'] = menber
res = twitter.get(get_time_line_url, params=params)
print(params)
print(res.status_code)
if res.status_code == 200:
# API残り回数
limit = res.headers['x-rate-limit-remaining']
print("API remain: " + limit)
if limit == 1:
sleep(60*15)
n = 0
tweets = json.loads(res.text)
# 処理中のアカウントからツイートが取得出来なくなったらループを抜ける
print(len(tweets))
if len(tweets) == 0:
break
# ツイート単位で処理する
for tweet in tweets:
if 'extended_entities' in tweet:
for media in tweet['extended_entities']['media']:
url = media['media_url']
if url != '':
request.urlretrieve(url, './img/' + necopla_name[menber] + '/' + necopla_name[menber] + '_' + str(index).zfill(5) + url[-4:] )
index += 1
if len(tweets) >= 1:
print('max_id set')
params['max_id'] = tweets[-1]['id']-1
この処理で各メンバーのTwitterから画像を取得し、各メンバーの名前のフォルダ配下に画像を保存していきます。
画像の選別
次にやったことは画像の選別です。
多いメンバーだと1200枚、少ないメンバーだと300枚ほど取得出来ました。
その中から、告知や食べ物、ツーショット画像などを削除し、一人だけで写っている画像のみに手作業で絞りました。
絞り込み後の画像が一番枚数の少なかったメンバーに合わせて、各メンバーの画像を250枚ずつになるように更に絞りこみました。
画像判定
# coding:utf-8
import keras
from keras.preprocessing.image import load_img, img_to_array
from keras.callbacks import LambdaCallback
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Dense, Dropout, Activation, Flatten
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
from keras.models import model_from_json
from PIL import Image
import glob
necopla_name = ['yukino', 'yurina', 'riku', 'mii', 'kaori', 'sakura', 'miri', 'rena']
member_color = ['black', 'blue', 'red', 'green', 'magenta', 'aqua', 'purple', 'yellow']
image_size = 50
epochs = 100
hw = {"height":image_size, "width":image_size}
print('Load images...')
X = []
Y = []
for index, name in enumerate(necopla_name):
dir = "./image/" + name
files = glob.glob(dir + "/*.jpg")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
# 正解ラベルの形式を変換
Y = np_utils.to_categorical(Y, 8)
print('Create test data...')
# 学習用データとテストデータ
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.20)
print('Build model...')
# CNNを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(8))
model.add(Activation('softmax'))
# コンパイル
model.compile(loss='categorical_crossentropy',optimizer='SGD',metrics=['accuracy'])
json_string = ''
passage_array = [[0] * epochs] * len(necopla_name)
passage_array = []
for i in range(len(necopla_name)):
passage_array.append([0] * epochs)
# 学習終了時に実行
def on_train_end(logs):
print('----- saving model...')
model.save_weights("necopla_image_model" + 'w.hdf5')
model.save("necopla_image_model.hdf5")
# epoch終了時に実行
def on_epoch_end(epoch, logs):
print('## ' + str(epoch + 1) + '回目')
print('## yurina.jpg evaluate...')
img = load_img('yurina.jpg', target_size=(hw["height"], hw["width"]))
TEST = img_to_array(img) / 255
pred = model.predict(np.array([TEST]), batch_size=1, verbose=0)
print(">> 計算結果↓\n" + str(pred))
print(">> この画像は「" + necopla_name[np.argmax(pred)] + "」です。")
for i, p in enumerate(pred):
for j, pp in enumerate(p):
passage_array[j][epoch] = pp
print('## yukino.jpg evaluate...')
img = load_img('yukino.jpg', target_size=(hw["height"], hw["width"]))
TEST = img_to_array(img) / 255
pred = model.predict(np.array([TEST]), batch_size=1, verbose=0)
print(">> 計算結果↓\n" + str(pred))
print(">> この画像は「" + necopla_name[np.argmax(pred)] + "」です。")
print_callback = LambdaCallback(on_epoch_end=on_epoch_end,on_train_end=on_train_end)
# 訓練
history = model.fit(X_train, y_train, epochs=epochs, callbacks=[print_callback])
# 評価 & 評価結果出力
print(model.evaluate(X_test, y_test))
print('Output picture...')
x_datas = range(1, epochs+1)
y_datas = [ i / 10 for i in range(0, 10) ]
plt.xlim(1, epochs + 1)
plt.ylim(0, 1)
fig = plt.figure(figsize=(6, 4), dpi=72, facecolor="black", edgecolor="black", linewidth=2)
ax = plt.subplot(1, 1, 1)
for i, passage in enumerate(passage_array):
ax.plot(passage, color=member_color[i], label=necopla_name[i])
fig.savefig("passege.png", edgecolor="black")
plt.close()
基本的には参考にさせていただいたコードをほとんど流用させて頂いています。
工夫した点としては学習の過程がどうなるのかを見たかったので、以下2点処理を追加しました。
・epoch終了時に画像の判定を行う
・メンバー毎の計算結果をグラフで表示する
画像の判定は2名のメンバー画像をインプットとして与え、誰と判断されるかを確認します。
## 1回目
## yurina.jpg evaluate...
>> 計算結果↓
[[0.12650199 0.12684263 0.12742536 0.12854463 0.11904926 0.1264687
0.1201202 0.12504727]]
>> この画像は「mii」です。
## yukino.jpg evaluate...
>> 計算結果↓
[[0.13068683 0.12408765 0.1275352 0.12792543 0.12050408 0.13144182
0.11644448 0.1213745 ]]
>> この画像は「sakura」です。
Epoch 2/100
1600/1600 [==============================] - 12s 8ms/step - loss: 2.0785 - accuracy: 0.1456
## 2回目
## yurina.jpg evaluate...
>> 計算結果↓
[[0.12513563 0.12735145 0.12925902 0.12473622 0.12179873 0.12717892
0.11717195 0.12736808]]
>> この画像は「riku」です。
## yukino.jpg evaluate...
>> 計算結果↓
[[0.12863007 0.12423173 0.12936181 0.12356193 0.12369796 0.13277659
0.11367439 0.1240655 ]]
>> この画像は「sakura」です。
(略)
## 100回目
## yurina.jpg evaluate...
>> 計算結果↓
[[4.8989324e-10 8.2380754e-01 7.1863423e-07 3.2110822e-03 1.7282969e-01
1.9806185e-08 3.1989657e-05 1.1890962e-04]]
>> この画像は「yurina」です。
## yukino.jpg evaluate...
>> 計算結果↓
[[6.1400205e-01 2.8108407e-03 4.0069546e-04 1.0979763e-03 3.1650570e-01
6.4887889e-02 8.5816224e-05 2.0912322e-04]]
>> この画像は「yukino」です。
最初の方は間違った結果が返ってきていますが、100回目までいくと2枚とも正しい判定をするようになりました。
以下のグラフが各epoch終了時の計算結果をグラフ化したものになります。
グラフは「yurina」さんの画像の判定結果のみをグラフ化しています。
グラフの青が「yurina」さん、ピンクが「kaori」さんです。
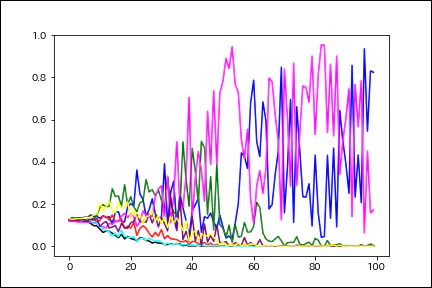
期待していた結果としては青の線が1に向かって収束していくようなグラフを期待していました。
この結果を見ると、現在の学習データではこの2人の判定が難しい状態になっていることが分かります。
感想
素直に面白いです。
とりあえず、勉強のために作ってみようと思い調べながら実装してみましたが、精度を高める工夫などは書籍などを読みながら更に学習してみようと思います。