はじめに
DQNをKerasとTensorFlowとOpenAI Gymで実装するという大変素晴らしい記事を読んで実際にDQNを動かしてみたくなった。強化学習はそれほど興味がなかったんだけどブロック崩しがだんだんかしこくなっていくのを実際に見てみたいなと思って。
で、手持ちのMacで動かすところまでやったんだけど仕事に使ってるPCなので長時間学習させられる環境じゃない。学習用に放置しておける環境をつくるため、Ubuntu LinuxでOpenAI Gym&TensorFlow&Kerasの環境をセットアップして記事のサンプルコードであるelix-tech/dqnを動かすところまでやってみた。コードがPython3.xじゃ動かなくて修正したりしたので、せっかくなのでメモっておきます。
セットアップ
Ubuntu 16.04をインストール直後の状態から。
まずはUbuntuをアップグレードして必要なモジュールをインストールする。
cd ~
sudo apt-get update
sudo apt-get upgrade
sudo apt-get -y install git gcc make openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev python3-tk tk-dev python-tk libfreetype6-dev python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
次にpyenv, virtualenvをインストールする
git clone https://github.com/yyuu/pyenv.git ~/.pyenv
git clone https://github.com/yyuu/pyenv-virtualenv.git ~/.pyenv/plugins/pyenv-virtualenv
~/.bash_profile を以下のように記述する。
# pyenv
export PYENV_ROOT=$HOME/.pyenv
export PATH=$PYENV_ROOT/bin:$PATH
eval "$(pyenv init -)"
# virtualenv
eval "$(pyenv virtualenv-init -)"
export PYENV_VIRTUALENV_DISABLE_PROMPT=1
.bash_profileを反映する。
source ~/.bash_profile
Python仮想環境をつくる
pyenv install 3.5.3
pyenv virtualenv 3.5.3 gym
pyenv activate gym
python -V
Python 3.5.3
TensorFlow、Keras他必要なモジュールをインストールする。とりあえず今回はGPUが使えない仮想マシンで立てたのでTensorFlowはCPUにしました。tensorflow-gpuをインストールする場合はこちらを参照するなどして別途CUDAの環境を整えてください。
pip install numpy
pip install h5py
pip install pillow
pip install matplotlib
pip install pandas
pip install ipython
pip install scipy
pip install sympy
pip install nose
pip install scikit-image
pip install tensorflow
pip install keras
OpenAI Gymをインストールする。今回の訓練環境はATARIのゲームのみをインストールした。全部入れたいときはpip install -e '.[all]'すればいいみたい。
git clone https://github.com/openai/gym.git
cd gym
pip install -e .
pip install -e '.[atari]'
うまくセットアップできたか確認するため、インベーダーゲームを動かしてみる。
cd ..
vi invaders.py
import gym
env = gym.make('SpaceInvaders-v0')
env.reset()
for _ in range(10000):
env.render()
env.step(env.action_space.sample())
python invaders.py
動いた。
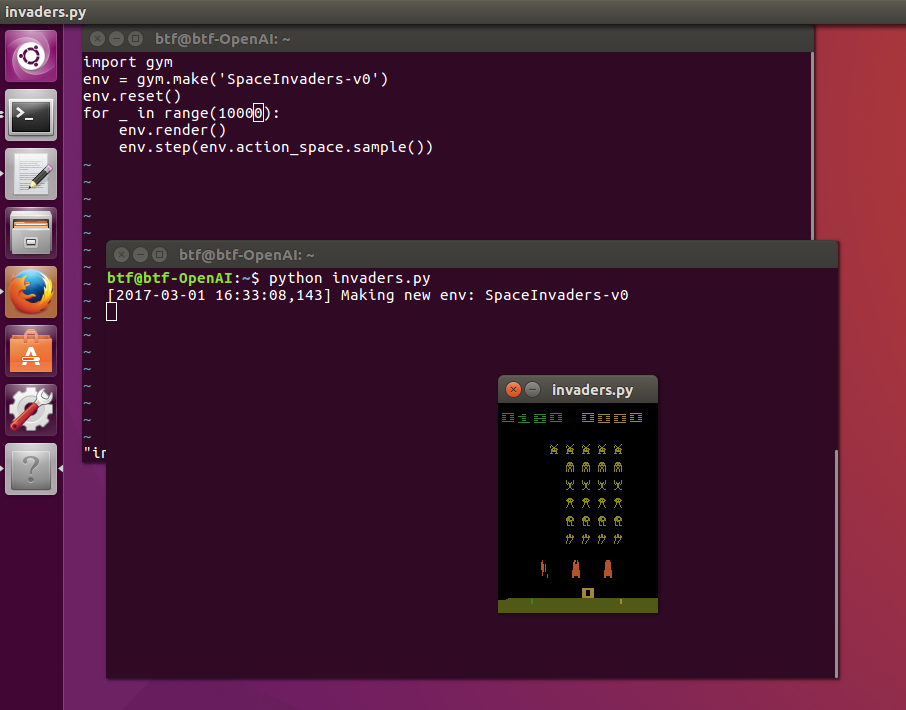
OpenAI Gymがちゃんと動いたので、DQNをKerasとTensorFlowとOpenAI Gymで実装するのコードを動かしてみる。
まずは~/.keras/keras.jsonを編集して配列順をTheano仕様に変更する。上記のコードがそうなっているため。
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"backend": "tensorflow",
"floatx": "float32"
}
次に、コードをcloneする。
git clone https://github.com/elix-tech/dqn
cd dqn
dqn.pyを以下のコードにまるごと置き換える。gistにも貼っときました。
変更してるのは主に以下が理由。
-
TensorFlow1.0とそれ以前とでクラス体系とメソッド名が変わったので大量にAttributeErrorが出る。TensorFlow の "AttributeError: 'module' object has no attribute 'xxxx'" エラーでつまづいてしまう人のための移行ガイドを参考にメソッド名を書き換えた。
あと、dqn.pyの37行目をTRAIN = Falseとしておく。とりあえず動くかテストモードで確認するため。
# coding:utf-8
import os
import gym
import random
import numpy as np
import tensorflow as tf
from collections import deque
from skimage.color import rgb2gray
from skimage.transform import resize
from keras.models import Sequential
from keras.layers import Convolution2D, Flatten, Dense
KERAS_BACKEND = 'tensorflow'
ENV_NAME = 'Breakout-v0' # Environment name
FRAME_WIDTH = 84 # Resized frame width
FRAME_HEIGHT = 84 # Resized frame height
NUM_EPISODES = 12000 # Number of episodes the agent plays
STATE_LENGTH = 4 # Number of most recent frames to produce the input to the network
GAMMA = 0.99 # Discount factor
EXPLORATION_STEPS = 1000000 # Number of steps over which the initial value of epsilon is linearly annealed to its final value
INITIAL_EPSILON = 1.0 # Initial value of epsilon in epsilon-greedy
FINAL_EPSILON = 0.1 # Final value of epsilon in epsilon-greedy
INITIAL_REPLAY_SIZE = 20000 # Number of steps to populate the replay memory before training starts
NUM_REPLAY_MEMORY = 400000 # Number of replay memory the agent uses for training
BATCH_SIZE = 32 # Mini batch size
TARGET_UPDATE_INTERVAL = 10000 # The frequency with which the target network is updated
ACTION_INTERVAL = 4 # The agent sees only every 4th input
TRAIN_INTERVAL = 4 # The agent selects 4 actions between successive updates
LEARNING_RATE = 0.00025 # Learning rate used by RMSProp
MOMENTUM = 0.95 # Momentum used by RMSProp
MIN_GRAD = 0.01 # Constant added to the squared gradient in the denominator of the RMSProp update
SAVE_INTERVAL = 300000 # The frequency with which the network is saved
NO_OP_STEPS = 30 # Maximum number of "do nothing" actions to be performed by the agent at the start of an episode
LOAD_NETWORK = False
TRAIN = False
SAVE_NETWORK_PATH = 'saved_networks/' + ENV_NAME
SAVE_SUMMARY_PATH = 'summary/' + ENV_NAME
NUM_EPISODES_AT_TEST = 30 # Number of episodes the agent plays at test time
class Agent():
def __init__(self, num_actions):
self.num_actions = num_actions
self.epsilon = INITIAL_EPSILON
self.epsilon_step = (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORATION_STEPS
self.t = 0
self.repeated_action = 0
# Parameters used for summary
self.total_reward = 0
self.total_q_max = 0
self.total_loss = 0
self.duration = 0
self.episode = 0
# Create replay memory
self.replay_memory = deque()
# Create q network
self.s, self.q_values, q_network = self.build_network()
q_network_weights = q_network.trainable_weights
# Create target network
self.st, self.target_q_values, target_network = self.build_network()
target_network_weights = target_network.trainable_weights
# Define target network update operation
self.update_target_network = [target_network_weights[i].assign(q_network_weights[i]) for i in range(len(target_network_weights))]
# Define loss and gradient update operation
self.a, self.y, self.loss, self.grad_update = self.build_training_op(q_network_weights)
self.sess = tf.InteractiveSession()
self.saver = tf.train.Saver(q_network_weights)
self.summary_placeholders, self.update_ops, self.summary_op = self.setup_summary()
self.summary_writer = tf.summary.FileWriter(SAVE_SUMMARY_PATH, self.sess.graph)
if not os.path.exists(SAVE_NETWORK_PATH):
os.makedirs(SAVE_NETWORK_PATH)
self.sess.run(tf.global_variables_initializer())
# Load network
if LOAD_NETWORK:
self.load_network()
# Initialize target network
self.sess.run(self.update_target_network)
def build_network(self):
model = Sequential()
model.add(Convolution2D(32, 8, 8, subsample=(4, 4), activation='relu', input_shape=(STATE_LENGTH, FRAME_WIDTH, FRAME_HEIGHT)))
model.add(Convolution2D(64, 4, 4, subsample=(2, 2), activation='relu'))
model.add(Convolution2D(64, 3, 3, subsample=(1, 1), activation='relu'))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(self.num_actions))
s = tf.placeholder(tf.float32, [None, STATE_LENGTH, FRAME_WIDTH, FRAME_HEIGHT])
q_values = model(s)
return s, q_values, model
def build_training_op(self, q_network_weights):
a = tf.placeholder(tf.int64, [None])
y = tf.placeholder(tf.float32, [None])
# Convert action to one hot vector
a_one_hot = tf.one_hot(a, self.num_actions, 1.0, 0.0)
q_value = tf.reduce_sum(tf.multiply(self.q_values, a_one_hot), reduction_indices=1)
# Clip the error, the loss is quadratic when the error is in (-1, 1), and linear outside of that region
error = tf.abs(y - q_value)
quadratic_part = tf.clip_by_value(error, 0.0, 1.0)
linear_part = error - quadratic_part
loss = tf.reduce_mean(0.5 * tf.square(quadratic_part) + linear_part)
optimizer = tf.train.RMSPropOptimizer(LEARNING_RATE, momentum=MOMENTUM, epsilon=MIN_GRAD)
grad_update = optimizer.minimize(loss, var_list=q_network_weights)
return a, y, loss, grad_update
def get_initial_state(self, observation, last_observation):
processed_observation = np.maximum(observation, last_observation)
processed_observation = np.uint8(resize(rgb2gray(processed_observation), (FRAME_WIDTH, FRAME_HEIGHT)) * 255)
state = [processed_observation for _ in range(STATE_LENGTH)]
return np.stack(state, axis=0)
def get_action(self, state):
action = self.repeated_action
if self.t % ACTION_INTERVAL == 0:
if self.epsilon >= random.random() or self.t < INITIAL_REPLAY_SIZE:
action = random.randrange(self.num_actions)
else:
action = np.argmax(self.q_values.eval(feed_dict={self.s: [np.float32(state / 255.0)]}))
self.repeated_action = action
# Anneal epsilon linearly over time
if self.epsilon > FINAL_EPSILON and self.t >= INITIAL_REPLAY_SIZE:
self.epsilon -= self.epsilon_step
return action
def run(self, state, action, reward, terminal, observation):
next_state = np.append(state[1:, :, :], observation, axis=0)
# Clip all positive rewards at 1 and all negative rewards at -1, leaving 0 rewards unchanged
reward = np.sign(reward)
# Store transition in replay memory
self.replay_memory.append((state, action, reward, next_state, terminal))
if len(self.replay_memory) > NUM_REPLAY_MEMORY:
self.replay_memory.popleft()
if self.t >= INITIAL_REPLAY_SIZE:
# Train network
if self.t % TRAIN_INTERVAL == 0:
self.train_network()
# Update target network
if self.t % TARGET_UPDATE_INTERVAL == 0:
self.sess.run(self.update_target_network)
# Save network
if self.t % SAVE_INTERVAL == 0:
save_path = self.saver.save(self.sess, SAVE_NETWORK_PATH + '/' + ENV_NAME, global_step=(self.t))
print('Successfully saved: ' + save_path)
self.total_reward += reward
self.total_q_max += np.max(self.q_values.eval(feed_dict={self.s: [np.float32(state / 255.0)]}))
self.duration += 1
if terminal:
# Write summary
if self.t >= INITIAL_REPLAY_SIZE:
stats = [self.total_reward, self.total_q_max / float(self.duration),
self.duration, self.total_loss / (float(self.duration) / float(TRAIN_INTERVAL))]
for i in range(len(stats)):
self.sess.run(self.update_ops[i], feed_dict={
self.summary_placeholders[i]: float(stats[i])
})
summary_str = self.sess.run(self.summary_op)
self.summary_writer.add_summary(summary_str, self.episode + 1)
# Debug
if self.t < INITIAL_REPLAY_SIZE:
mode = 'random'
elif INITIAL_REPLAY_SIZE <= self.t < INITIAL_REPLAY_SIZE + EXPLORATION_STEPS:
mode = 'explore'
else:
mode = 'exploit'
print('EPISODE: {0:6d} / TIMESTEP: {1:8d} / DURATION: {2:5d} / EPSILON: {3:.5f} / TOTAL_REWARD: {4:3.0f} / AVG_MAX_Q: {5:2.4f} / AVG_LOSS: {6:.5f} / MODE: {7}'.format(
self.episode + 1, self.t, self.duration, self.epsilon,
self.total_reward, self.total_q_max / float(self.duration),
self.total_loss / (float(self.duration) / float(TRAIN_INTERVAL)), mode))
self.total_reward = 0
self.total_q_max = 0
self.total_loss = 0
self.duration = 0
self.episode += 1
self.t += 1
return next_state
def train_network(self):
state_batch = []
action_batch = []
reward_batch = []
next_state_batch = []
terminal_batch = []
y_batch = []
# Sample random minibatch of transition from replay memory
minibatch = random.sample(self.replay_memory, BATCH_SIZE)
for data in minibatch:
state_batch.append(data[0])
action_batch.append(data[1])
reward_batch.append(data[2])
next_state_batch.append(data[3])
terminal_batch.append(data[4])
# Convert True to 1, False to 0
terminal_batch = np.array(terminal_batch) + 0
target_q_values_batch = self.target_q_values.eval(feed_dict={self.st: np.float32(np.array(next_state_batch) / 255.0)})
y_batch = reward_batch + (1 - terminal_batch) * GAMMA * np.max(target_q_values_batch, axis=1)
loss, _ = self.sess.run([self.loss, self.grad_update], feed_dict={
self.s: np.float32(np.array(state_batch) / 255.0),
self.a: action_batch,
self.y: y_batch
})
self.total_loss += loss
def setup_summary(self):
episode_total_reward = tf.Variable(0.)
tf.summary.scalar(ENV_NAME + '/Total Reward/Episode', episode_total_reward)
episode_avg_max_q = tf.Variable(0.)
tf.summary.scalar(ENV_NAME + '/Average Max Q/Episode', episode_avg_max_q)
episode_duration = tf.Variable(0.)
tf.summary.scalar(ENV_NAME + '/Duration/Episode', episode_duration)
episode_avg_loss = tf.Variable(0.)
tf.summary.scalar(ENV_NAME + '/Average Loss/Episode', episode_avg_loss)
summary_vars = [episode_total_reward, episode_avg_max_q, episode_duration, episode_avg_loss]
summary_placeholders = [tf.placeholder(tf.float32) for _ in range(len(summary_vars))]
update_ops = [summary_vars[i].assign(summary_placeholders[i]) for i in range(len(summary_vars))]
summary_op = tf.summary.merge_all()
return summary_placeholders, update_ops, summary_op
def load_network(self):
checkpoint = tf.train.get_checkpoint_state(SAVE_NETWORK_PATH)
if checkpoint and checkpoint.model_checkpoint_path:
self.saver.restore(self.sess, checkpoint.model_checkpoint_path)
print('Successfully loaded: ' + checkpoint.model_checkpoint_path)
else:
print('Training new network...')
def get_action_at_test(self, state):
action = self.repeated_action
if self.t % ACTION_INTERVAL == 0:
if random.random() <= 0.05:
action = random.randrange(self.num_actions)
else:
action = np.argmax(self.q_values.eval(feed_dict={self.s: [np.float32(state / 255.0)]}))
self.repeated_action = action
self.t += 1
return action
def preprocess(observation, last_observation):
processed_observation = np.maximum(observation, last_observation)
processed_observation = np.uint8(resize(rgb2gray(processed_observation), (FRAME_WIDTH, FRAME_HEIGHT)) * 255)
return np.reshape(processed_observation, (1, FRAME_WIDTH, FRAME_HEIGHT))
def main():
env = gym.make(ENV_NAME)
agent = Agent(num_actions=env.action_space.n)
if TRAIN: # Train mode
for _ in range(NUM_EPISODES):
terminal = False
observation = env.reset()
for _ in range(random.randint(1, NO_OP_STEPS)):
last_observation = observation
observation, _, _, _ = env.step(0) # Do nothing
state = agent.get_initial_state(observation, last_observation)
while not terminal:
last_observation = observation
action = agent.get_action(state)
observation, reward, terminal, _ = env.step(action)
# env.render()
processed_observation = preprocess(observation, last_observation)
state = agent.run(state, action, reward, terminal, processed_observation)
else: # Test mode
# env.monitor.start(ENV_NAME + '-test')
for _ in range(NUM_EPISODES_AT_TEST):
terminal = False
observation = env.reset()
for _ in range(random.randint(1, NO_OP_STEPS)):
last_observation = observation
observation, _, _, _ = env.step(0) # Do nothing
state = agent.get_initial_state(observation, last_observation)
while not terminal:
last_observation = observation
action = agent.get_action_at_test(state)
observation, _, terminal, _ = env.step(action)
env.render()
processed_observation = preprocess(observation, last_observation)
state = np.append(state[1:, :, :], processed_observation, axis=0)
# env.monitor.close()
if __name__ == '__main__':
main()
実行する。
python dqn.py
動いた。
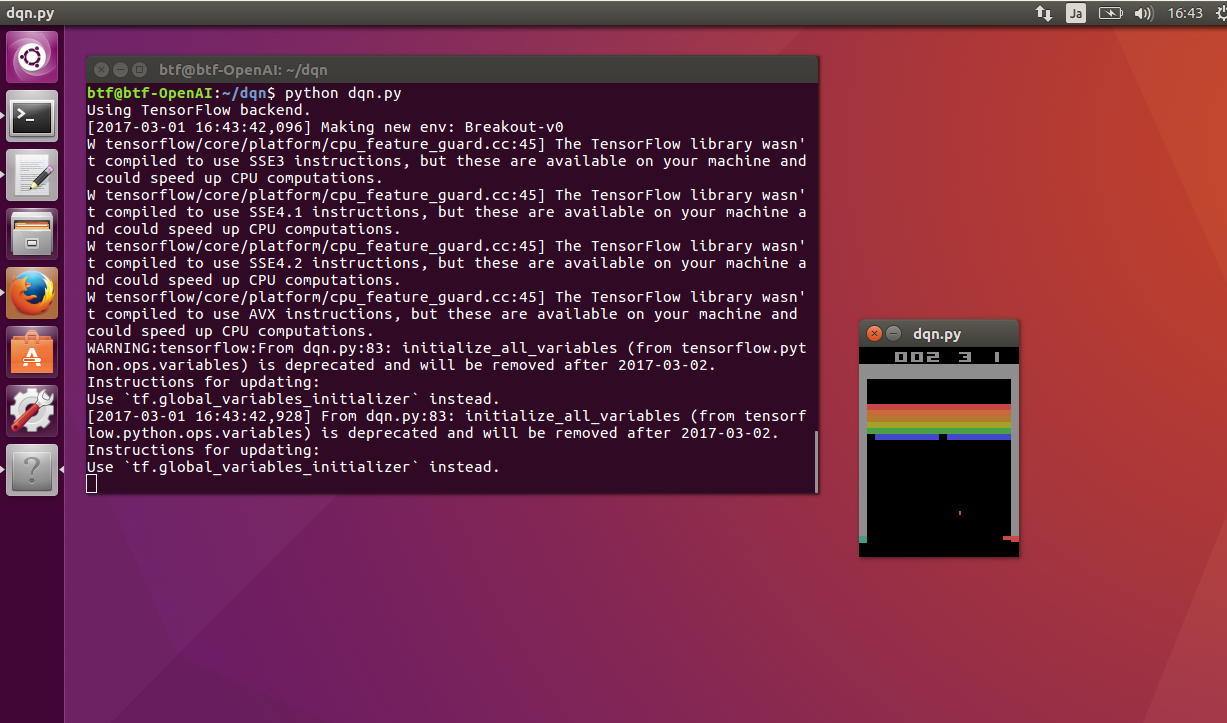
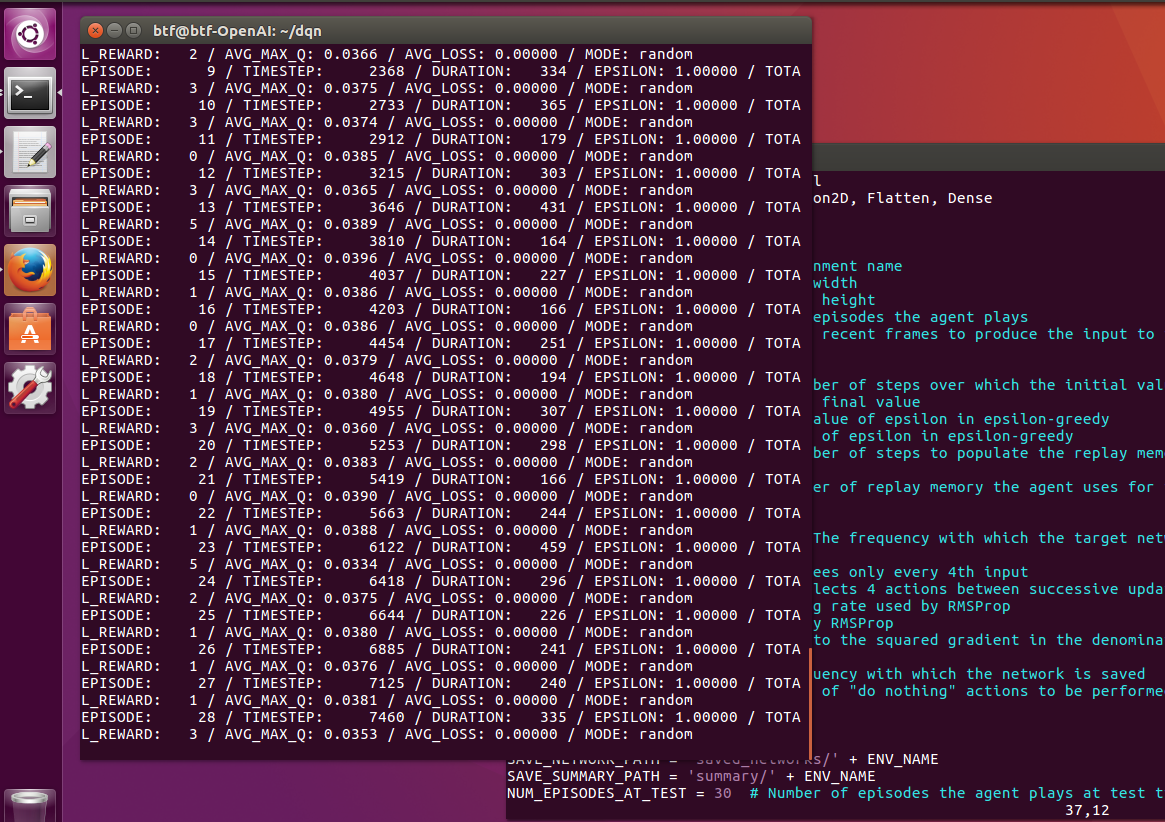
強化学習をさせてみる。dqn.pyの37行目をTRAIN = Trueとして実行する。
動いた。ちゃんと学習してるみたい。遅いけど。
まとめ
DQNの理論とかコードの中身とかほとんどわかってないけど動かすことができたのでAIにゲームを学習させながらボクもDQNの学習をしていこうと思います。あらためて記事ちゃんと読も。