はじめに
最近、AIについて調べていると、RAG(ラグと読みます)と言う単語をよく目にします。RAGについて皆さんはどの程度理解していますでしょうか?
本稿では、「RAGって何?」「なんでRAGが注目されているの?」といった疑問に答えていこうと思います。
目次
RAGとは
RAGとは、Retrieval-Augmented Generationの略です。日本語で言うと、検索拡張生成です。RAGの説明を一言ですると、「LLM (Large Language Model: 大規模言語モデル) が持つ内部知識を補うために外部知識を活用する」というフレームワークです。

RAGの全体像。この記事を読み切った後にもう一度戻ってこの図を見てみてください。RAGに対する解像度が上がると思います。
上の図を参考に、具体的な処理について説明します。
Retrieve
このフェーズでは、質問の回答に必要な情報を検索・取得します。
どこから情報を取得するのでしょうか?高度なRAGの場合はWeb検索するものもありますが、一般的には予め用意しておいたデータベース (外部知識)です。 具体的には、SQLデータベース・ベクトルデータベース・ナレッジグラフなど様々あり、組み合わせる場合もあります。
これらのデータベースを用いて、質問を考慮して検索し、回答のヒントとなる情報を取得します。
Augment
このフェーズでは、取得した情報と質問を組み合わせてLLMに入力するプロンプトを作成します。 プロンプトとは、ユーザーが入力する指示文のことを指します。 例えば、ChatGPTに日本の総理大臣の名前を教えてもらうために、「現在の日本の総理大臣の名前を教えてください。」と入力した場合、この入力文がプロンプトとなります。
RAGでは、プロンプトは質問 + 取得した情報で構成されます。
Generate
このフェーズでは、質問に対する回答を生成します。 ChatGPTに質問するのと同じ感覚です。1つだけ違うことがあるとすると、Augumentで作成したプロンプトを使うということです。
大まかな仕組みの説明はここまでです。ここからは、より具体的に想像するために実際の例を交えながらRAGについて説明します。
次章以降でも説明しますが、RAGの主な目的は、LLMが答えられなかった質問に答えられるようにすることです。
例えば、現在A駅におり、B駅に12:00に着きたいとします。ChatGPTに「現在、A駅にいます。12:00にB駅に行きたいです。何時発の電車に乗れば良いですか?」と聞いてもおそらく答えてくれません。

品川 → 名古屋の具体例 (GPT-4oで回答生成)。一見答えているように見えますが、このような時間に出発する新幹線はないです。※2025/2/6の時刻表を参照
しかし、プロンプトに質問文と一緒に「A駅 → B駅の時刻表」も書いたどうなるでしょうか?おそらく、正確に答えてくれます。

時刻表 (Context)を書き加えた場合の例 (GPT-4oで回答生成)。正確に答えることができています。※2025/2/6の時刻表を参照
「A駅 → B駅の時刻表」のことをContextと呼ぶのですが、RAGではこのContextを質問文に従って外部のデータベースやWebから取得します。 そうすることで、LLMが答えることができなかった質問にも柔軟に答えることができるようになるのです。
したがって、「LLMが持つ内部知識を補うために外部知識を活用する」というフレームワークであると言えるのです。
LLMの課題
ここまで、RAGの概要について説明してきました。RAGの存在意義についての話をする前にLLMの課題について触れておこうと思います。
この2,3年の間にLLMは生成AIという名で大きく成長しました。その筆頭が、OpenAIのGPT-4、GoogleのGemini、AnthropicのClaudeではないでしょうか。そして、2025年1月には新生の如くDeepSeekが登場しました。このような素晴らしいモデルを誰もが簡単に使えるようになった今、LLMはまだ課題を抱えているのでしょうか?
答えはYesです。LLMにはまだ多くの課題が存在します。 細かいものを上げると色々あるのですが、大きく3つあります。
- 知らないことには答えられない
- 古い学習データへの依存
- ハルシネーションの存在
それぞれについて軽く話していきたいと思います。
1. 知らないことには答えられない
LLMは人間と同じで、学習していない内容については答えられません。 例えば、小学生に$P(x_n|x_1,x_2,...,x_{n-1})$についての説明を求めても答えられませんよね。LLMも同じです。
では、LLMが学習している内容とはなんでしょうか?それは、ざっくり言うとオープンソース(公開しているもの)かつメジャーなものです。
※正確には、GPT-4などはデータが公表されていないため、どのデータを使って学習したかは不明です。しかし、一般的にはオープンソースで学習されています。
それでは、逆にどのようなデータには答えられないのでしょうか?
それは、クローズドソースと、マイナーな情報があげられます。クローズドソースとは、非公開なものを指し、例として社内の内部情報があげられます。また、マイナーな情報としては、日本のローカル線の出発時刻やアマチュアチームの選手名とか...です。
2. 古い学習データへの依存
LLMにはナレッジカットオフというものがあります。ナレッジカットオフとは、データの最終更新日を指し、それ以降の出来事は学習していません。 例えば、執筆時におけるGPT-4oのナレッジカットオフは2024年6月なので、2024年6月までの情報しか知らないということになります。そのため、GPT-4oに「現在の日本の総理大臣は?」と聞いても誤った回答が生成されます。

GPT-4oの回答。執筆時の総理大臣は石破茂ですので、誤った回答となります。※Web検索をOFFにしてます。また、回答してもらうために「あなたの知識をもとに回答してください」という一文を付け加えました。※2025/2/6執筆
3. ハルシネーションの存在
日本語では幻覚と言います。つまり、LLMが最もらしい情報をでっち上げることです。先ほどの「品川 → 名古屋の新幹線」の例もハルシネーションに該当します。原因は主に3つあります。1つ目は知らないから、2つ目は情報が更新されたから、3つ目は最も確率の高い単語を予測しているからです。1つ目と2つ目はすでに説明したので、3つ目について少し解説します。
LLMによる生成は$P(x_n|x_1,x_2,...,x_{n-1})$で表すことができます。条件付き確率です。
この式を翻訳すると、これまで生成した単語や文脈$(x_1,x_2,...,x_{n-1})$を踏まえて次に来る確率が最も高い単語$x_n$を生成するという意味になります。例えば、「私はリンゴが好き」という文章の「好き」の部分を生成する際は、「私はリンゴが」をもとに次に来る単語である「好き」を予測しているに過ぎません。 ここにおける問題は、あくまで確率論に基づいて生成しているに過ぎず、ファクトチェックを行っていないという点です。そのため、どうしても適当なことを言ってしまう場合が存在するのです。
ファインチューニングとRAG
LLMにおけるこれらの課題を克服するためにはどうすれば良いでしょうか?
その方法は2つあります。
- ファインチューニング
- RAG
です。
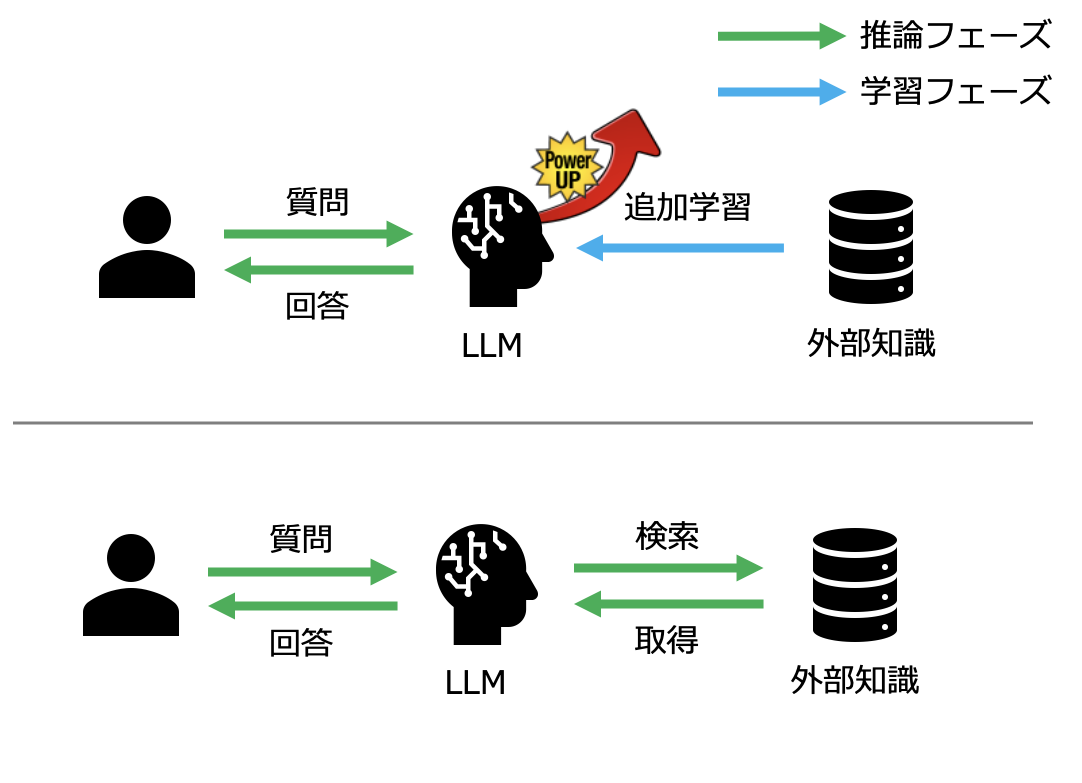
上段がファインチューニングで、下段が RAG になります。図の通り、どちらの手法も外部知識を活用します。
ファインチューニングとは独自のデータを追加で学習させる手法です。これにより、LLMそのものを強化させます。この2つの手法でなぜ課題が解決されるのでしょうか?
まず、必要な知識を学習する or 検索することにより、知らなかったことを知ることができます。 また、外部知識が最新のものであれば、新しい情報の知識も得ることができ、古い情報への依存も解消されます。 したがって、ハルシネーションが減ります。 しかし、ハルシネーションの存在でも触れた通り、LLMの特性から完全にはなくなりません。これは、ファインチューニングでもRAGでも同じです。
一見、LLMそのものをパワーアップできるファインチューニングの方がRAGよりも魅力的な選択肢に見えます。確かに、ファインチューニングは魅力的ですし、多くの場面で採用されています。しかし、実際にLLMをファインチューニングしようとすると、高すぎる壁にぶつかります。
- 高性能なGPUが必要(普通のPCではムリ)
- LLMが指示に従わなくなる
- 大量のデータが必要(数十万〜?)
- 過学習とか気にしないといけない
しかし、RAGを活用すると上記のような壁を全て回避できます! なぜなのか・・・
それは、LLMを学習させないからです。このハードルの低さから、企業レベルではRAGが重宝されていますし、研究分野としても大きく成長しています。
参入ハードルは低いですが、RAGは実際にやってみると思ったほど簡単ではありません。特に回答のヒントとなる情報を正確に取得する部分は非常に難しいです。全く関係ない情報を与えてしまうと、全く精度は向上しないですし、もしかしたら既存のLLMを使うよりも酷くなるかもしれません。
Cuconasu et al.(2024)The Power of Noise: Redefining Retrieval for RAG Systems では、Contextに無関係な情報を含めることで、精度が 30% 以上向上することが判明したそうです。
しかし、これによって回答のヒントを正確に持ってくることが不要になったわけではありません。多数の無関係な情報をLLMに入力すると、効率性と性能に問題が生じるとも言われています(Liu et al.(2024)Lost in the Middle: How Language Models Use Long Contexts; Xu et al.(2023)RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation)
そのため、回答のヒントを持ってきた上で、少し無関係な情報(ノイズ)を混ぜるといいよね!くらいの認識で良いと思います。
なぜRAGが注目を浴びるのか?
最後にここまで話してきたことをまとめたいと思います。
LLMには、
- 知らないことには答えられない
- 古い学習データへの依存
- ハルシネーションの存在
といった課題があり、それを解決する方法としてファインチューニングとRAGが選択肢としてありました。
しかし、ファインチューニングには、超えるには高すぎる壁があります。そのため、RAGが重宝されているのです。
さらに近年、DX (デジタルトランスフォーメーション) の機運が高まり、多くの企業で業務効率化を目的にAIが導入されています。RAGを活用することで、ChatGPTなどのLLMでは扱うことができなかった企業の内部情報を扱うことができるようになります。 そのため、RAGは社内DXと非常に相性が良いのです。そういった意味でも、RAGは非常に注目を浴びていますし、今後AIエージェントの時代になったとしてもRAGで生まれた技術は活用され続けると、私は考えています。
サーベイ論文の紹介
サーベイ論文とは、既存の研究を整理・分析し、全体像を把握できるようにまとめた論文です。興味のある方は読んでみてください。発表された時系列順(新 → 古)で並べておきます。