
AIコーディングエージェントのための Harness Engineering とは?
こんにちは。日本が好きな韓国人のジュニア開発者です。
日本語はまだ勉強中なので、不自然な表現があったらご容赦ください。
最近、Cursor / Claude Code / Codex のような AI コーディングエージェントをよく使っています。
便利なのですが、毎回同じ問題がありました。
新しいセッションを開くたびに、また同じことを説明しないといけないことです。
たとえば、
このプロジェクトでは npm を使っている
生成ファイルは編集しない
変更後はこのチェックを実行する
このディレクトリ構造は守る
過去に起きた失敗を繰り返さない
こういうルールを毎回プロンプトで説明していました。
でも、これは少し変だと思いました。
プロジェクトのルールなのに、なぜチャットの中だけに存在しているのか。
Harness Engineering とは?
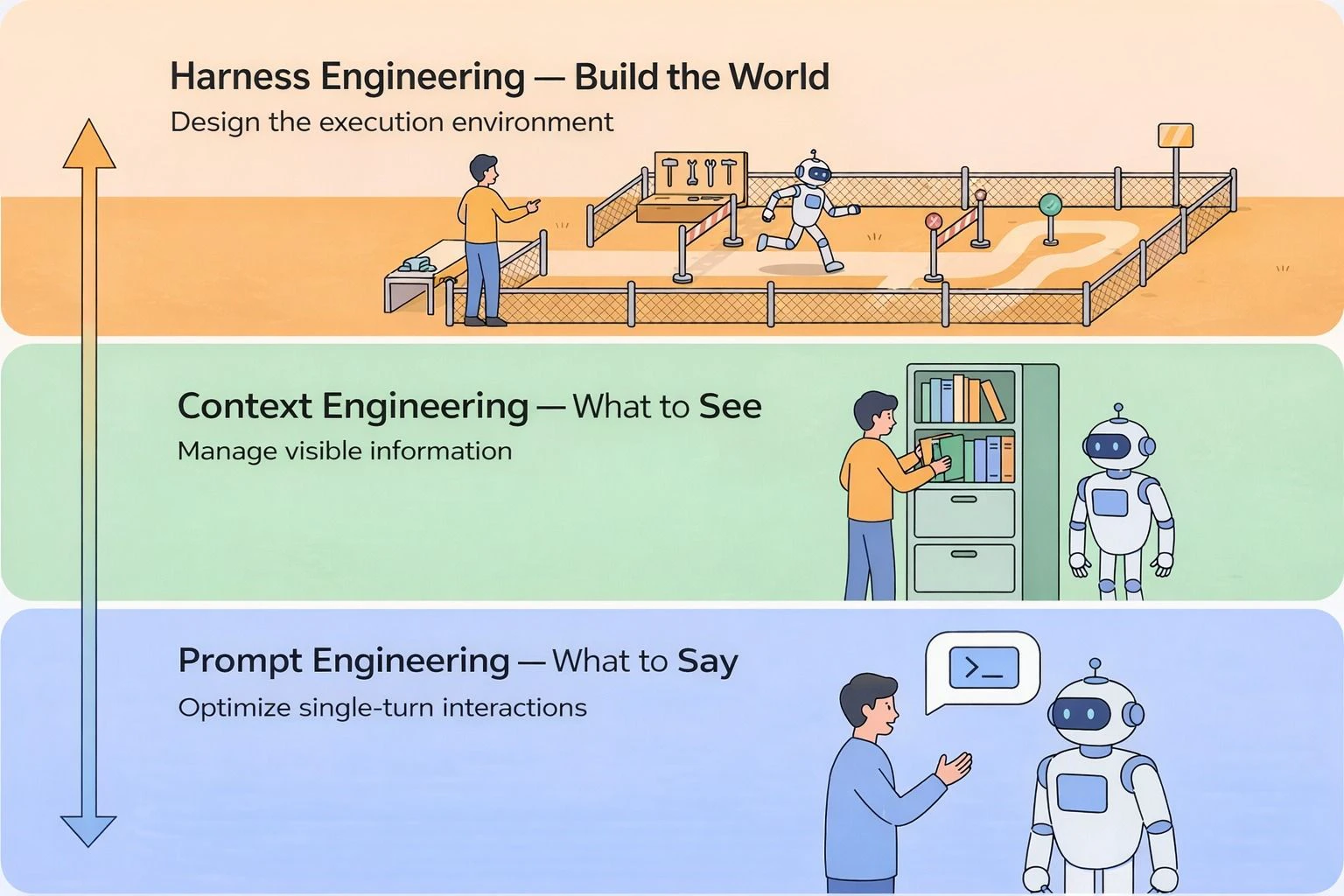
自分の理解では、Harness Engineering はこういう考え方です。
AI agent が作業しやすいように、
プロジェクト側にルール・制約・チェック・記憶を用意すること。
つまり、agent を毎回プロンプトだけで制御するのではなく、repository 自体を agent にとって作業しやすい環境にする、という考え方です。
自分の中では、こう整理しています。
Harness = Instructions + Constraints + Feedback + Memory + Evaluation
それぞれを簡単に言うと、
Instructions: agent が読むルール
Constraints: 守るべき制約
Feedback: テストやチェック
Memory: 過去の判断や失敗の記録
Evaluation: 本当に効果があったかを見る記録
なぜ必要だと思ったか
AI agent はセッションをまたぐと、前の会話を忘れることがあります。
もちろん、長いプロンプトを書けばある程度は対応できます。
でも、プロンプトだけに頼ると問題があります。
- 新しいセッションで毎回説明が必要
- 人間が説明し忘れる
- agent が同じ失敗を繰り返す
- 過去の判断がチャットの中に埋もれる
- チェックすべきことが曖昧になる
特に、自分が困ったのは「失敗が残らない」ことでした。
一度バグを直しても、その理由が repository に残っていなければ、次の agent はまた同じ道を通るかもしれません。
そこで作ったもの

この考え方を試すために、harness-starter-kit という小さな starter kit を作りました。
GitHub:
これは自動インストーラーというより、target repository に合わせて最小限の harness を追加するための reference kit です。
重要なのは、target repository が source of truth であることです。
つまり、starter kit のテンプレートをそのままコピーするのではなく、
既存の構造
既存の package manager
既存の docs
既存の test / CI
既存の convention
を優先します。
その上で、必要なものだけを追加します。
何を追加するのか
たとえば、こういうものです。
AGENTS.md
docs/decisions/
docs/failures/
scripts/check_*
adoption report
AGENTS.md は agent が最初に読むプロジェクトルールです。
たとえば、
どのコマンドを実行するか
どのファイルを編集してはいけないか
どのディレクトリに何を置くか
変更後に何を確認するか
を書きます。
docs/decisions/ には、構造的な判断を残します。
たとえば、
なぜこの framework を使うのか
なぜこの API boundary にしたのか
なぜ mock fallback を残すのか
のような判断です。
docs/failures/ には、繰り返したくない失敗を残します。
ただし、失敗を書くだけでは足りないと思っています。
失敗には、できるだけ detection / prevention をつなげます。
つまり、
どの test で検出できるか
どの fixture で再現できるか
どの smoke check を実行するか
どの manual review point で確認するか
まで書くようにします。
実際に dogfood してみた
この kit を自分の実プロジェクトで試しています。
1つは Django の小さなプロジェクトです。
ここでは、
scripts/check_harness.py
.github/workflows/harness-check.yml
docs/decisions/
docs/failures/
を使って、local check と CI check の流れを作りました。
もう1つは Next.js のプロジェクトです。
こちらは外部 API を扱う project で、TAGO / Gumi BIS / TMAP / OpenRouteService などを使っています。
この project では、特に failure memory が役に立ちました。
たとえば、ある API endpoint では parameter 名の casing が重要でした。
nodeid
を使うべきところで、
nodeId
を使うと、provider が stop filter を無視してしまい、結果的に rate limit に近い問題が起きました。
この失敗は、ただのメモではなく docs/failures/ に記録し、関連する test にもつなげました。
check が失敗したこともあった
面白かったのは、npm run check:harness が失敗したときです。
最初は悪いことに見えました。
でも、実際には harness が問題を早く見つけてくれたケースでした。
原因は app source ではなく、Next.js の generated type artifact でした。
.next/ 以下の生成ファイルを直接編集するのではなく、next typegen を typecheck の前に実行するようにしました。
そして、その判断を docs/decisions/ に、失敗を docs/failures/ に残しました。
以前なら、これはチャットの中で終わっていたかもしれません。
次から next typegen を先に実行しよう
でも今は repository に残っています。
まだ効果を証明できたわけではない
正直に言うと、この kit が agent を本当に良くしたと証明できたわけではありません。
Harness Doctor のような診断は、repository に durable evidence があるかを見ることはできます。
たとえば、
AGENTS.md があるか
check script があるか
decision / failure docs があるか
CI があるか
などです。
でも、それは agent effectiveness そのものではありません。
本当に知りたいのは、
agent が間違ったファイルを編集しなくなったか
同じ失敗を繰り返さなくなったか
reviewer の手戻りが減ったか
最初の verification 成功率が上がったか
です。
これは task outcome をもっと集めないと分かりません。
なので、今の自分の結論はこれです。
harness は agent を魔法のように賢くするものではない。
でも、失敗を早く見つけて、repository に記憶として残す助けにはなる。
まとめ
AI coding agent を使うとき、プロンプトは大事です。
でも、プロジェクトのルールを毎回プロンプトだけに置くのは弱いと思いました。
だから、自分は repository 側に harness を作る方向を試しています。
ルールを AGENTS.md に残す
判断を docs/decisions に残す
失敗を docs/failures に残す
チェックを scripts に残す
結果を adoption report に残す
こうすることで、新しい agent session でも、少なくとも project context を読み直す場所ができます。
まだ実験中ですが、Django と Next.js の project で dogfood しながら改善しています。
GitHub:
Cursor / Claude Code / Codex などを使っている方から見て、この方向性が使えそうかフィードバックをもらえると嬉しいです。
私はまだジュニア開発者なので、経験のある方の意見を聞いてみたいです。