やりたいこと
scrapboxでブックログがしたい。
しかし、書籍情報を手入力するのが手間。コピペするのもいちいちブラウザで調べるのが手間なので自動化したい。
⇒半自動化するpwaをつくりました。
toscrapb(スマホ用です)
github
主な機能
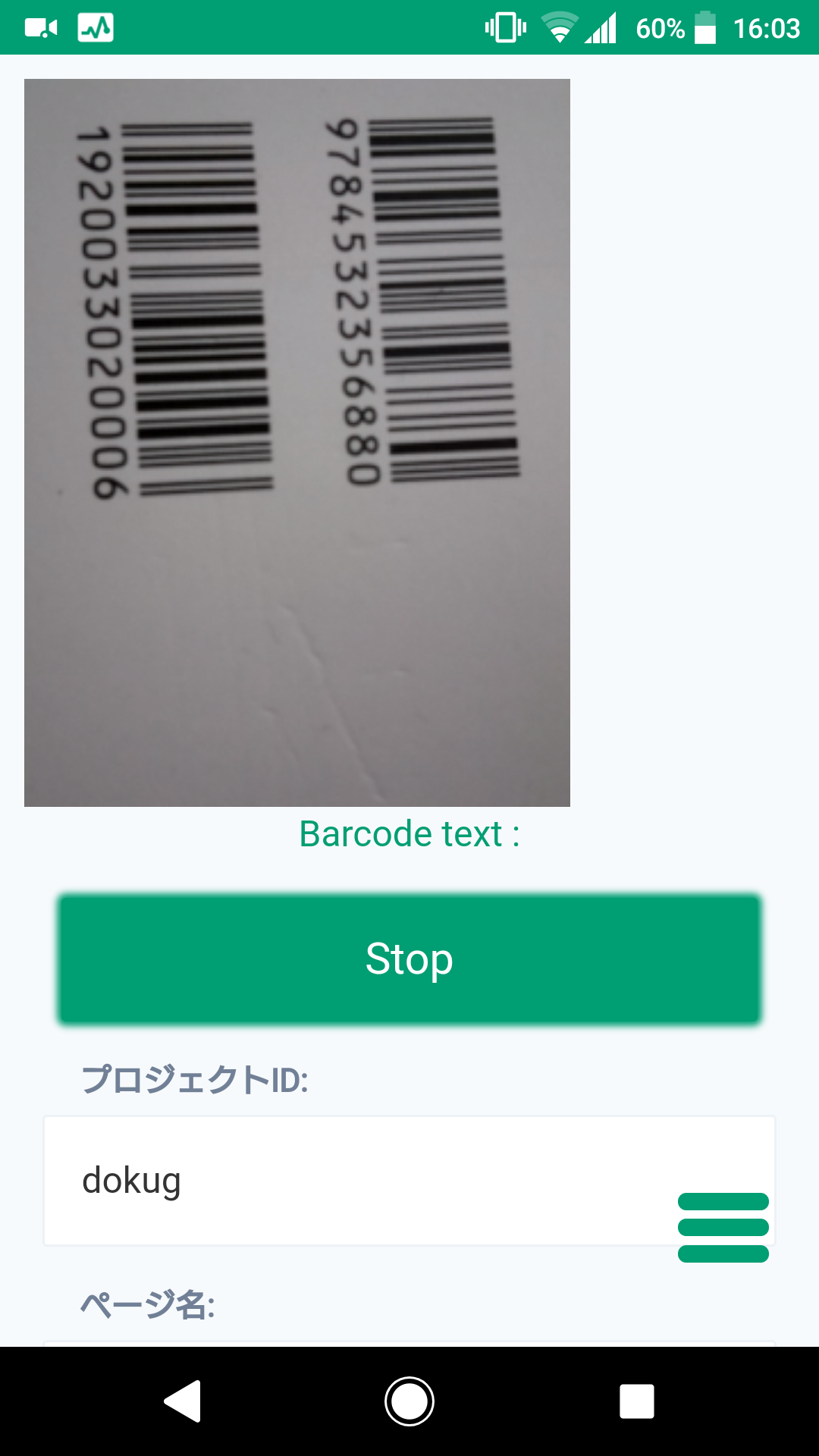
1.ISBNバーコードをカメラで読み取り
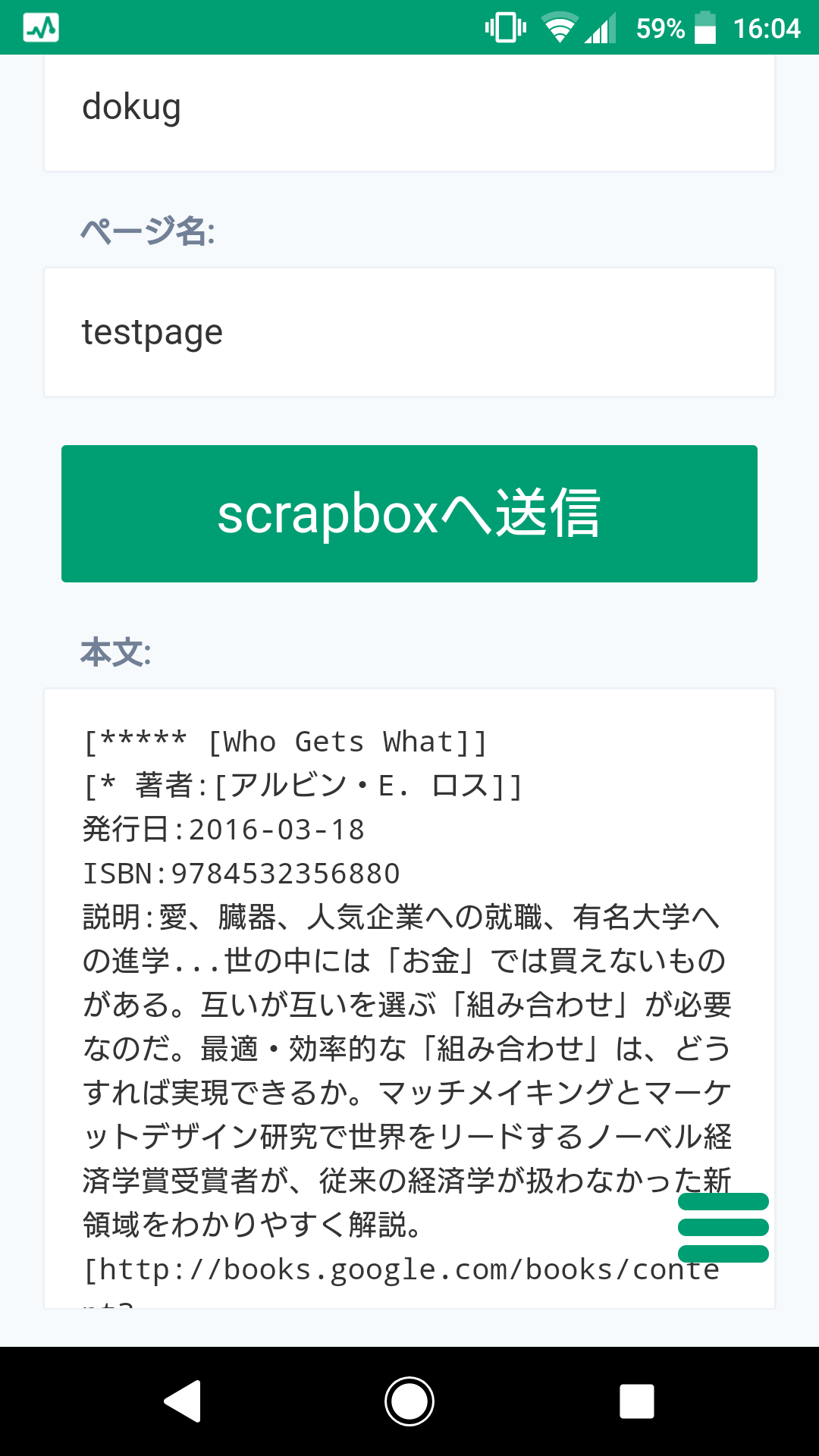
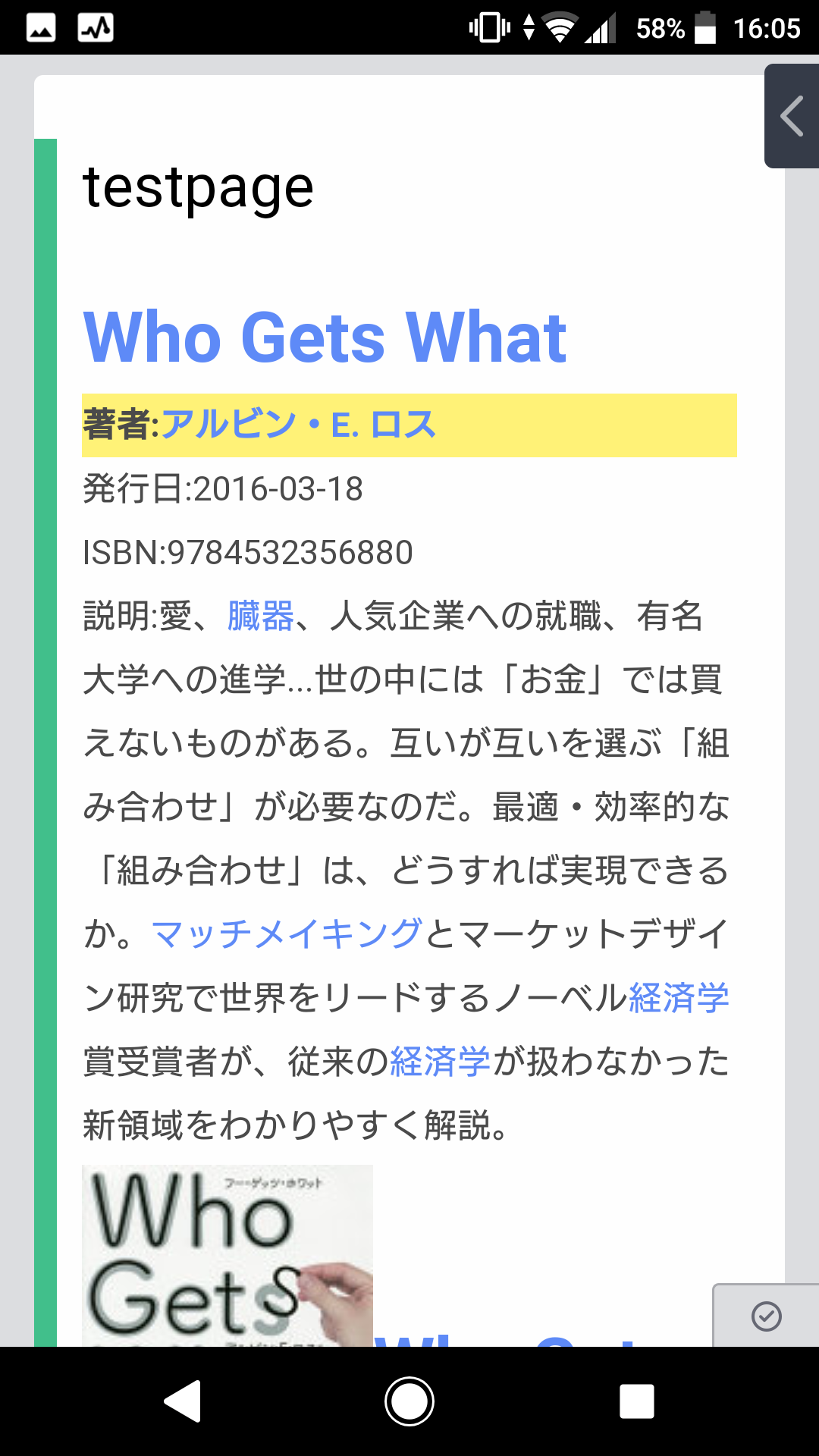
2.Google Books APIから書籍情報取得(タイトル、著者名、出版日、概要、書影)
3.タイトルと著者名をscrapboxのリンク形式(角括弧[]で囲む)にしてフォームを作成
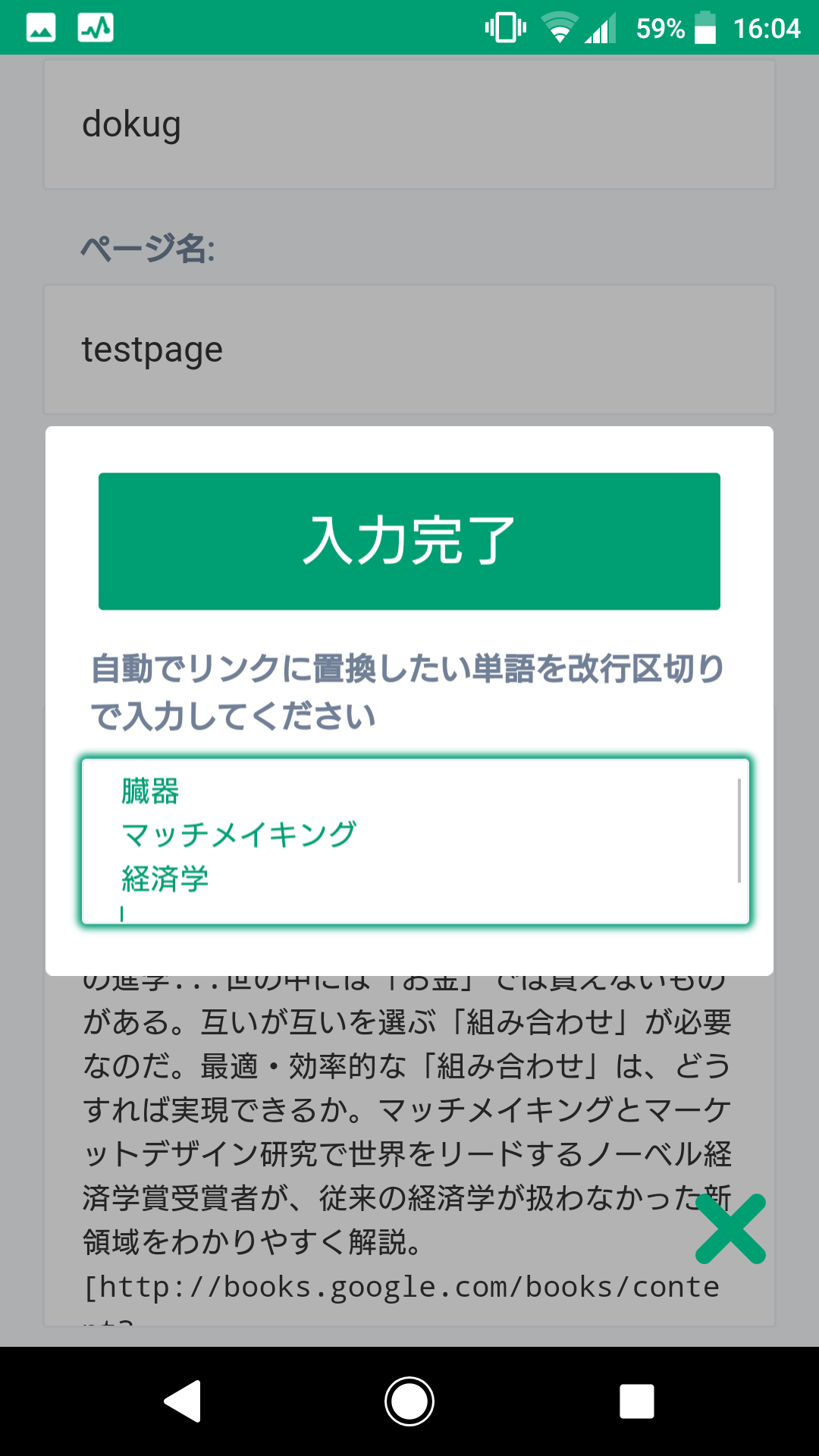
4.予め設定したワードもscrapboxのリンクに自動で置換
5.scrapboxのAPIを叩く
おまけで他のアプリ(Twitterやブラウザ)からの共有も可能にしています。web上の記事のタイトル、urlなどを取得して本文に反映できます。
技術的な面
作業環境
ubuntu 18.04
android 8.0.0
(※Shape Detection APIを利用するためにはchromeの設定が必要。後述)
firebase
pwaとは
「PWAとはなにか。なぜ今それを活用すべきなのか?」という 「What is a PWA and why should you care?」 』の和訳記事が詳しいです。
PWA は Progressive Web Apps の略です。モバイルに限らずデスクトップの両方でインストール可能であり、アプリと同等の体験を提供します。
とあります。オフラインでも動作する・プッシュ通知可能などのメリットがありますが、今回はオマケ機能の「他のアプリからの共有受付(intent)」を実装したかったのと、単にPWAを利用してみたかったという理由で選びました。
仕様はw3cのgithub.ioを参照
Service Worker
Web App Manifest
Web Share Target API
1.ISBNをカメラで読み取る
Shape Detection APIを使いました。
Shape Detection APIとは?という方へは以下の記事が分かりやすいのでおすすめです。
「Shape Detection API + PWAでブラウザからそのまま使えるバーコードリーダーアプリを作ってみる」
まだEditor's Draft(草案レベル)ですが以下の3つの事ができます。
Face Detection(顔検出)
Barcode Detection(バーコードスキャン)
Text Detection(テキスト認識)Chrome 70でこの機能がOrigin Trial(実験的に提供する機能)になりました。
上記記事にもあるように、使用するにはchrome側での設定が必要です。
Shape Detection APIを使えるようにするには、まず chrome://flags からExperimental Web Platform featuresを Enabled にする必要があります。アドレスバーに以下を入力して設定します。設定後、Chromeを再起動します。
chrome://flags/#enable-experimental-web-platform-features
困った点
書籍のバーコードはたいてい上下に2つ並んで配置されています。
上の段はISBNコードです。
世界共通で使用されており書籍を識別することができます。日本の書籍は9784からはじまります。
下の段は図書分類コードと価格情報などです。
このうち今回必要なのは上の段のISBNコードだけなのですが、デフォルトのShape Detection APIには識別する機能がありません。
解決法
9784からはじまるコードを認識するまでスキャンを続けるようにしています。そのため、洋書の読み取りはできません。
2.Google Books APIから書籍情報取得(タイトル、著者名、出版日、概要、書影)
Google Books APIは書籍登録数が少ないため、和書でもISBNから書籍情報を取得できないケースがあります。手持ちの本でいくつかやってみても取得できない本がちらほらありました。
書籍登録数が多い国立国会図書館のAPIを利用する手もありましたが、国立国会図書館のAPIにはレスポンスが遅いというデメリットがあり、Google Books APIなら高速レスポンスで書影・概要も(書籍によっては)取得できるというメリットがあったので今回はGoogle Books APIを利用しました。
ちなみに、webcatの外部提供URLからは目次、openBDからは目次・書影・書評、楽天ブックス書籍検索APIからは書影・商品説明が(それぞれ書籍によっては)取得できるようです。
今後複数のAPIからデータを取得して統合できたらいいなと思っています。
和書のAPIのまとめ記事
書籍検索APIは結局どれが一番いいのか
500件とテストデータは少ないのですが、網羅率と応答時間をテストした記録が紹介されている記事です。
書籍情報を反映した画面
3.4.scrapbox関連
3.タイトルと著者名をscrapboxのリンク形式(角括弧[]で囲む)にしてフォームを作成
4.予め設定したワードもscrapboxのリンクに自動で置換
「Web Share Target API を使って共有メニューからスクマするアプリを作った」を参考に作成しました。
pwaとしての全体の構成やプロジェクトIDをlocalStrageに保存する機能などもこちらの記事を参考にさせていただきました。
困った点
scrapboxの記法で悩みました。リンクは[角括弧]で記載します。正規表現では扱いづらい再帰的な入れ子の構造です。
例えば、
「あああ行動経済学いいい」という文字列があり「行動経済学」と「経済学」の2つの文字にリンクをつけようとすると、「あああ[行動[経済学]]いいい」となってしまいます。
この場合scrapboxでは「経済学」のリンクは有効ですが、「行動経済学」というワードのリンクは無効となります。1
解決法というか苦肉の策
文字数の少ない単語から置換することで文字数の多い単語の置換を行わないことにしました。上記の例でいうと「あああ行動[経済学]いいい」となります。しかし、書名やGoogle books APIから取得した書籍概要(description)に元から角括弧が含まれている場合などには意図しないリンクが作成・無効化される可能性があるのでご注意ください。
その他
プロジェクトIDと置換用の単語はlocalStrageに保存されるため、次回起動時に再入力する必要はありません。

5.scrapboxのAPIを叩く
scrapboxのAPI
ページを作るに新規ページの作り方の詳細があります。
https://scrapbox.io/プロジェクト名/タイトル
「androidにscrapboxのpwaをインストールしている環境」かつ「ログイン状態」であればプライベートプロジェクトでもこのurlから新規ページを作成することができます。
注意点は今回作成したpwaの場合
「既にページが存在する場合は、そのページに追記する」という点です。
上記記事には
タイトルは重複しても大丈夫です。
/プロジェクト名/タイトル_2のような、重複よけ処理を行ったURLを自動的に発行します。
という記載があります。読めば明らかですが、これは新規作成ボタン(scrapboxのデフォルト)を利用したときに関する説明です。
このpwaではurlを外部から叩いているためか、重複よけ処理はされず該当タイトルのページに追記されます。上書きはされないので、データを失うなどの困ったことが起こる可能性はないと思いますがご注意ください。
-
ちなみにscrapboxでの強調にあたる[* 強調]で角括弧を使用する場合は[* [強調]]のように二重になってもリンクは動作しました。 ↩