はじめに
マイナンバーカード交付状況のExcelファイルをデータラングリング(9月)のつづき
- 8月は基準日が各表の最後にあるためそれぞれ抽出
- 各表の区切りにいいのがないので上下反転して時点で抽出
データラングリング
import csv
import datetime
import pandas as pd
def df_conv(df, col_name, population_date, delivery_date):
df.set_axis(col_name, axis=1, inplace=True)
df["人口算出基準日"] = population_date.strftime("%Y/%m/%d")
df["交付枚数算出基準日"] = delivery_date.strftime("%Y/%m/%d")
df.insert(0, "算出基準日", delivery_date.strftime("%Y/%m/%d"))
return df
def my_round(s):
return int(s * 1000 + 0.5) / 10
df = pd.read_excel(
"https://www.soumu.go.jp/main_content/000703058.xlsx", sheet_name=1, header=None
).sort_index(ascending=False)
df.dropna(thresh=3, inplace=True)
dfg = df.groupby((df[0] == "時点").cumsum())
dfs = [g.dropna(how="all", axis=1).iloc[::-1].reset_index(drop=True) for _, g in dfg]
print(len(dfs))
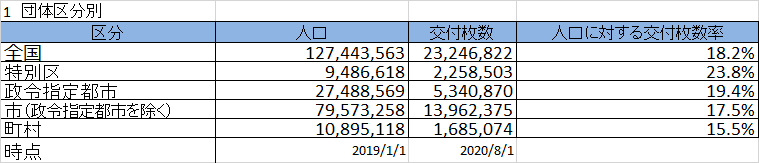
# 団体区分別
dt = dfs[5].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
dfs[5].iloc[-1].dropna()
df0 = df_conv(
dfs[5].iloc[1:-1].reset_index(drop=True),
["区分", "人口", "交付枚数", "人口に対する交付枚数率"],
population_date,
delivery_date,
)
df0["人口に対する交付枚数率"] = df0["人口に対する交付枚数率"].apply(my_round)
df0.to_csv(
"summary_by_types.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df0
# 都道府県一覧
dt = dfs[2].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df3 = df_conv(
dfs[2].iloc[1:-1].reset_index(drop=True),
["都道府県名", "総数(人口)", "交付枚数", "人口に対する交付枚数率"],
population_date,
delivery_date,
)
df3["人口に対する交付枚数率"] = df3["人口に対する交付枚数率"].apply(my_round)
df3.to_csv(
"all_prefectures.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df3
# 男女・年齢別
dt = dfs[1].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df4 = df_conv(
dfs[1].iloc[2:-1].reset_index(drop=True),
[
"年齢",
"人口(男)",
"人口(女)",
"人口(計)",
"交付件数(男)",
"交付件数(女)",
"交付件数(計)",
"交付率(男)",
"交付率(女)",
"交付率(計)",
"全体に対する交付件数割合(男)",
"全体に対する交付件数割合(女)",
"全体に対する交付件数割合(計)",
],
population_date,
delivery_date,
)
df4["交付率(男)"] = df4["交付率(男)"].apply(my_round)
df4["交付率(女)"] = df4["交付率(女)"].apply(my_round)
df4["交付率(計)"] = df4["交付率(計)"].apply(my_round)
df4["全体に対する交付件数割合(男)"] = df4["全体に対する交付件数割合(男)"].apply(my_round)
df4["全体に対する交付件数割合(女)"] = df4["全体に対する交付件数割合(女)"].apply(my_round)
df4["全体に対する交付件数割合(計)"] = df4["全体に対する交付件数割合(計)"].apply(my_round)
df4.to_csv(
"demographics.csv", index=False, quoting=csv.QUOTE_NONNUMERIC, encoding="utf_8_sig",
)
df4
# 市区町村別
dt = dfs[0].iloc[-1].dropna()
population_date = dt.iloc[1]
delivery_date = dt.iloc[2]
df5 = df_conv(
dfs[0].iloc[2:-1].reset_index(drop=True),
["都道府県名", "市区町村名", "総数(人口)", "交付枚数", "人口に対する交付枚数率"],
population_date,
delivery_date,
)
df5["人口に対する交付枚数率"] = df5["人口に対する交付枚数率"].apply(my_round)
df5["市区町村名"] = df5["市区町村名"].replace(r"\s", "", regex=True)
df5["市区町村名"] = df5["市区町村名"].mask(df5["都道府県名"] + df5["市区町村名"] == "兵庫県篠山市", "丹波篠山市")
df5["市区町村名"] = df5["市区町村名"].mask(df5["都道府県名"] + df5["市区町村名"] == "高知県高岡郡梼原町", "高岡郡檮原町")
df5["市区町村名"] = df5["市区町村名"].mask(df5["都道府県名"] + df5["市区町村名"] == "福岡県糟屋郡須惠町", "糟屋郡須恵町")
if pd.Timestamp(df5.iloc[0]["算出基準日"]) < datetime.date(2018, 10, 1):
df5["市区町村名"] = df5["市区町村名"].mask(
df5["都道府県名"] + df5["市区町村名"] == "福岡県那珂川市", "筑紫郡那珂川町"
)
else:
df5["市区町村名"] = df5["市区町村名"].mask(
df5["都道府県名"] + df5["市区町村名"] == "福岡県筑紫郡那珂川町", "那珂川市"
)
df_code = pd.read_csv(
"https://docs.google.com/spreadsheets/d/e/2PACX-1vSseDxB5f3nS-YQ1NOkuFKZ7rTNfPLHqTKaSag-qaK25EWLcSL0klbFBZm1b6JDKGtHTk6iMUxsXpxt/pub?gid=0&single=true&output=csv",
dtype={"団体コード": int, "都道府県名": str, "郡名": str, "市区町村名": str},
)
df_code["市区町村名"] = df_code["郡名"].fillna("") + df_code["市区町村名"]
df_code.drop("郡名", axis=1, inplace=True)
df5 = pd.merge(df5, df_code, on=["都道府県名", "市区町村名"], how="left")
df5["団体コード"] = df5["団体コード"].astype("Int64")
df5.to_csv(
"all_localgovs.csv",
index=False,
quoting=csv.QUOTE_NONNUMERIC,
encoding="utf_8_sig",
)
df5