いきなりまとめ
・速度という観点では、Groqを使うしかない。
・レスポンスタイムは、モデルによって大きく異なる。
・有名なモデルに変に固執するとユーザ体験を大きく損ねる。
・レスポンスタイムは、モデル、実行させる処理、アウトプットToken数で大きく変わる。
はじめに
生成AIを組み込んだWebサービスを複数運用しているが、LLMのAPIが遅すぎて、真面目に困っている。
なので、調査するしかないと思い、調査を行なった。
調査方法
主要なパッと扱える下記のモデルを準備。
これらのモデルに対して、簡単なタスク(挨拶)、中程度なタスク(説明)、難しいタスク(エッセイ)を行わせた。
扱ったモデル一覧とコメント
| 提供元 | モデル | 精度評価 | 公開評価・根拠の見方 | コメント |
|---|---|---|---|---|
| OpenAI | GPT-5.5 | S+ | Artificial AnalysisでGPT-5.5 xhigh/highが最高帯、VellumでもGPQA上位。(Artificial Analysis) | この一覧では最上位候補。複雑な推論、設計、コード、長文分析向け。 |
| OpenAI | GPT-5.4 | S+〜S | Artificial AnalysisでGPT-5.4 xhighは高スコア帯、LLM StatsでもGPT-5.4は上位。(Artificial Analysis) | GPT-5.5より少し下だが、実務用途ではかなり強い。 |
| OpenAI | GPT-5.4 Mini | A+ | Artificial AnalysisでGPT-5.4 mini xhighは中〜上位帯。(Artificial Analysis) | コスト・速度と精度のバランスが良い。通常業務エージェント向き。 |
| OpenAI | GPT-5.4 Nano | A〜B+ | Artificial AnalysisでGPT-5.4 nano xhighはminiより下だが、軽量モデルとしては強い。(Artificial Analysis) | 分類、短文生成、簡単な問い合わせ対応向き。複雑推論はmini以上推奨。 |
| OpenAI | o3 | A | Artificial Analysisでo3は高推論モデルとして掲載。(Artificial Analysis) | 論理・数学・コード寄りの推論は強いが、最新GPT-5系より総合では下。 |
| OpenAI | o4 Mini | A〜B+ | Artificial Analysisではo4-mini highがo3より少し下。数学系ベンチでは強い。(Artificial Analysis) | 速く安い推論モデル。コーディング補助や定型推論に向く。 |
| OpenAI | GPT-4.1 | B+ | Artificial AnalysisでGPT-4.1は旧世代上位。OpenAI公式でもGPT-4o系より改善と説明。(Artificial Analysis) | まだ実用的。ただし精度重視ならGPT-5.4以上が優先。 |
| OpenAI | GPT-4.1 Mini | B | GPT-4.1 miniはGPT-4o miniより強いが、GPT-5系miniには劣る。(Artificial Analysis) | 低コストの実務処理向け。 |
| OpenAI | GPT-4.1 Nano | C+ | Artificial AnalysisでGPT-4.1 nanoは軽量帯。(Artificial Analysis) | 大量分類・抽出など、失敗許容のある処理向け。 |
| OpenAI | GPT-4o | B〜C+ | Artificial AnalysisではGPT-4oはGPT-4.1より下。(Artificial Analysis) | 音声・マルチモーダル用途では価値あり。純粋な推論精度では旧世代。 |
| OpenAI | GPT-4o Mini | C+ | Artificial AnalysisではGPT-4o miniは軽量帯。(Artificial Analysis) | 安価なチャット、分類、簡単な要約向け。 |
| Anthropic | Claude Opus 4.7 | S+ | Artificial AnalysisでClaude Opus 4.7 maxは最上位帯、VellumでもGPQA上位。(Artificial Analysis) | GPT-5.5/GPT-5.4と並ぶ最上位候補。文章品質・推論が強い。 |
| Anthropic | Claude Sonnet 4.6 | S〜A+ | Artificial AnalysisでSonnet 4.6 maxは高スコア、LLM StatsでもGPQA/SWE系で上位。(Artificial Analysis) | 実務では非常に使いやすい。コーディング・文章・分析のバランスが良い。 |
| Anthropic | Claude Haiku 4.5 | B+〜A | 通常モードは中位、reasoning設定では高い評価も確認される。(Artificial Analysis) | 軽量・高速寄り。精度重視ならSonnet以上。 |
| Gemini 2.5 Flash | B | Artificial Analysisでは中位帯。Gemini 2.5 Proと比べると多くのベンチで下。(Artificial Analysis) | 速度・価格重視のGoogle系モデル。複雑推論はPro系やGPT/Claude上位が有利。 | |
| Gemini 2.5 Flash Lite | C+〜C | Flash LiteはFlashより軽量で、Artificial Analysisでも下位寄り。(Artificial Analysis) | 大量処理、簡単な分類、短文生成向き。 | |
| Groq | Llama 3.3 70B | C+〜B- | Artificial Analysis系では中下位帯だが、70B open-weightとしては実用的。(OpenRouter) | OSS系で安く速く回したい場合の汎用候補。 |
| Groq | Llama 3.1 8B Instant | C | Groq上では高速モデル。精度より速度重視。(Artificial Analysis) | FAQ、分類、軽い抽出など。複雑な判断には不向き。 |
| Groq | GPT OSS 120B | A〜B+ | Groq提供モデルではGPT-OSS-120B highがGroq内トップ。一方、VellumのOSS評価ではGPT-OSS 120BはGPQA/AIMEで強い。(Artificial Analysis) | Groq上で高精度寄りを選ぶなら有力。速度も強い。 |
| Groq | GPT OSS 20B | B+〜B | GroqではGPT-OSS-20B highが120Bに次ぐ位置。VellumではAIME系で強い。(Artificial Analysis) | 軽量OSS推論モデルとして優秀。複雑な総合判断は120B以上推奨。 |
| Groq | Compound | A相当 | Compoundは単一LLMではなく、Web検索やコード実行などのツールを使うシステム。最大10回のツール利用が可能。(GroqCloud) | 最新情報・調査・コード実行込みなら単体モデルより有利な場合あり。純粋なLLM精度とは別評価。 |
| Groq | Compound Mini | B+相当 | Compound Miniは低レイテンシで、ツール利用は少なめ。(GroqCloud) | 簡単な検索付き回答、軽いファクトチェック向き。 |
| Groq | Llama 4 Scout 17B Preview | C+ | Artificial Analysisでは軽量〜中位帯。Groq公式でもPreviewモデル扱い。(Artificial Analysis) | 速度重視。Previewなので本番重要処理では慎重に。 |
| Groq | Qwen3 32B Preview | C+〜B- | reasoning設定でやや上がるが、総合では中位帯。(Artificial Analysis) | OSS系の軽中量モデル。日本語やコードは要検証。 |
| Groq | GPT OSS Safeguard 20B Preview | 対象外 | 安全性分類・Trust & Safety用途の専用モデル。汎用チャット精度の比較対象ではない。(GroqCloud) | モデレーション、ポリシー判定、LLM出力チェック用。通常回答生成には使わない。 |
| Azure | Azure GPT-5.4 | S+〜S | Azure上のGPT-5.4はOpenAI GPT-5.4系と同等評価。プロバイダ差は主に速度・レイテンシ。(Artificial Analysis) | Azure利用前提なら最上位候補。企業利用・Azure統合に向く。 |
| Azure | Azure GPT-5.4 Nano | A〜B+ | Microsoft FoundryではGPT-5.4 mini/nanoは低レイテンシ・低コスト向けとして展開。(TECHCOMMUNITY.MICROSOFT.COM) | OpenAI GPT-5.4 Nanoと同系統。大量処理・軽量タスク向け。 |
調査結果
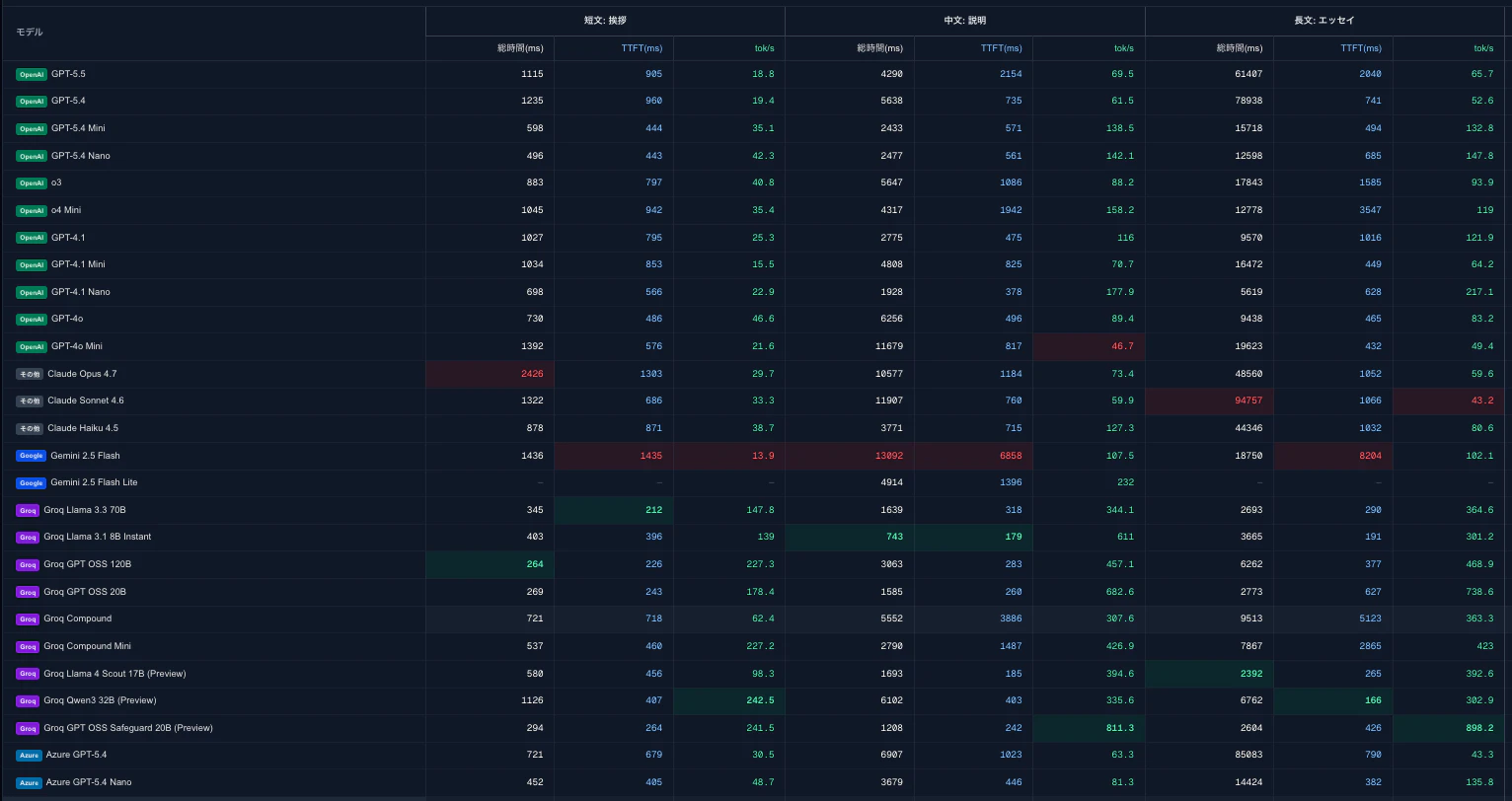
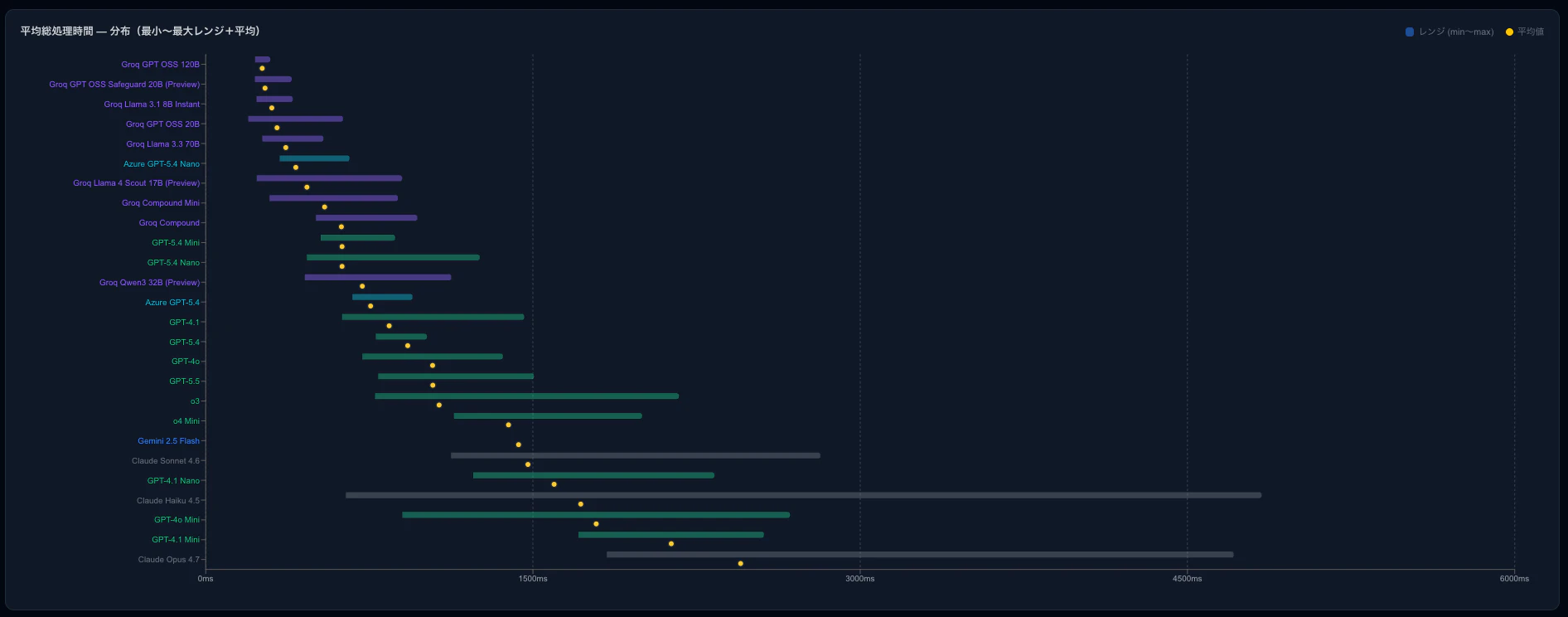
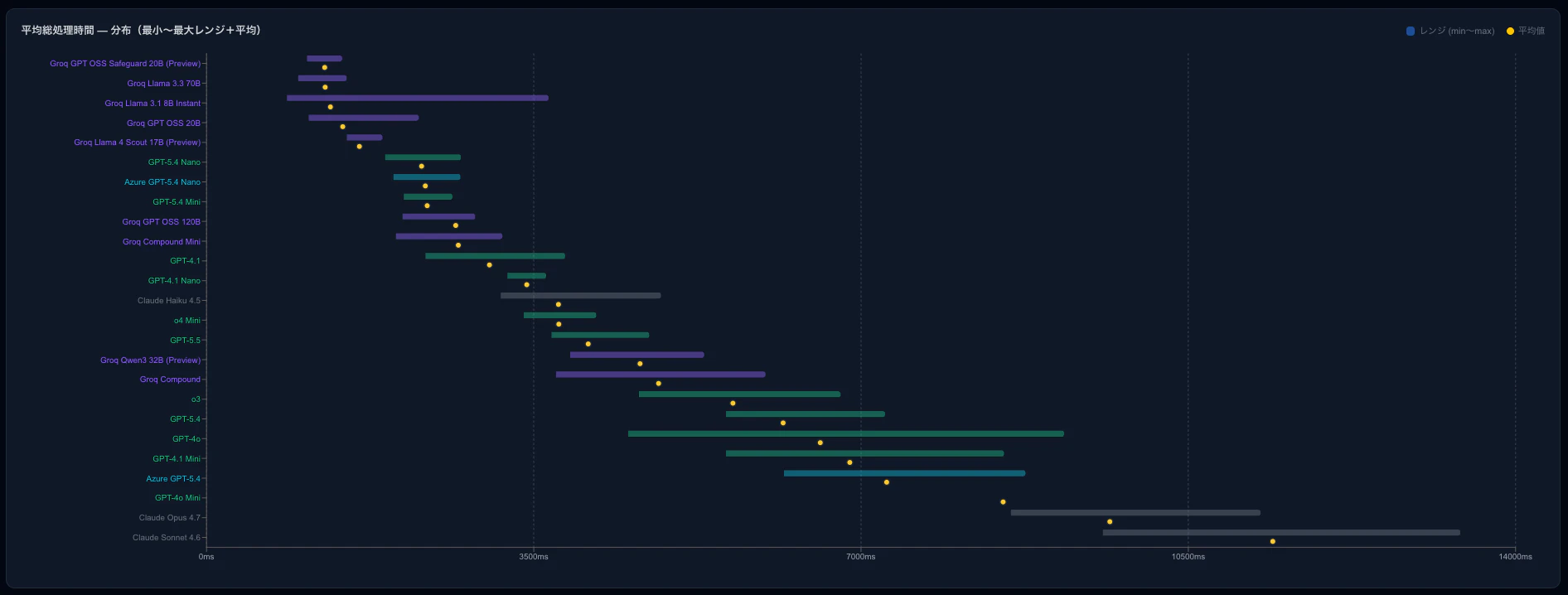
びっくりするほどレスポンス時間に差があることがわかる。
また、GPT系を使いたいならば、Groq GPT 20B、Groq GPT 120B、Groq GPT 120B、GPT 5.4 mini、GPT 5.4 nanoを使うのがいいことがわかる。
どうやったら早くなる?
モデルを変える以外に早くする方法はないかと調べると、やはりアウトプットToken数が関係するらしい。
なので、上記のGroq GPT 20B、Groq GPT 120B、Groq GPT 120B、GPT 5.4 mini、GPT 5.4 nanoを用いてアウトプットToken数ごとの時間を調査。
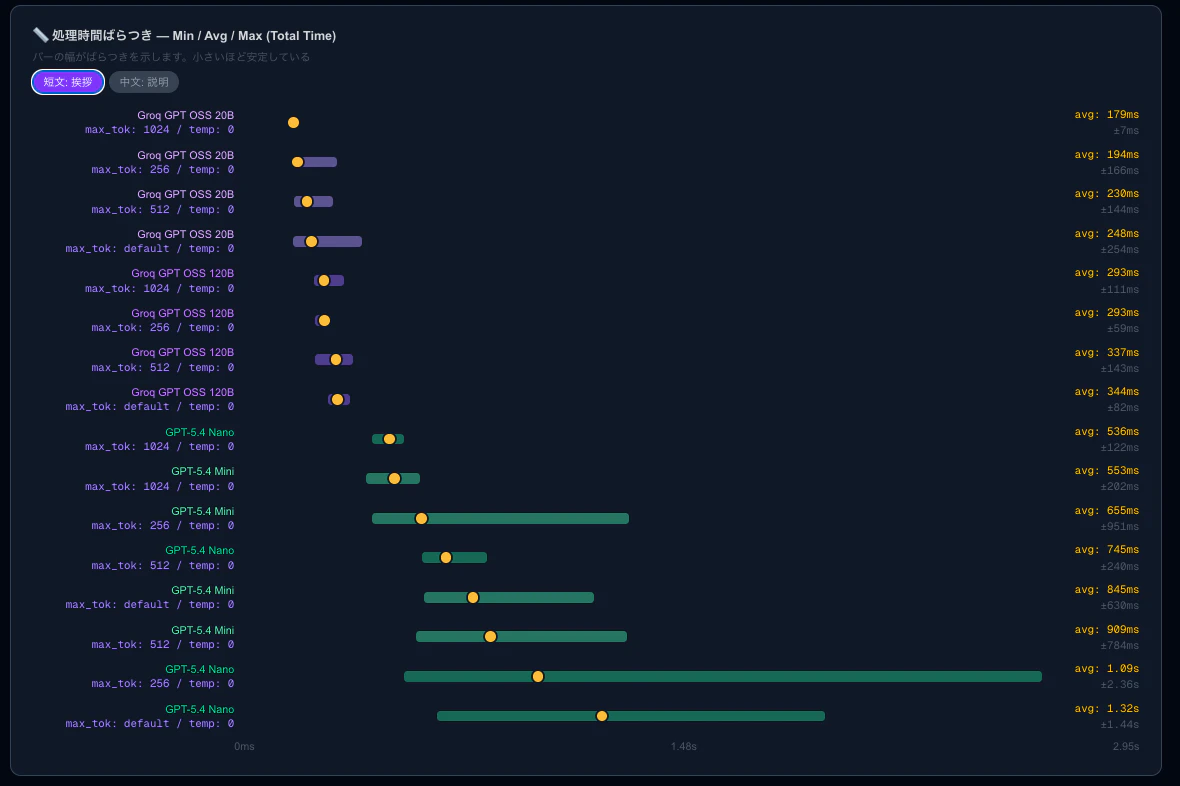
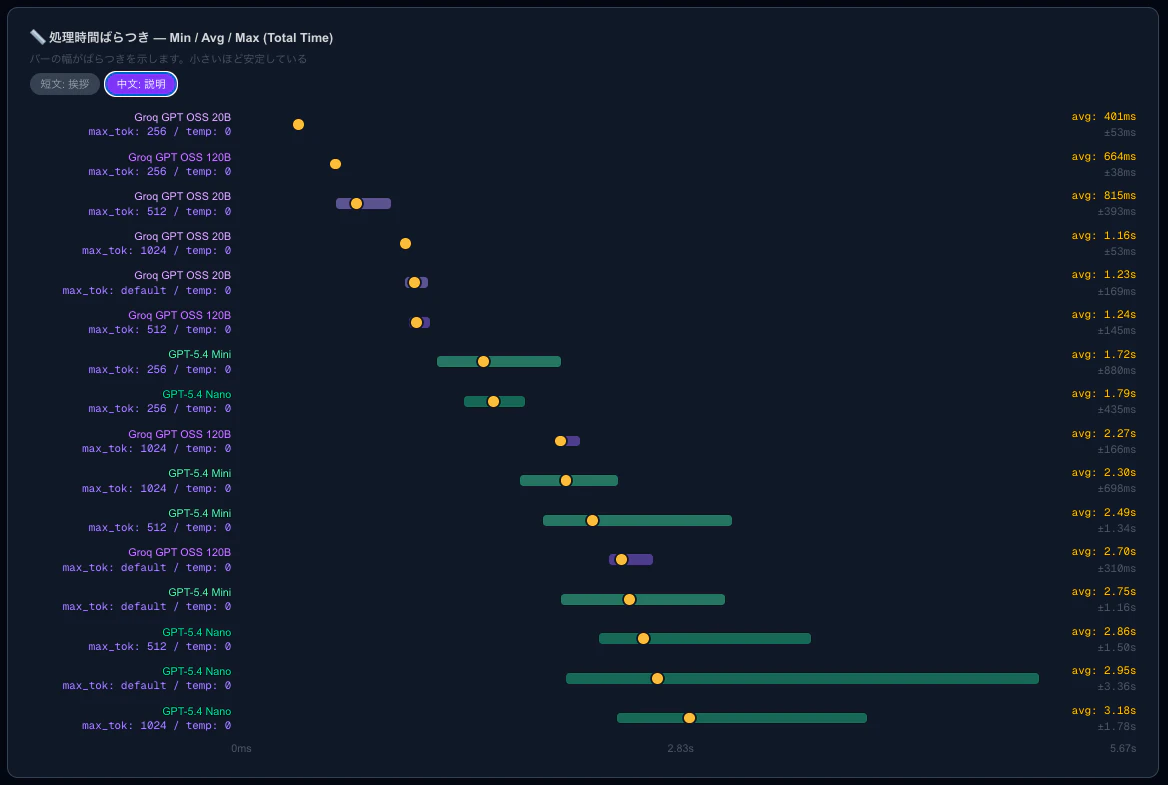
アウトプットToken数が多ければ多いほど時間がかかることがわかる。
まとめ
Webアプリケーションに組み込む際は、使うべきモデルはほぼ決まってくるので、あとはプロンプトエンジニアリングを頑張るしかない。