1. はじめに
ディープニューラルネットワークは、機械翻訳・音声・言語理解などで大きな成果を出してきました。しかし2017年当時、系列変換(Seq2Seq)の主役はまだ RNN(LSTM/GRU) や CNN でした。
※Seq2Seqについては、以前Qiitaで記事を書いています。もし先にそちらを読んでから本記事を見ると、歴史順に追えるので理解しやすいかもしれません。良ければどうぞ。
ところがRNNには、時刻方向に計算が逐次的になってしまい、系列が長くなるほど並列化できず学習が遅くなる、という根本的な制約があります。Attentionはこの問題を緩和する重要部品として広く使われていましたが、多くの場合は「RNNにAttentionを足す」形に留まっていました。
そこで本論文 「Attention Is All You Need」 は発想を反転させ、再帰も畳み込みも捨てて、Attentionだけでエンコーダ・デコーダを組む という Transformer を提案します。結果としてWMT14英独で 28.4 BLEU、英仏で 41.8 BLEU を達成し、学習効率の面でも強いインパクトを残しました。
この記事では、Transformerの中身を「なぜそうするのか?」という理由づけと一緒に整理していきます。読み終える頃には、次の点が腹落ちすることを目標にします。
- なぜ「RNNを捨てる」決断ができたのか(逐次性・パス長・計算量の観点)
- Transformerを支える Scaled Dot-Product Attention / Multi-Head Attention / Positional Encoding の意味
- 実験(WMT翻訳・アブレーション)から見える「効いている設計」と「効き方」
2. 目次
本記事は、機械学習の基礎を前提にしつつ、できるだけ直感的に理解できるよう説明します。
- 1・2:導入と構成
- 3:背景・課題(RNN/CNNの限界と自己注意)
- 4:提案モデル(Transformer全体:Encoder-Decoder)
- 5:コア技術①(Scaled Dot-Product Attention とスケーリングの意味)
- 6:コア技術②(Multi-Head Attention が必要な理由)
- 7:コア技術③(Positional Encoding:順序情報を足し算で入れる)
- 8:学習の肝(Warmup付き学習率・正則化・推論設定)
- 9:実験結果と分析
- 10:まとめ
- 11:おわりに
3. なぜ Transformer が必要なのか?
3.1 RNN:逐次計算が避けられない
RNNは、位置 $t$ の状態が $t-1$ に依存します。そのため、同一サンプル内の計算をまとめて並列化できません。系列が長くなるほど、学習が遅くなったり、メモリ制約のためにバッチが小さくなって不安定になったりします。
3.2 CNN:長距離依存には層が必要
CNNは並列化しやすい一方で、離れたトークン同士の情報を結びつけるには、層を何段も重ねて伝播させる必要があります。つまり、距離が伸びるほど「情報が届くまでの道のり」が長くなりがちです。
3.3 狙い:遠い依存関係を一気に近づける
Transformerが推す自己注意の強みは、「離れた位置同士でも、直接つなげられる」点です。論文は、
- 計算量
- 逐次操作数(並列化のしやすさ)
- 最大パス長(長距離依存の学びやすさ)
という軸で比較しています。ここで作りたい直感はシンプルで、
性能以前に、計算グラフとして“遠いものを近くする”設計が必要だった
ということです。
4. Transformerの全体像
Transformerは枠組みとしては従来どおりEncoder-Decoderですが、中身を大胆に置き換えます。まずは全体像を図で押さえます。

(Figure 1:Transformerの全体構造)
ポイント:
- 左がEncoder(自己注意+Feed Forward Network(FFN))
- 右がDecoder(マスク付き自己注意+Encoder-Decoder Attention+FFN)
- Decoderは未来を見ないようにマスクが入る
図のとおり、Transformerは大きく次の2つで構成されます。
- エンコーダ:自己注意 → 位置ごとのFFN を ($N=6$) 層スタック
- デコーダ:(マスク付き)自己注意 → Encoder-Decoder Attention → FFN を ($N=6$) 層スタック
また、各サブレイヤに 残差接続+LayerNorm を入れて学習を安定化します。
$$
\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))
$$
デコーダ側は未来トークンを見ないように、Attentionのsoftmax入力へマスク(不正接続を ($-\infty$))を入れて自己回帰性を守ります。
4.1 入出力の記法(Seq2Seqとしての定式化)
入力系列を
$$
\mathbf{x} = (x_1, x_2, \dots, x_n)
$$
出力系列を
$$
\mathbf{y} = (y_1, y_2, \dots, y_m)
$$
とします。Transformerはデコーダで自己回帰的に、
$$
p(\mathbf{y} \mid \mathbf{x})
= \prod_{t=1}^{m} p(y_t \mid \mathbf{x}, y_1, \dots, y_{t-1})
\tag{A1}
$$
を学習するモデルだと捉えられます。
5. コア技術①:Scaled Dot-Product Attention
TransformerのAttentionは次で定義されます。
$$
\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
\tag{1}
$$
ここでの最大のポイントは、なぜ ($\sqrt{d_k}$) で割るのかです。ざっくり言うと、次元 ($d_k$) が大きいと内積が大きくなりやすく、softmaxが飽和して勾配が極小になって学習が進みにくくなります。そこでスケールして、学習しやすいレンジに戻します。
5.1 直感:Attentionは「重み付き平均」を作る
式(1)は、行列 ($QK^\top$) で「どれだけ関連しているか」を作り、それをsoftmaxで正規化して「どこをどれだけ見るか」を重みにして、最後に ($V$) を重み付き平均する、という形になっています。
- ($Q$):Query(見たい側)
- ($K$):Key(参照される側)
- ($V$):Value(実際に取り出す情報)
6. コア技術②:Multi-Head Attention
Multi-Head Attentionは、Attentionを1回だけ計算するのではなく、「別々の見方」で ($h$) 回並列に計算して結合します。
$$
\mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}(\mathrm{head}_1,\ldots,\mathrm{head}_h)W^O
\tag{2}
$$
$$
\mathrm{head}_i=\mathrm{Attention}(QW_i^Q,KW_i^K,VW_i^V)
\tag{3}
$$
ここで大事なのは、単一headだと、Attentionが平均化されて情報が潰れやすいという点です。Multi-Head Attentionにすることで、異なる射影空間で別々にAttentionを計算でき、役割分担しやすくなります。
6.1 代表的な設定(記事中に書いておくと親切)
- ($h=8$)
- 各headで ($d_k=d_v=d_{\text{model}}/h=64$)
7. コア技術③:Positional Encoding
Transformerは再帰も畳み込みもないので、そのままだと「順序」が分かりません。そこで、埋め込みに位置エンコーディングを足して順序情報を注入します。
提案は正弦・余弦で、次の形です。
$$
PE(pos,2i)=\sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\tag{4}
$$
$$
PE(pos,2i+1)=\cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
\tag{5}
$$
7.1 直感:位置を「別の情報」として渡す
ここでの気持ちは、「系列の順序は、モデルに勝手に推測させるのではなく、明示的に渡す」です。
足し算にすることで、単語埋め込みと同じ次元で扱えて、以後の層が自然に利用できます。
8. 実験結果と分析
ここからは、論文に出てくる結果を「読み解ける」ように整理していきます。
8.1 Table 1:自己注意は何が嬉しいのか

(Table 1:層タイプ別の比較)
- 自己注意は逐次操作数が小さく、並列化しやすい
- 最大パス長が短く、長距離依存を捉えやすい
8.2 Table 2:WMT14翻訳のメイン結果

(Table 2:WMT14翻訳の結果)
ポイント:
- Transformer (base):EN-DE 27.3, EN-FR 38.1
- Transformer (big):EN-DE 28.4, EN-FR 41.8
- 性能だけでなく、学習コストや学習時間の見通しもセットで語られているのが特徴です
8.3 Table 3:アブレーション

(Table 3:アブレーション結果)
ポイント:
- headが1だと性能が落ちる → Multi-Head Attentionが効いている
- head数は増やせばいいわけではない → 最適な分割がある
- ($d_k$) を小さくしすぎると落ちる → 相性判定には十分な表現力が必要
- 学習型位置埋め込みは正弦波と大差ない → 位置の入れ方は設計の余地がある
8.4 Table 4:翻訳以外への一般化
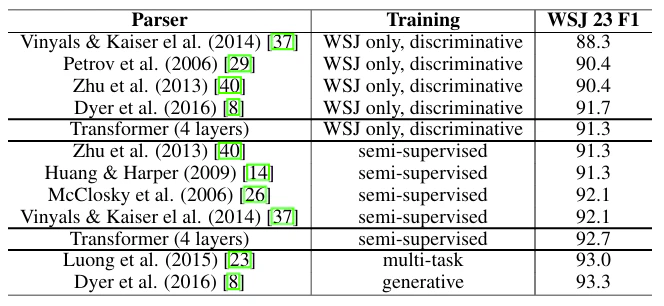
(Table 4:構文解析の結果)
ポイント:
- 翻訳だけでなく、解析タスクでも良い結果が出ている
- 「翻訳専用の小技ではない」ことを示す材料になります
8.5 Figure 2:Attentionの可視化

(Figure 2:Attention可視化の例)
ポイント:
- どの単語に注目しているかが見えるので、直感的に理解しやすい
- Multi-Head Attentionで“見方”が分かれる様子が伝わりやすいです
9. まとめ
- 問題設定:RNNは逐次性、CNNは長距離依存のパス長が課題でした。自己注意は“遠い依存”を近づけられます。
- 提案:再帰も畳み込みも捨て、AttentionだけでEncoder-Decoderを組むTransformerを提案しました。
- 中核技術:Scaled Dot-Product Attention(($1/\sqrt{d_k}$) で飽和を避ける)とMulti-Head Attentionが鍵です。
- 順序の扱い:正弦波を採用した位置エンコーディングを埋め込みに足して順序情報を注入します。
- 結果:WMT14で強いBLEU(EN-DE 28.4 / EN-FR 41.8)を達成し、学習効率の面でもインパクトがありました。
- 示唆:設計の本質は「計算グラフとして遠い依存を近くする」こと、そして学習レシピまで含めて成立させた点にあります。
10. おわりに
本論文が示したのは、モデルを複雑にすること以上に、
「計算の形(並列化しやすさ/パス長)を変えるだけで、世界が変わる」
というメッセージだったと思います。
Transformerは、その後のBERT系やGPT系、そして大規模言語モデル(LLM)へとつながる流れの“土台”になりました。この記事が、論文を自分の言葉で説明できるようになるための助けになれば嬉しいです。