背景
Mail だけでなく、HTML コンテンツはそれなりにある。
Automate で処理するときは専ら正規表現を使ってたが・・XML 解析したらもっと簡単に出来るんじゃない?とふと思い立って試してみた
結果
- XML に変換して処理したけど・・途中で正規表現も使うことになったし、もっと良い方法見つけないと使えない
- HTML だと Tag 閉じてなくてもなんとかなるけど、XML だとエラー扱い⇒正規表現で修正
- xpath で取得すると base64 encoded 状態なので、decode も必要
- 取得結果が Tag 付き⇒正規表現でタグ削除
動作例
取得対象例:Message center からの通知内容のタイトル部分のみの取得がしたい
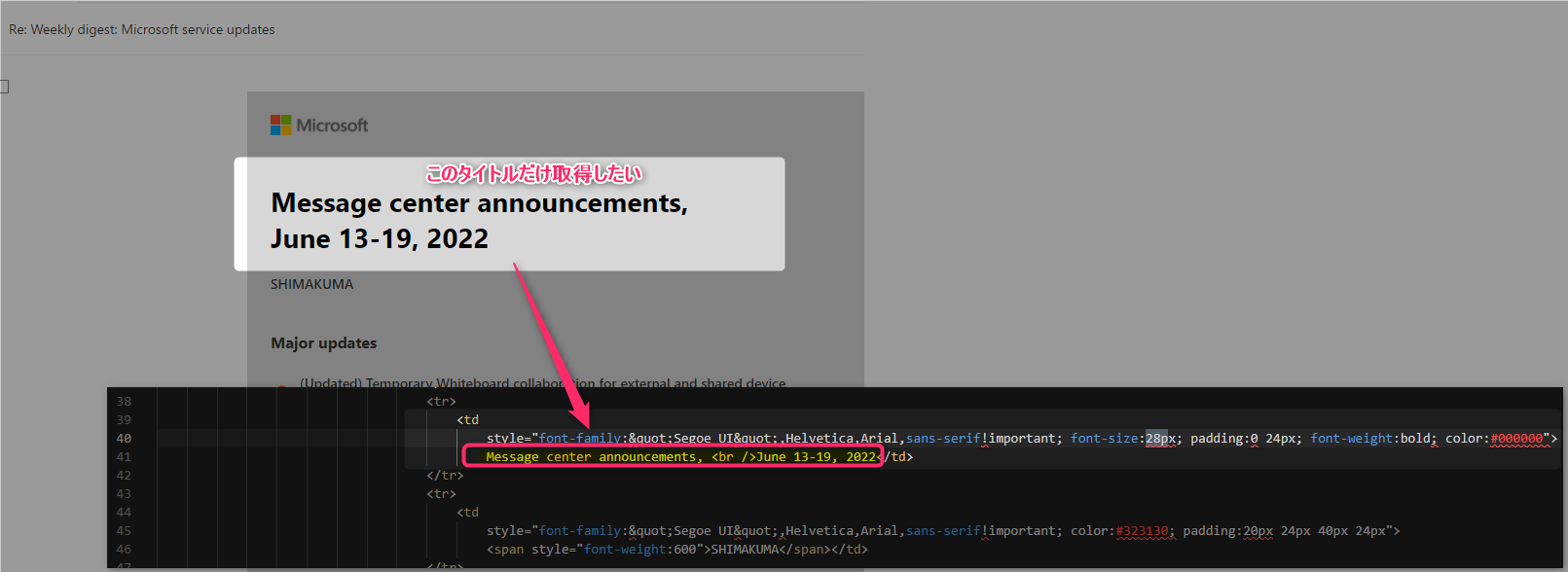
実フローと取得例
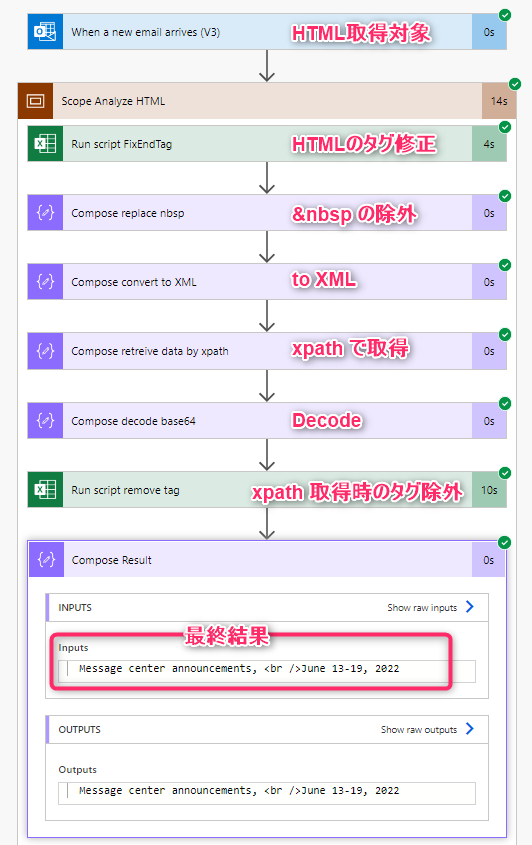
概要
- XML 変換前の前処理
- XML 変換して、XPATH で対象取得
- 取得結果の後処理
正規表現の置換 例
XML 変換前の前処理

- 終了タグが無いと困るので、正規表現で修正
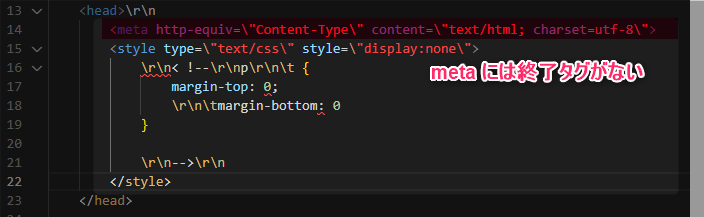
- があると xml 変換時にエラーが出たので削除
XML 変換して、XPATH で対象取得
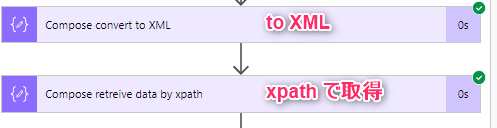
今回の例はこんな感じ。font-size が Unique だったんで。
xpath(outputs('Compose_convert_to_XML'), '//td[contains(@style, "font-size:28px")]')
取得結果の後処理
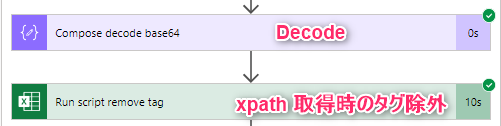
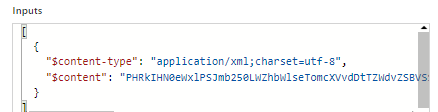
- xpath の結果を vbase64ToString 関数で decode して取得。decode 前は以下
- 取得結果には開始・終了タグが付いているので、削除して終わり

Decode 例
base64ToString(outputs('Compose_retreive_data_by_xpath')[0]['$content'])
あとがき
ん-・・正規表現一発で対象取得したほうが簡単で速い、ということが分かった・・悲しい事実 🤣
keyword
how to retreive value from HTML in Power Automate by converting to XML