背景
名寄せをするのって面倒だったけど、専用の関数があったので備忘録
概要
- AddFuzzyClusterColumn にお任せで名寄せ
- 言語指定をすることで日本語も利用可能
- 閾値で、調整可能
- 変換テーブルを用意しておくことで、調整も可能
ドキュメントは以下
利用例
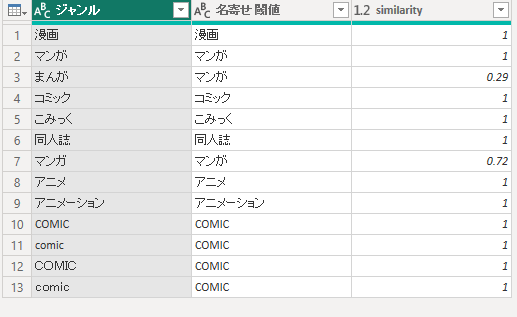
閾値だけ
= Table.AddFuzzyClusterColumn(変更された型, "ジャンル", "名寄せ 閾値", [SimilarityColumnName="similarity", Culture="ja-JP", Threshold=0.1])
日本語指定しても、全角半角、小文字大文字は単純に名寄せしてくれる。
カタカナひらがな程度なら、閾値次第
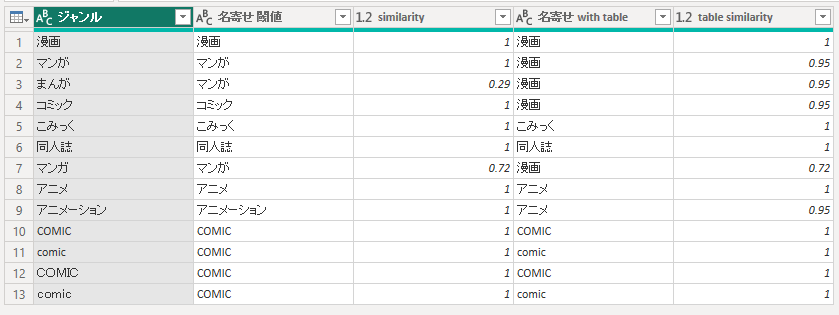
変換テーブル利用
= Table.AddFuzzyClusterColumn(result, "ジャンル", "名寄せ with table", [SimilarityColumnName="table similarity", IgnoreCase = false, Culture="ja-JP", Threshold=0.27, TransformationTable=Transform])
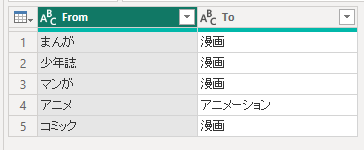
以下のようなテーブルを用意しておくことで、追加で名寄せを実施出来る。
とはいえ・・面倒ではある・・よね。 ![]()
変換コード例全部
Transform Table
let
ソース = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45Wety473HT5MeNPUo6Ss/2rH4+ZbdSrE600tMNE5/u3PJiFZrw4+Z5j5s3Y6h+3LTocXP34+aFQGE4+3HznsdN2x83LwfqgKra/Lh5/uPm5sdN65H0xwIA", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [From = _t, To = _t]),
変更された型 = Table.TransformColumnTypes(ソース,{{"From", type text}, {"To", type text}})
in
変更された型
Fuzzy Sample
let
ソース = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WerZn9fMpu5VidaKVHjfPe9y8+XFjD4TXuO9x02Q4r2nz4+b5j5ubHzeth0oD5fY/blz8uLEfLPB0Qs+TXbterOpBNqtpDVT3osfN3Y+bF6LyHjfvedy0/XHzcqBSsIyzv6+nM5iVnJ+bmQxmvd+z+P2e9e/3rH2/ZyWQDRHb2/x+b//7vb3v93YC2UqxsQA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type nullable text) meta [Serialized.Text = true]) in type table [ジャンル = _t]),
変更された型 = Table.TransformColumnTypes(ソース,{{"ジャンル", type text}}),
result = Table.AddFuzzyClusterColumn(変更された型, "ジャンル", "名寄せ 閾値", [SimilarityColumnName="similarity", Culture="ja-JP", Threshold=0.1]),
result2 = Table.AddFuzzyClusterColumn(result, "ジャンル", "名寄せ with table", [SimilarityColumnName="table similarity", IgnoreCase = false, Culture="ja-JP", Threshold=0.27, TransformationTable=Transform])
in
result2
あとがき
700 を超える関数があるので、なにかやりたいことがあったら調べてみるってのが大切ではあるけれど、
たまにしか使わないとついつい手抜きしてしまう。
ってことで、こうやって備忘録をしていくことは記憶に残すためにも大切なはず・・