概要
- GANを使ってVTuber作ってみた
- 人間と猫のモデルを作った
- リアルタイムで動物のモデルを動かす試みはまだあまりないと思う
※注意
背景では、バーチャルYouTuberについて熱く語っているので、興味のない方は飛ばして下さい。
GANについて軽く技術の紹介をしていますが、すでにご存じの方はDeep Leaning based Virtual YouTuberまで飛んで下さい。
背景
バーチャルYouTuberをご存知でしょうか?バーチャルYouTuberとは、モーションキャプチャを用いてキャラクターモデルの操作を行い、YouTubeやMirrativ等のプラットフォームで配信を行う、言わばYouTuberをキャラクターにしたエンターテイメントの1つです。
バーチャルYouTuberランキングを運営する株式会社ユーザーローカル様の調査によれば1 、2018/1/31時点で活動しているのは181名でしたが、同年12月には6000人以上に増加、そして2019/2/21には7000人を突破したとの報告もあり2、バーチャルYouTuber市場が今後も拡大していくことが予想されます。かく言う私も沼にはまったファンの1人で、最推しの樋口楓さんとニコニコ町会議でお話しをしたり、18時間かけて東北から大阪までライブを見に行く程のハマり具合です。
これだけの人数が活動している中で、「YouTubeの収益化」をクリアするのは大きな問題の1つだと私は考えています。様々な基準がありますが、大きく分けて①チャンネル登録者数1000人以上、②過去12ヶ月の総再生時間が4000時間以上という2つを満たす必要があります。多くの方が活動し、企業も参戦する中、この基準を満たすのは容易ではありません。
そこで、これまでキャラクターベースのモデルではなく、GANを使った「Deep Learning系Vtuber」という新しい形態でのモデルを提供することができれば、話題性を生み、チャンネル登録者数増加に繋げられるのではないかと考えました。以降、大学の講義のPBLとして取り組んだことについて説明をしていきたいと思います。
(という、背景や問題提起は後付です。ただ単純に、GANでVtuberできんじゃね?と思ったのが始まりです。)
GAN
機械学習を用いて作るモデルは、Discriminative modelとGenerative modelという2つに分類されます。それぞれの詳細な説明は省略しますが、今回使用するGAN3はGenerative modelに属する手法です。(一部構造にDiscriminative modelを使用していますが)
下図がGANのネットワーク構造です。
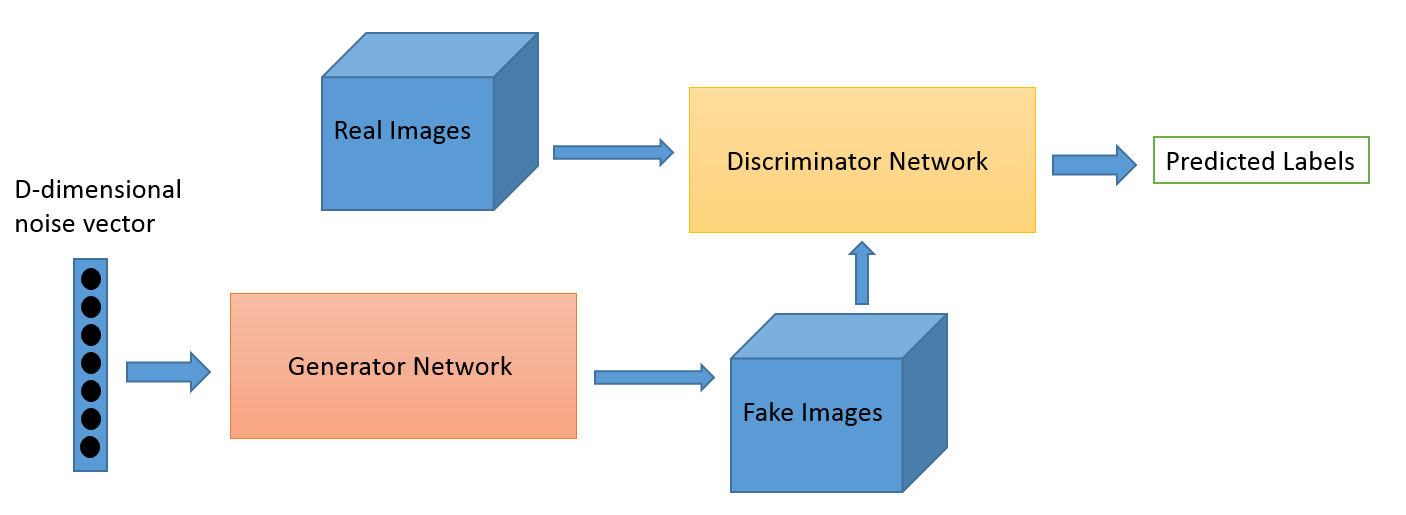
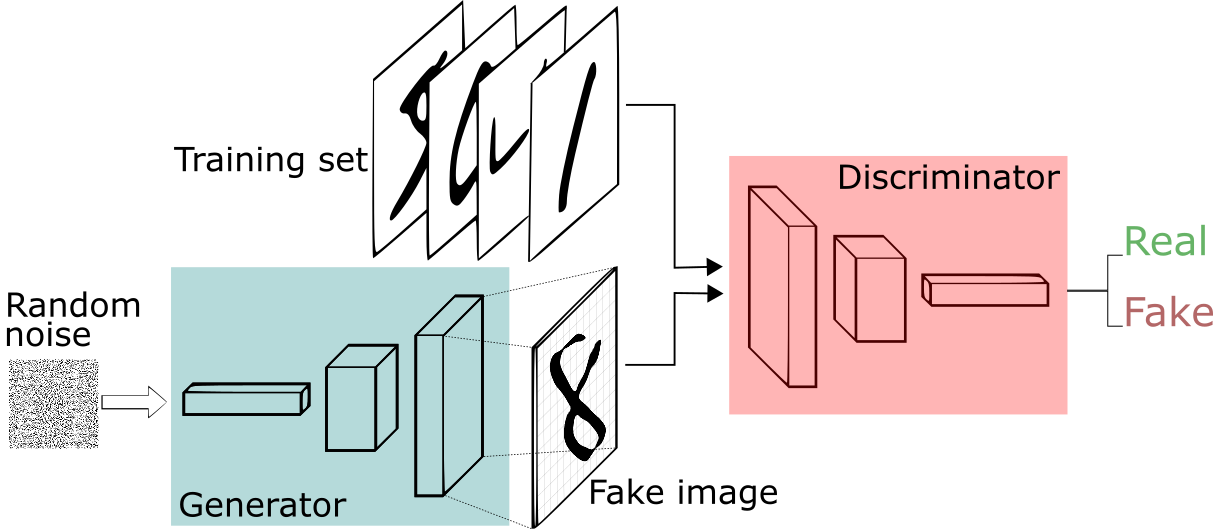
GANはDiscriminatorとGeneratorと呼ばれる2つのネットワークから構成されます。それぞれの目的は以下のとおりです。
| Network | 目的 |
|---|---|
| Generator | 画像の生成 |
| Discriminator | 本物の画像と偽物の画像の識別 |
minimax gameを想像して頂ければ分かりやすいかもしれませんが、GANは2つのネットワークを競わせる形で学習を行っていきます。Generatorは本物に近い画像を生成できるように(Discriminatorを欺けるように)学習をします。Discriminatorでは生成された画像と本物の画像を正しく識別できるように学習をしていきます。これを繰り返し、最終的にDiscriminatorで識別することができなくなるまで学習を行ったGeneratorを用いてFake imagesを作成するのがGANの目的です。
数式等や詳細なアルゴリズムはこちらを見て頂ければ分かりやすいかと思います。
はじめてのGAN
Pokemon_GAN
Pix2Pix
今回使用した手法がPix2Pix4と呼ばれる、GANの拡張手法です。
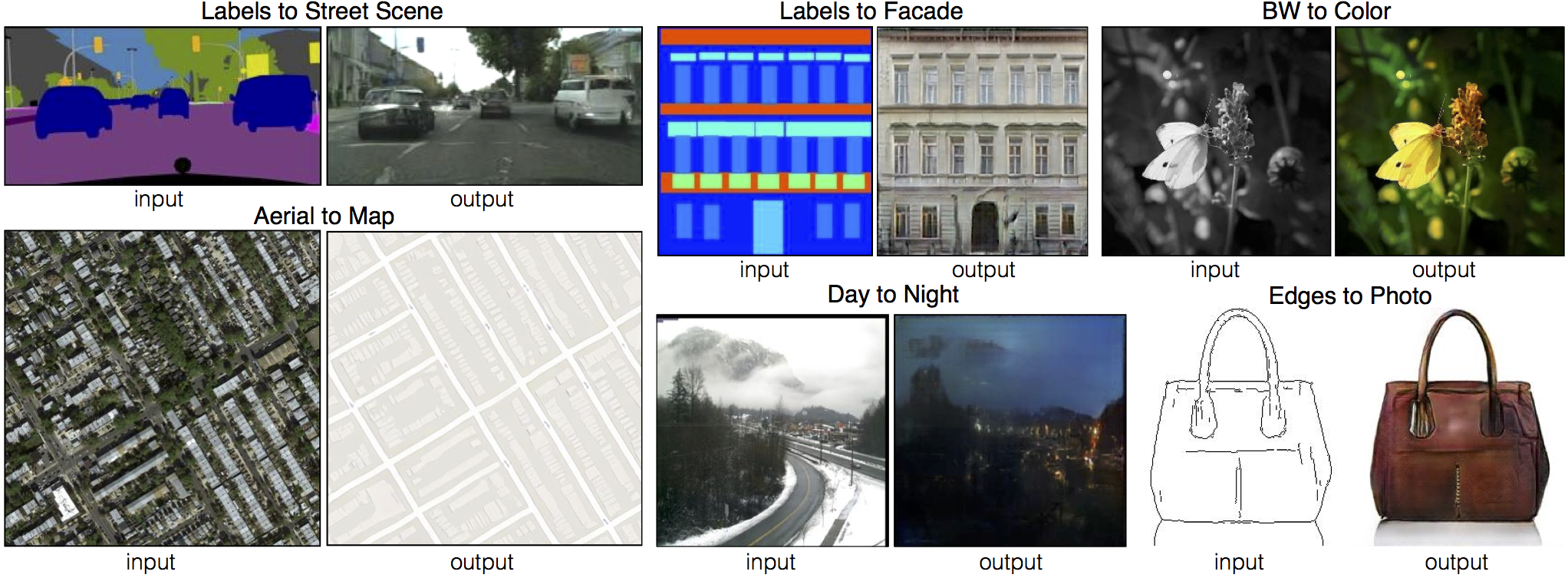
Pix2Pixではある入力をされた画像を、本物っぽい画像に変換することが可能です。例えば上図の場合、カバンの線画を入力として与えた場合、それに着色を行い本物のカバンのような画像を出力します。
GANと異なる点としては、2つの画像のペアを用いて学習するということです。例として、線画のキティちゃんの着色を考えます。下図のように、線画をGeneratorに入力し、出力として色付きキティちゃんを得るのが目的です。
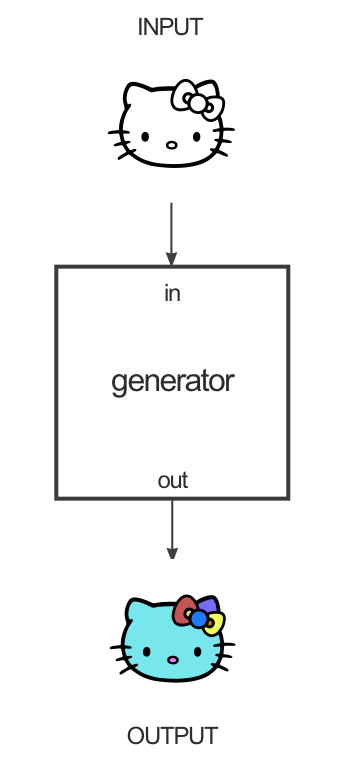
Discriminatorでは、「入力 + 正しい色のキティちゃん」と「入力 + 生成された色付きキティちゃん」の識別を行います。
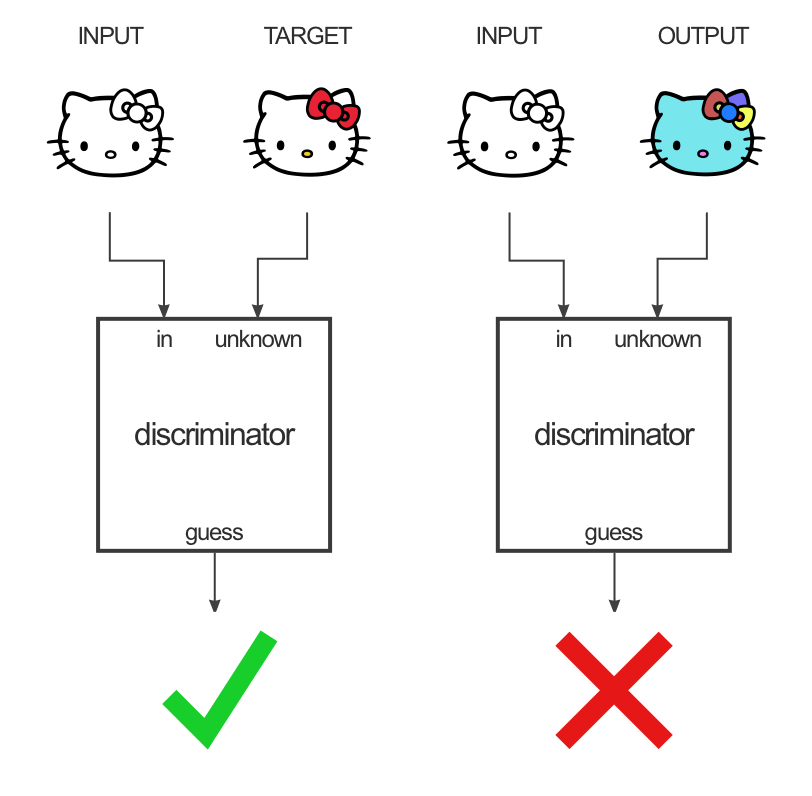
ペア画像に対しこれらを繰り返し学習していくことで、片方の入力を得た際に、もう一方の画像を出力するのがPix2Pixです。
Deep Leaning based Virtual YouTuber
ここからが本題です。今回のプロジェクトでは、先に紹介したPix2Pixを用いています。「Face landmark + 実際の画像」をペアとして学習を行い、作成したモデルに、リアルタイムで取得されたlandmarkを入力し、あたかもベースとなった人間が動いているかのような出力をすることで、Vtuberのような形式を目指します。
今回は以下のリポジトリをForkし開発を行いました。Dat Tran様に感謝致します。
Thank you, datitran (Dat Tran) ! I really appreciate it.
datitran/face2face-demo
とりあえず色々調整して学習して動かしてみた
結果がこちらです。

左側の線画がリアルタイムで取得した私の動きで、右側が出力となっています。
(本当は一番左に私の顔が写っているのですが、恥ずかしいのでカットしています。)
結構ちゃんと動いてます。
データを変更し学習しても、そこそこの物が出来上がりました。WebカメラとGPUだけでここまでできるなんて凄いなーというのが私の感想です。他人の顔を動かすような研究はたくさん行われていそうなので、こんなものかと思われる方もいるかもしれません。実際、世界初のAIニュースキャスターが中国で誕生するなど、GANの精度は日に日に向上しています。
Xinhua's first English #AI anchor makes debut at the World Internet Conference that opens in Wuzhen, China Wednesday pic.twitter.com/HOkWnnfHdW
— China Xinhua News (@XHNews) 2018年11月7日
法律的な問題点
GANを使う以上、元となる人物のデータが必要となります。先ほどの例では、ドイツのメルケル首相を使用しました。また、遊びではじめしゃちょーのモデルも作成しました。ここで、問題になってくるのが法律的な問題です。
実は日本には著作権法には47条の7という、世界的に見ても珍しい条文があります。簡単に言えば「情報解析が目的であれば、著作権者の承諾なしに自由に使用ができる」といった内容です。しかも、非営利目的の利用に限定されていません。我々AI開発者・研究者にとっては天国のような内容です。
しかし、情報解析に機械学習が含まれているのかどうかといった解釈や、他の法律(他国含む)等を考慮すると怪しい気がしてきます。そこで、「動物のデータなら大丈夫ではないか?」と考えました。以降は動物のデータを用いた取り組みについてご紹介していきます。
Animal Model
前処理
人間でも動物でも、Pix2Pixを使う以上ペアの画像を作成する必要があります。前処理の流れは大まかに、このようになっています。
- データ(動画)入手
- フレーム分解
- 分解した画像からLandmarkを取得
- フレーム分解した画像とLandmarkをペアとして学習
今回、最も苦戦したのが「3. 分解した画像からLandmarkを取得」です。人間のlandmark検出であれば、OpenCVやdlibといったライブラリを使えば簡単かつ、高精度に検出することが可能です。しかし、動物のlandmark検出となると話しは変わってきます。
Object detectionでは「どこに、何の動物がいるか」の検出は可能です。しかし、それぞれの動物の顔の特徴までは検出できません。調べた限り、動物の顔の特徴抽出器も多くは存在しません。(需要ないだろうし)

Landmark detectorを作成するには、顔がもつ特徴点を画像ごとに記録し学習を行う必要があります。人間であれば、画像のように60個以上ある特徴点の座標を1枚ごとに記録する必要があります。学習には数千枚を超えるデータが必要であるため、これを1から作るのは現実的ではありません。
猫の特徴抽出
そこで、頑張って探し辿り着いたpycatfdを一部改変し、使用することにしました。
marando/pycatfd

抽出された特徴点の座標をもとに、以下のような画像を生成するプログラムを作成しました。

pycatfdですが、猫が少しでも横を向くと検出ができなくなってしまう(または、誤検出がおこる)という問題があります。また、そもそもの検出精度も悪く化物のようなデータになってしまいます。そこで、取得した特徴点から、様々な処理を行ったデータを用意し、実験を行いました。行った処理内容は以下の通りです。
| データ(動画) | 処理内容 |
|---|---|
| ①某CMに登場する猫 | 無処理 |
| ②某CMに登場する猫 | データ選定 |
| ③某CMに登場する猫 | 耳なし |
| ④某CMに登場する猫 | 擬似耳 |
| ⑤YouTubeに投稿された猫 | データ拡張 反転 |
| ⑥YouTubeに投稿された猫 | データ拡張 反転 + 縮尺変更 |
- ②服を着ていたり、帽子を被っていたりする画像を削除
- ③耳の検出が不安定なため、耳がないlandmark画像を作成
- ④耳の検出が不安定なため、座標を指定して擬似的な耳を作成
- ⑤⑥使いやすそうなデータが見つかったため、データを変更
- ⑤データ数が少ないため、水平方向に反転した画像を追加
- ⑥反転に加え、縮尺を変更することでノイズに強くなるのではないかと予想
色んな試行錯誤をした結果
最も悪かった結果 (前処理①)

最も良かった結果 (前処理⑤)

考察
遠くから見れば猫っぽいかな... くらいの精度でした。
原因としては大きく分けて、以下の2つだと考えています。
-
特徴の違い
猫の特徴を学習したモデルに、人間の特徴を入力しているため、精度に影響したと考えられれます。今回は人間の目と顔の輪郭のみを入力としました。(他の特徴も入力すると精度が下がったため)そのため、特徴の変換器みたいなものを作成する必要がありそうです。 -
データ
猫の特徴抽出の説明において、検出精度が低いと記述しました。下の画像の耳が垂れている猫のように、ありえない画像を学習に使ってしまったのも原因と考えられます。

終わりに
精度向上の余地はありそうですが、一旦開発はここで終了としています。実は開発メンバーの中にGANを専門に勉強、研究をしている人間はいませんでした。そのため、感想やコメント、アドバイスを頂ければ幸いです。最後まで読んでいただきありがとうございました。
Github
整理中(2019/02/26)
gojirokuji/dtuber
-
株式会社ユーザーローカル, バーチャルYouTuber、本日6000人を突破(ユーザーローカル調べ), https://www.userlocal.jp/news/20181219vs/ ↩
-
株式会社ユーザーローカル, バーチャルYouTuber、本日7000人を突破(ユーザーローカル調べ), https://www.userlocal.jp/news/20190221vn/ ↩
-
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio, Generative Adversarial Networks, arXiv:1406.2661, https://arxiv.org/abs/1406.2661 ↩
-
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros, Image-to-Image Translation with Conditional Adversarial Networks, arXiv:1611.07004, https://arxiv.org/abs/1611.07004 ↩