本記事は、Dhilip Subramanian氏による「6 Cool Python Libraries That I Came Across Recently」(2021年7月12日公開)の和訳を、著者の許可を得て掲載しているものです。
最近見つけたクールなPythonライブラリ6選
機械学習のためのすごいPythonライブラリ

Image by Free-Photos from Pixabay
はじめに
Pythonは機械学習に不可欠な要素で、ライブラリは作業をより単純にしてくれます。最近、MLのプロジェクトに取り組んでいる時に、素晴らしいライブラリを6つ見つけました。ここでは、それを紹介します。
1. clean-text
clean-textは本当に素晴らしいライブラリで、スクレイピングやソーシャルメディアデータを処理する時にまず使うべきものです。最も素晴らしい点は、データをクリーンアップするために長く凝ったコードや正規表現を必要としないことです。
いくつかの例を見てみましょう。
インストール
!pip install cleantext
例
# Importing the clean text library
from cleantext import clean
# Sample text
text = """ Zürich, largest city of Switzerland and capital of the
canton of 633Zürich. Located in an Al\u017eupine.
([https://google.com](https://google.com/)). Currency is not ₹"""
# Cleaning the "text" with clean text
clean(text,
fix_unicode=True,
to_ascii=True,
lower=True,
no_urls=True,
no_numbers=True,
no_digits=True,
no_currency_symbols=True,
no_punct=True,
replace_with_punct=" ",
replace_with_url="",
replace_with_number="",
replace_with_digit=" ",
replace_with_currency_symbol="Rupees")
出力

上記から、Zurichという単語にUnicod(「u」の文字がエンコードされている)、ASCII文字(Al\u017eupine)、ルピー通貨記号、HTMLリンク、句読点を含むことがわかります。
clean関数では、必要なASCII、Unicode、URL、数値、通貨、句読点を指定するだけです。または、置換パラメータに置き換えることもできます。例えば、ルピー記号をRupeesに変更しました。
正規表現や長いコードは全く必要ありません。特に、スクレイピングやソーシャルメディアデータからテキストをクリーンアップしたい場合は、非常に便利なライブラリです。必要に応じて、引数をすべて組み合わせるのではなく、個別に渡すこともできます。
詳細については、GitHubリポジトリを確認してください。
2. drawdata
drawdataは、もう1つの便利なpythonライブラリです。MLの概念をチームに説明しなければならない状況に、何回遭遇しましたか?データサイエンスはチームワークが大事なので、よくあることでしょう。このライブラリは、Jupyterノートブックにデータセットを描くのに役立ちます。
個人的には、MLの概念をチームに説明する時に、このライブラリを使うのはとても楽しかったです。このライブラリを作成した開発者に賛辞を送ります!
drawdataは、4つのクラスの分類問題のみを対象としています。
インストール
!pip install drawdata
例
# Importing the drawdata
from drawdata import draw_scatter
draw_scatter()
出力

著者による画像
draw_Scatter()を実行すると、上記の描画ウィンドウが開きます。明らかに、A、B、C、Dの4つのクラスがあります。任意のクラスをクリックして、好きな点を描画できます。各クラスは、描画中に異なる色を描画します。データをcsvまたはjsonファイルとしてダウンロードするオプションもあります。また、データをクリップボードにコピーして、下記のコードから読み取ることもできます。
# Reading the clipboard
import pandas as pd
df = pd.read_clipboard(sep=",")
df
このライブラリの限界の1つは、4つのクラスで2つのデータポイントしか提供しないことです。しかしそれ以外の点では、このライブラリを使う価値は十分あります。
詳細については、GitHubリンクを確認してください。
3. Autoviz
matplotlibを使って探索的データ分析をしていた時のことは一生忘れないでしょう。多くの単純な可視化ライブラリがありますが、最近、1行のコードであらゆるデータセットを自動的に可視化するAutovizを知りました。
インストール
!pip install autoviz
例
この例では、IRISデータセットを使用しました。
# Importing Autoviz class from the autoviz library
from autoviz.AutoViz_Class import AutoViz_Class
# Initialize the Autoviz class in a object called df
df = AutoViz_Class()
# Using Iris Dataset and passing to the default parameters
filename = "Iris.csv"
sep = ","
graph = df.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
上記のパラメータはデフォルトです。詳細については、こちらを確認してください。
出力
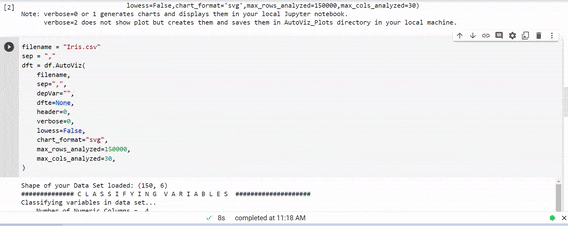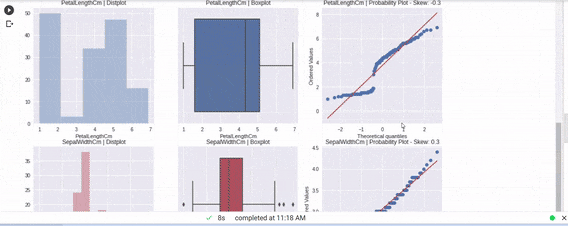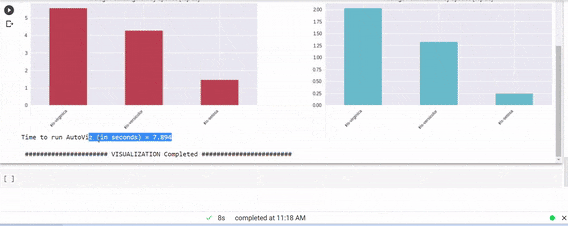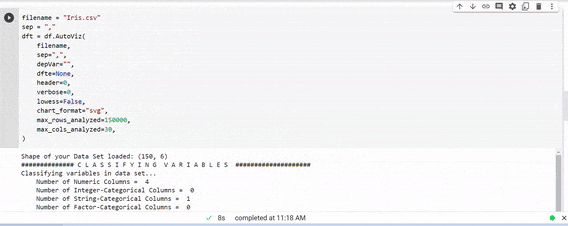
著者による画像
たった1行のコードで、全ビジュアルを確認し、EDAを完成させることができます。多くの自動可視化ライブラリがありますが、特にこのライブラリに慣れ親しむのはとても楽しかったです。
4. Mito
みんなExcelが好きですよね?Excelはデータセット探索の最も簡単な最初の方法の1つです。Mitoに出会ったのは数ヶ月前ですが、使ってみたのはつい最近で、とても気に入りました!
これはJupyter-lab拡張Pythonライブラリで、表計算機能を追加するGUIをサポートしています。csvデータを読み込み、データセットをスプレッドシートとして編集すると、自動的にPandasコードを生成します。とてもクールです。
Mitoを紹介するには、ブログ1記事を要します。しかし、今日はあまり詳しく説明しません。代わりに、簡単なタスクのデモを紹介します。詳細については、こちらを確認してください。
インストール
# First install mitoinstaller in the command prompt
pip install mitoinstaller
# Then, run the installer in the command prompt
python -m mitoinstaller install
# Then, launch Jupyter lab or jupyter notebook from the command prompt
python -m jupyter lab
インストールの詳細については、こちらを確認してください。
# Importing mitosheet and ruuning this in Jupyter lab
import mitosheet
mitosheet.sheet()
上記のコードを実行すると、jupyter labでmitosheetが開きます。私はIRISデータセットを使用しています。まず、2つの新しい列を作成します。1つはがく片長、もう1つはがく片幅の合計です。次に、平均がく片長の列名を変更します。最後に、平均がく片長の列のヒストグラムを作成します。
この手順を実行すると、コードが自動的に生成されます。
出力

著者による画像
上記の手順で、以下のコードが生成されました。
from mitosheet import * # Import necessary functions from Mito
register_analysis('UUID-119387c0-fc9b-4b04-9053-802c0d428285') # Let Mito know which analysis is being run
# Imported C:\Users\Dhilip\Downloads\archive (29)\Iris.csv
import pandas as pd
Iris_csv = pd.read_csv('C:\Users\Dhilip\Downloads\archive (29)\Iris.csv')
# Added column G to Iris_csv
Iris_csv.insert(6, 'G', 0)
# Set G in Iris_csv to =AVG(SepalLengthCm)
Iris_csv['G'] = AVG(Iris_csv['SepalLengthCm'])
# Renamed G to Avg_Sepal in Iris_csv
Iris_csv.rename(columns={"G": "Avg_Sepal"}, inplace=True)
5. Gramformer
Gramformerはもう1つの印象的なライブラリです。生成モデルに基づいており、文の文法を修正するのに役立ちます。このライブラリには、検出、強調表示、修正の3つのモデルがあります。検出はテキストの文法エラーを識別し、強調表示は品詞のミスをマークし、修正はエラーを修正します。Gramformerは完全なオープンソースで、まだ初期段階です。ただし、文レベルでのみ動作し、64文字長の文章で学習されているため、長い段落には適しません。
現在のところ、修正と強調表示のモデルが機能しています。いくつかの例を見てみましょう。
インストール
!pip3 install -U
git+https://github.com/PrithivirajDamodaran/Gramformer.git
Gramformerインスタンス化
gf = Gramformer(models = 1, use_gpu = False) # 1=corrector, 2=detector
(presently model 1 is working, 2 has not implemented)

例
# Giving sample text for correction under gf.correct
gf.correct(""" New Zealand is island countrys in southwestern Paciific Ocaen. Country population was 5 million """)
出力

著者による画像
上記の出力から、文法やスペルミスまで修正していることが分かります。本当に素晴らしいライブラリで、機能も非常に優れています。ここでは強調表示を試していませんが、詳細については、GitHubドキュメントで確認してください。
6. Styleformer
Gramformerでの良い経験から、もっと優れたライブラリを探すようになりました。そのようにして見つけたのが、この非常に魅力的なライブラリStyleformerです。GramformerもStyleformerもPrithiviraj Damodaran氏が作成したもので、どちらも生成モデルに基づいています。このライブラリをオープンソース化した作者に賛辞を送ります。
Styleformerは、カジュアルな文章からフォーマルな文章へ、フォーマルな文章からカジュアルな文章へ、能動態から受動態へ、受動態から能動態への変換をサポートします。
いくつかの例を見てみましょう。
インストール
!pip install
git+https://github.com/PrithivirajDamodaran/Styleformer.git
Styleformerインスタンス化
sf = Styleformer(style = 0)
# style = [0=Casual to Formal, 1=Formal to Casual, 2=Active to Passive, 3=Passive to Active etc..]
例
# Converting casual to formal
sf.transfer("I gotta go")

# Formal to casual
sf = Styleformer(style = 1) # 1 -> Formal to casual
# Converting formal to casual
sf.transfer("Please leave this place")

# Active to Passive
sf = Styleformer(style = 2) # 2-> Active to Passive
# Converting active to passive
sf.transfer("We are going to watch a movie tonight.")

# passive to active
sf = Styleformer(style = 2) # 2-> Active to Passive
# Converting passive to active
sf.transfer("Tenants are protected by leases")

上記の出力を見ると、正確に変換されています。私は、特にソーシャルメディアへの投稿の分析で、カジュアルからフォーマルへ変換するのに使いました。詳細については、GitHubを確認してください。
おわりに
先に挙げたライブラリのいくつかはよく知っているかもしれませんが、GramformerやStyleformerなどは最近のものです。これらは非常に過小評価されていますが、知っておく価値があります。私の時間を大幅に節約してくれ、NLPプロジェクトでよく使用していました。
お読みいただきありがとうございます。もし追加があれば、気軽にコメントをお寄せください!
以前の記事「データサイエンスのためのクールなPythonライブラリ5選」もおすすめです。
翻訳協力
この記事は以下の方々のご協力により公開する事ができました。改めて感謝致します。
Original Author: Dhilip Subramanian (https://www.linkedin.com/in/dhilip-subramanian-36021918b/)
Original Article: 6 Cool Python Libraries That I Came Across Recently
Thank you for letting us share your knowledge!
選定担当: @gracen
翻訳担当: @gracen
監査担当: -
公開担当: @gracen
こちらもどうぞ
朝飯前に学べる!便利なPythonのヒント100選【前編】 【後編】
Python開発者のためのクールなPythonプロジェクト案10選
ご意見・ご感想をお待ちしております
今回の記事はいかがでしたか?
・こういう記事が読みたい
・こういうところが良かった
・こうした方が良いのではないか
などなど、率直なご意見を募集しております。
頂いたお声は、今後の記事の質向上に役立たせて頂きますので、お気軽に
コメント欄にてご投稿ください。Twitterでもご意見を受け付けております。
皆様のメッセージをお待ちしております。