はじめに
オンプレ環境のGPUを持っていないので、私はAWSでGPUインスタンスを立ててディープラーニングを行っている。
学習データを利用する際、EC2内に一時ディレクトリを作成して、そこにS3から学習データをダウンロードして使うことで、以下のような利点が得られるんじゃないかと思ったので、紹介する。
EC2インスタンス上にデータを入れっぱなしにしておくよりも、プログラムの実行が終わった際にEC2インスタンスからデータが消去される、かつS3に出力結果が上がるため、セキュリティの強化、出力結果紛失の危険性低減、EBS(ストレージ)の節約になる。
この記事では、EC2インスタンス内に一時ディレクトリを作成し、そこにS3からファイルをダウンロードする。
そして、一時ディレクトリからS3へのアップロードするまでを目指す。
必要作業
- EC2にIAMロールの設定
- pythonモジュールのインストール(python3を利用)
- コードの記述
IAMロールの設定
ロールの作成
①AWSマネジメントコンソールからIAMのページに移動
②左のメニュー一覧からロールを選択
③ロールを作成を選択

④ユースケースはEC2を選択
⑤次のステップへ

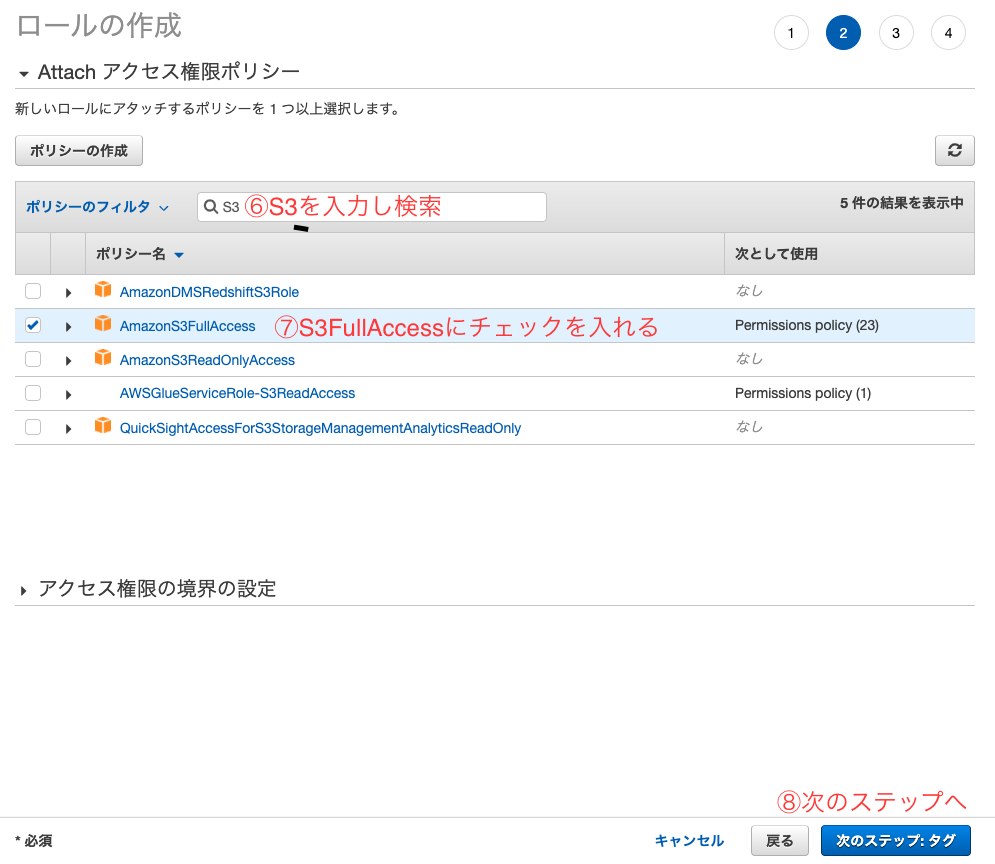
⑥検索窓でS3と入力し検索
⑦AmazonS3FullAccessにチェックマークを入れる
⑧次のステップへ
⑨タグは設定してもしなくてもどちらでも良いが、複数人でAWSを利用している場合は、管理のしやすさのため、Userのみ設定しておくと良い
⑩次のステップへ

⑪任意のロール名をつける(ロール名から何ができるロールなのかわかるようにしておくと楽)
⑫ロールの作成

EC2インスタンスへのIAMロールの割当
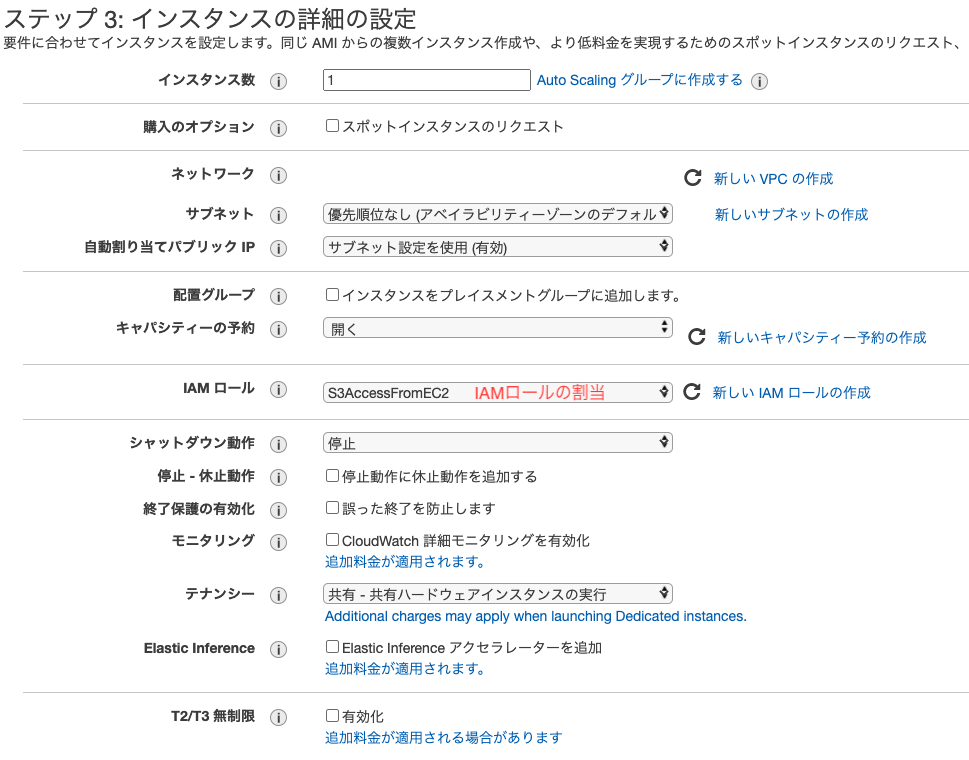
EC2インスタンスを作成する際に先程作成したIAMロールを割り当てる
※インスタンス作成時にしかロールの割当できないかも?作成後にロールが割り当てられるかは要検証
pythonモジュールのインストール
必要モジュール
AWSモジュール
- boto3
一時ディレクトリモジュール - tempfile(python標準モジュールのためインストール不要)
インストールコマンド
pip install boto3
コードの記述
以下のコードをノートブックファイルや.pyファイルにコピペすればダウンロード及びアップロードの完了
ダウンロード元やアップロード先の設定
import boto3
import tempfile
# ダウンロード元バケット名
bucket_name = 'hogehoge'
# アップロード先バケット名(今回はダウンロード先と同じ)
out_bucket_name = bucket_name
# バケットにある動画ファイル名
file_name = 'input.mp4'
# アップロード先のフォルダ名
# 下記の例だとS3にresultフォルダが作成され、そこに出力される
out_folder_name = 'result'
一時ディレクトリの作成及びS3からのダウンロード
# 一時保存用ディレクトリの作成
tmpdir = tempfile.TemporaryDirectory()
tmp = tmpdir.name + '/'
# 一時的な入力ファイル名(適当な名前で固定)
# 固定された名前で一時フォルダにダウンロードされる
tmp_input = tmp + 'tmp.mp4'
# S3からファイルをダウンロード
s3_client = boto3.client('s3')
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
bucket.download_file(file_name, tmp_input)
ダウンロードされたファイルの使用例
以下の例はopencvで読み込みをし、何も処理せず一時ディレクトリに別名保存している
(一時ディレクトリにtmp.mp4とoutput.mp4がある状態)
import cv2
# 一時ディレクトリに保存するビデオ名の設定
output_video =tmp + 'output.mp4'
# 動画ファイルを読み込む
video = cv2.VideoCapture(tmp_input)
# 幅と高さを取得
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (width, height)
# 総フレーム数を取得
frame_count = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
# フレームレート(1フレームの時間単位はミリ秒)の取得
frame_rate = int(video.get(cv2.CAP_PROP_FPS))
# 保存用
fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
writer = cv2.VideoWriter(output_video, fmt, frame_rate, size)
for i in range(frame_count):
ret, frame = video.read()
### ここに加工処理などを記述する ###
writer.write(frame)
writer.release()
video.release()
cv2.destroyAllWindows()#ビデオの読み込み
S3へのアップロード
以下の例は先に設定したS3アップロード先にoutput_video.mp4という名前で上で作成したビデオがアップロードされている。
s3.Bucket(out_bucket_name).upload_file(output_video,out_folder_name+'/'+ 'output_video.mp4')
一時ディレクトリの削除
tmpdir.cleanup()
まとめ
それぞれの技術についてもっと細かく解説しているサイトはたくさんあると思うが、それをどうやってうまく組み合わせるのかが意外と難しいと思いこの記事を作成した。