環境
OS: windows 10.0
python: 3.7.3
Anaconda: conda 4.10.1
実施日
2021/07/03
インストール
Anaconda Prompt を管理者として実行

pip install wordcloud
インストール後の確認
wordcloud: 1.8.1
conda list
# packages in environment at C:\ProgramData\Anaconda3:
#
# Name Version Build Channel
(中略)
wordcloud 1.8.1 pypi_0 pypi
(後略)
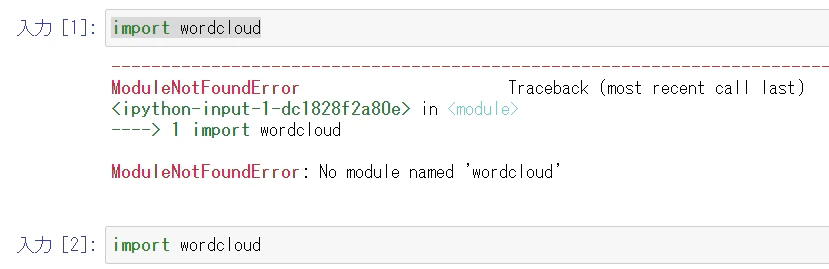
Jupyter notebook だと、入力 [1] はインストール前、入力 [2] はインストール後です。
インプットデータを決める
今日は7月3日だから、青空文庫から正岡子規が119年前(1902年)の同じ日に綴った「病床六尺」の記事をインプットデータにしてみます。

手動でデータを加工する
青空文庫の zip ファイルや html をダウンロードしてフラットなテキストに変換するところは今日の目的じゃあないので、ブラウザに表示された内容から目視で7月3日の記事を探してテキストエディタに流します。
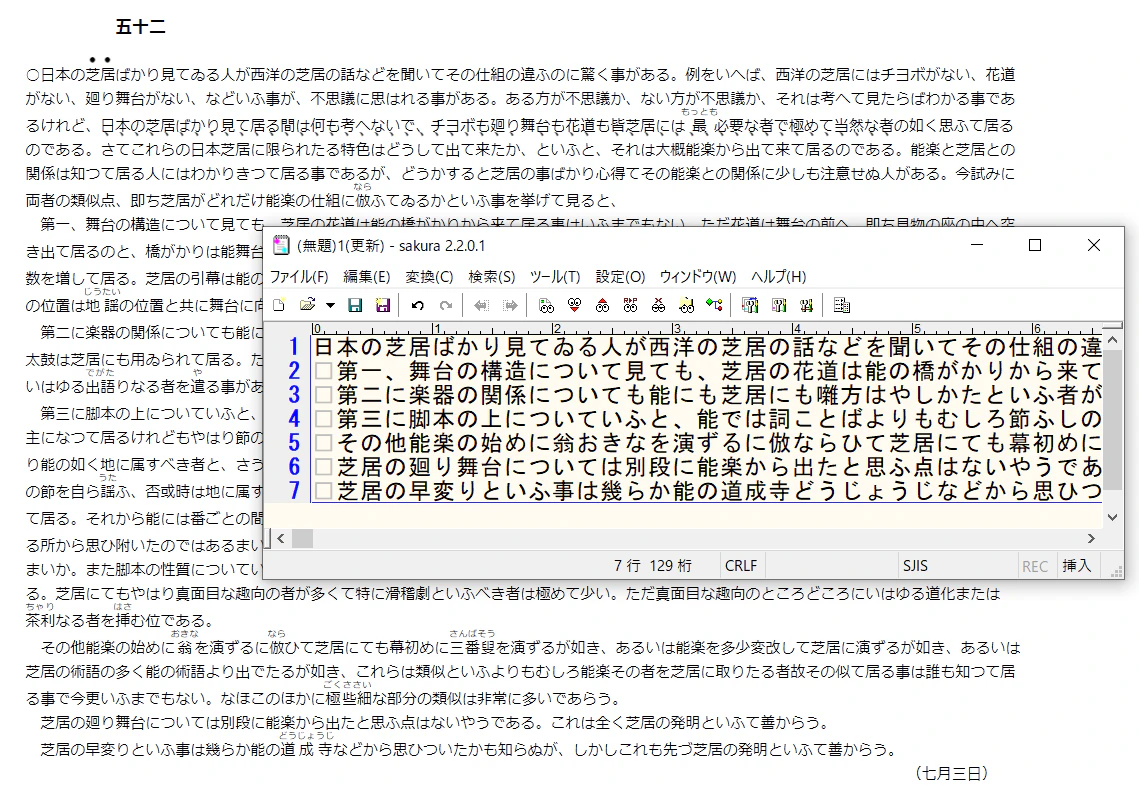
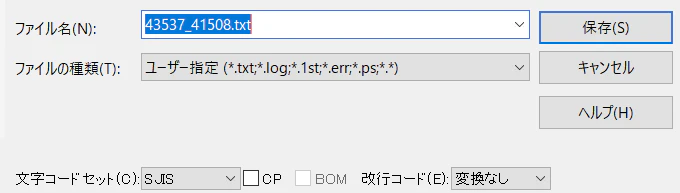
そこからテキストファイルに出力します。
出力のときの文字コードセットは Shift-JIS(CP932) にしておきます。
加工したデータを読み込んで確認しておく
データを格納した同じフォルダで確認してみます。
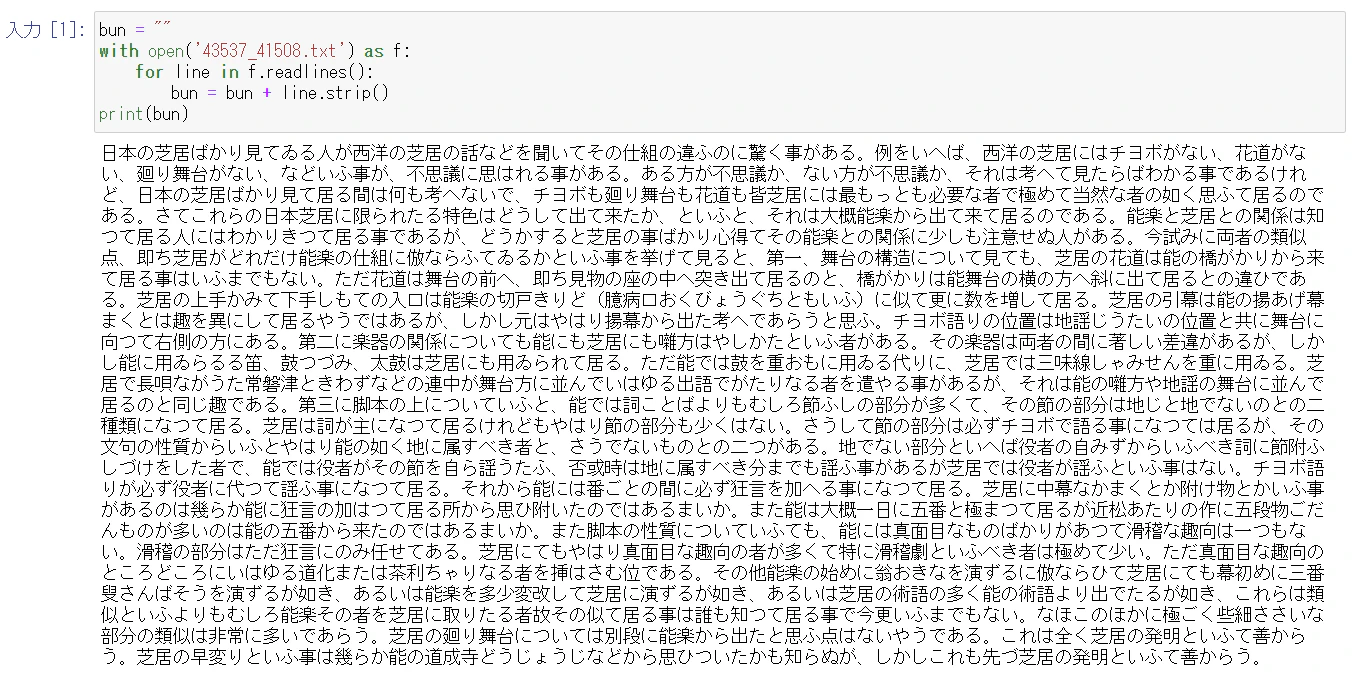
bun = ""
with open('43537_41508.txt') as f:
for line in f.readlines():
bun = bun + line.strip()
print(bun)
大丈夫そうです。
このままWordCloudにかけてみます
これをそのまま WordCloud に渡すとどうなるか試してみます。
import wordcloud
import matplotlib.pyplot as plt
wc = wordcloud.WordCloud(width=1000, height=600, background_color="white",
font_path=r"C:\windows\Fonts\meiryo.ttc")
wc.generate(bun)
plt.imshow(wc)
plt.axis("off")
エラーを出さずに動いてくれたけれど、英語のようにスペースで区切らないとこうなるようです。

分かち書きでやってみる
じゃあ、分かち書きにしてそれを WordCloud に渡してやってみます。
まず分かち書きから。
import MeCab
wakati = MeCab.Tagger('-Owakati')
wakati_bun = wakati.parse(bun)
print(wakati_bun)

WordCloud に渡すと、どうなるかな。
wc.generate(wakati_bun)
plt.imshow(wc)
plt.axis("off")

それらしくなりました。
でもやっぱり「の」とか「は」とかの助詞が多いから省きたい。
名詞と動詞だけが抜き出せればいいかな。形容詞もあったほうがいいかも。
形態素解析で分類してみる
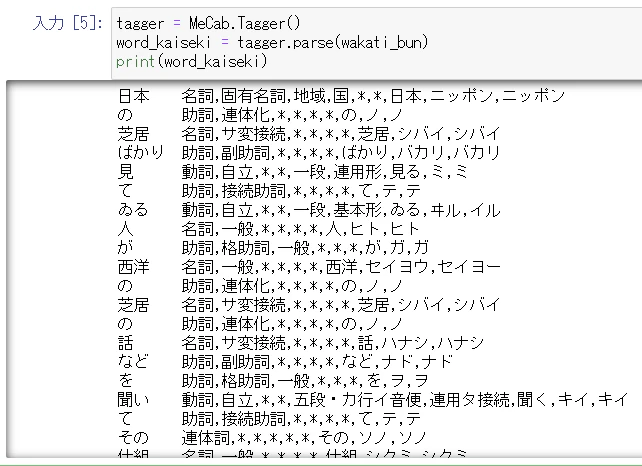
tagger = MeCab.Tagger()
word_kaiseki = tagger.parse(wakati_bun)
print(word_kaiseki)
日本 名詞,固有名詞,地域,国,*,*,日本,ニッポン,ニッポン
の 助詞,連体化,*,*,*,*,の,ノ,ノ
芝居 名詞,サ変接続,*,*,*,*,芝居,シバイ,シバイ
ばかり 助詞,副助詞,*,*,*,*,ばかり,バカリ,バカリ
見 動詞,自立,*,*,一段,連用形,見る,ミ,ミ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
ゐる 動詞,自立,*,*,一段,基本形,ゐる,ヰル,イル
人 名詞,一般,*,*,*,*,人,ヒト,ヒト
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
西洋 名詞,一般,*,*,*,*,西洋,セイヨウ,セイヨー
の 助詞,連体化,*,*,*,*,の,ノ,ノ
芝居 名詞,サ変接続,*,*,*,*,芝居,シバイ,シバイ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
話 名詞,サ変接続,*,*,*,*,話,ハナシ,ハナシ
など 助詞,副助詞,*,*,*,*,など,ナド,ナド
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
聞い 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,聞く,キイ,キイ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
その 連体詞,*,*,*,*,*,その,ソノ,ソノ
仕組 名詞,一般,*,*,*,*,仕組,シクミ,シクミ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
違 名詞,一般,*,*,*,*,*
ふ 動詞,自立,*,*,五段・ラ行,体言接続特殊2,ふる,フ,フ
の 名詞,非自立,一般,*,*,*,の,ノ,ノ
に 助詞,格助詞,一般,*,*,*,に,ニ,ニ
驚く 動詞,自立,*,*,五段・カ行イ音便,基本形,驚く,オドロク,オドロク
事 名詞,非自立,一般,*,*,*,事,コト,コト
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
ある 動詞,自立,*,*,五段・ラ行,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
(中略)
しかし 接続詞,*,*,*,*,*,しかし,シカシ,シカシ
これ 名詞,代名詞,一般,*,*,*,これ,コレ,コレ
も 助詞,係助詞,*,*,*,*,も,モ,モ
先 名詞,一般,*,*,*,*,先,サキ,サキ
づ 名詞,一般,*,*,*,*,*
芝居 名詞,サ変接続,*,*,*,*,芝居,シバイ,シバイ
の 助詞,連体化,*,*,*,*,の,ノ,ノ
発明 名詞,サ変接続,*,*,*,*,発明,ハツメイ,ハツメイ
といふ 助詞,格助詞,連語,*,*,*,といふ,トイフ,トユウ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
善から 形容詞,自立,*,*,形容詞・アウオ段,未然ヌ接続,善い,ヨカラ,ヨカラ
う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ
。 記号,句点,*,*,*,*,。,。,。
EOS
名詞、動詞、形容詞だけを抽出する
カンマで区切った7番目の原型を採用するようにしてみます。
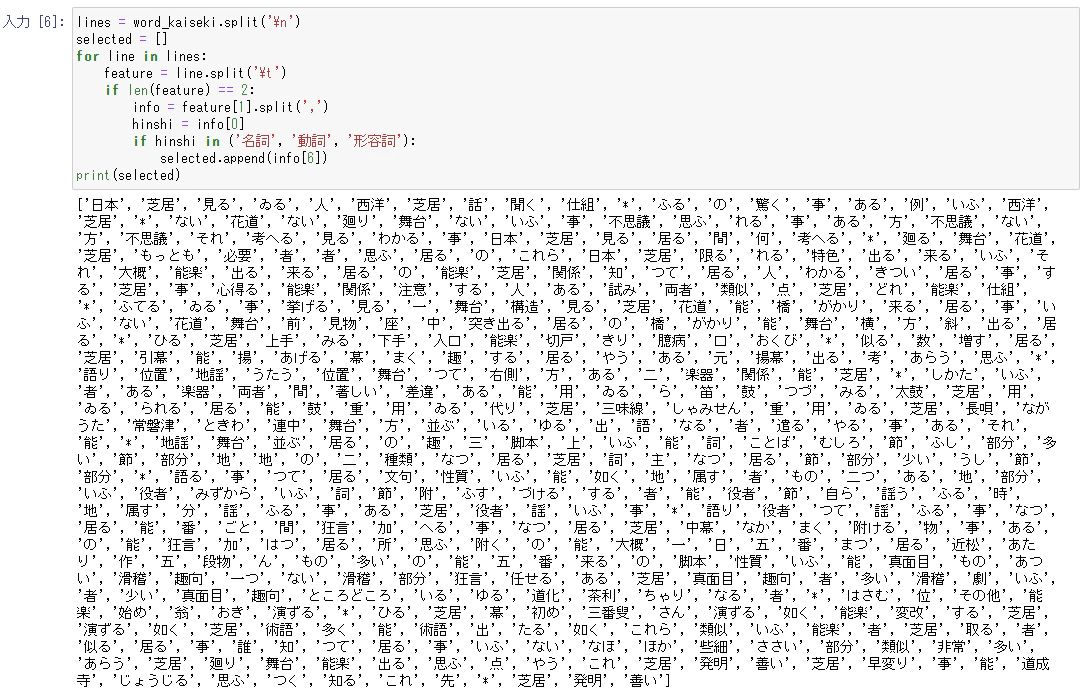
lines = word_kaiseki.split('\n')
selected = []
for line in lines:
feature = line.split('\t')
if len(feature) == 2:
info = feature[1].split(',')
hinshi = info[0]
if hinshi in ('名詞', '動詞', '形容詞'):
selected.append(info[6])
print(selected)
あらためてWordCloudに渡してみる
品詞に分解した単語を半角スペースでつないで、WordCloudに渡します。
wc.generate(" ".join(selected))
plt.imshow(wc)
plt.axis("off")

うん、いいんじゃないでしょうか。
ソースを整理して完成させてみます。
分かち書きにしておかなくても形態素解析はできるので、その箇所は省きます。
import wordcloud
import matplotlib.pyplot as plt
import MeCab
bun = ""
with open('43537_41508.txt') as f:
for line in f.readlines():
bun = bun + line.strip()
wc = wordcloud.WordCloud(width=1000, height=600, background_color="white",
font_path=r"C:\windows\Fonts\meiryo.ttc")
tagger = MeCab.Tagger()
word_kaiseki = tagger.parse(bun)
lines = word_kaiseki.split('\n')
selected = []
for line in lines:
feature = line.split('\t')
if len(feature) == 2:
info = feature[1].split(',')
hinshi = info[0]
if hinshi in ('名詞', '動詞', '形容詞'):
selected.append(info[6])
wc.generate(" ".join(selected))
plt.imshow(wc)
plt.axis("off")

明日はどっちだ
明日の7月4日はアメリカの独立記念日なので
から口語の箇所をテキストにして

with open('43537_41508.txt') as f:
のところを
with open('independent.txt') as f:
に差し替えて実行してみました。

うん、いい感じでできました。