前の記事
次の記事
TL;DR
- ちょっと話題になっているDeepseekを自宅環境で試すよ
- Ollama(AIエンジン)+ OpenWebUI(チャットUI)をWSL+Dockerで動かすよ
- 適切なモデルを選べば、ゲーミングPCでプライベートAIを作れるよ
- みんなもお手持ちのゲーミングPCで動かしてみよう!
はじめに
前回はスマートフォンでLLMを動かしてみました。今回は一歩進んでローカルPCでLLMを動かしてみます。
各技術の紹介
Deepseek
Deepseek は、オープンソースの LLM(大規模言語モデル)を提供するプロジェクトで、高精度な推論能力と効率的な動作を特徴とする。特に、コード補完や文章生成に強く、ローカル環境やクラウド上での運用が可能。WSL や Docker を活用することで、手軽に開発環境を整備できる。
特徴
- オープンソースの LLM
- 高精度な推論能力
- コード補完や文章生成に強み
- ローカル環境やクラウドで運用可能
- Docker で簡単にセットアップ可能
Ollama
Ollama は、ローカル環境で軽量かつ高速に LLM を動作させるためのプラットフォーム。独自のモデル管理機能を持ち、簡単なコマンドで LLM のダウンロードや実行が可能。WSL と Docker を組み合わせることで、Windows 環境でもスムーズに運用できる。
特徴
- ローカルで LLM を動作可能
- 軽量かつ高速な推論
- 独自のモデル管理機能
- シンプルなコマンドで実行・管理可能
- WSL や Docker でのセットアップが容易
OpenWebUI
OpenWebUI は、オープンソースのチャット UI であり、ローカルやクラウド環境で LLM を活用するためのフロントエンドを提供する。直感的な UI により、ユーザーは簡単に AI との対話を行える。WSL や Docker を利用することで、スムーズな導入が可能。
特徴
- オープンソースのチャット UI
- 直感的な操作で LLM と対話可能
- ローカルやクラウド環境で動作
- API を活用してカスタマイズ可能
- Docker による簡単なセットアップ
Docker
Docker は、コンテナ仮想化技術を活用し、アプリケーションの開発・デプロイを容易にするプラットフォーム。環境構築の手間を省き、一貫した実行環境を提供する。軽量で高速な動作が特徴で、WSL 上でもスムーズに動作し、Deepseek や Ollama などの LLM を簡単に運用できる。
特徴
- コンテナベースの仮想化技術
- 環境構築が容易で一貫性を保持
- 軽量かつ高速なアプリケーション実行
- WSL との相性が良く、Windows 環境でも快適
- LLM や Web アプリの運用に最適
WSL(Windows Subsystem for Linux)
WSL は、Windows 上で Linux 環境を動作させるための仕組みで、仮想マシンよりも軽量かつ高速に Linux のコマンドやアプリケーションを実行可能。WSL2 では、Linux カーネルが直接動作し、Docker との連携もスムーズ。LLM や開発環境の構築に最適。
特徴
- Windows 上で Linux 環境を実行可能
- 仮想マシンより軽量で高速
- WSL2 では Linux カーネルがネイティブ動作
- Docker との連携がスムーズ
- LLM や開発環境の構築に最適
導入手順
WSLのインストール
Powershellを管理者モードで開き、以下のコマンドを実行します。
wsl --install
WSL上にollamaをインストール
Ollamaをインストールします。
curl -fsSL https://ollama.com/install.sh | sh
sudo systemctl start ollama
ollama用のユーザを作成します。
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
サービス起動用の設定ファイルを作成します。
nano /etc/systemd/system/ollama.service
or
vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
サービスを再起動が終わればollamaの準備は完了です。次はモデルファイルをダウンロードしましょう。
sudo systemctl daemon-reload
sudo systemctl enable ollama
#### 使っているグラボのメモリ容量を調べる
- ホスト(Windows)上でタスクマネージャを開き、「パフォーマンス」→「GPU」を選択します
- 「専用GPUメモリ」に記載されている容量がメモリ容量です。
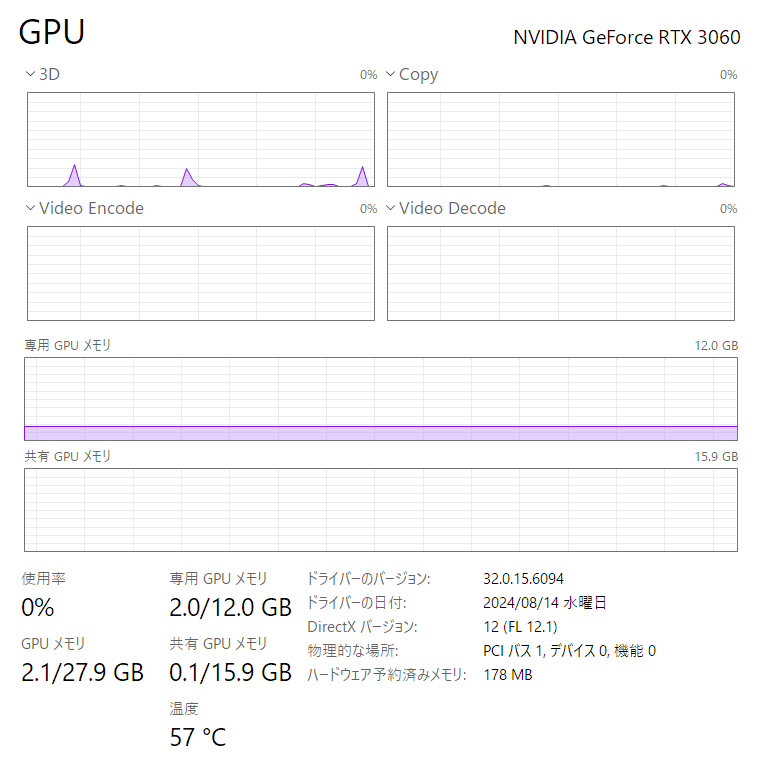
この値はモデルのダウンロード時に使用するのでメモしておきます
WSL上でGPUが認識されているか確認する
以下のコマンドで確認します。
$ /usr/lib/wsl/lib/nvidia-smi
Sat Feb 15 15:57:52 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 On | 00000000:01:00.0 On | N/A |
| 0% 57C P8 19W / 170W | 1914MiB / 12288MiB | 4% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 35 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
$
タスクマネージャに表示されていたGPUが同様に表示されていれば、WSL上で正しくGPUが認識されています。
モデルのダウンロード
今回はサイバーエージェントが日本語を追加学習させた「DeepSeek-R1-Distill-Qwen-14B-Japanese」をダウンロードします。
モデルをダウンロードする前に、手持ちのGPUのRAMに収まるサイズのモデルを探します。
モデルがGPUのメモリに収まらない場合、CPUでの演算がメインとなるので動作が非常に遅くなります。
「GGUF」にあるラベルを押すと、モデルのサイズが表示されます。
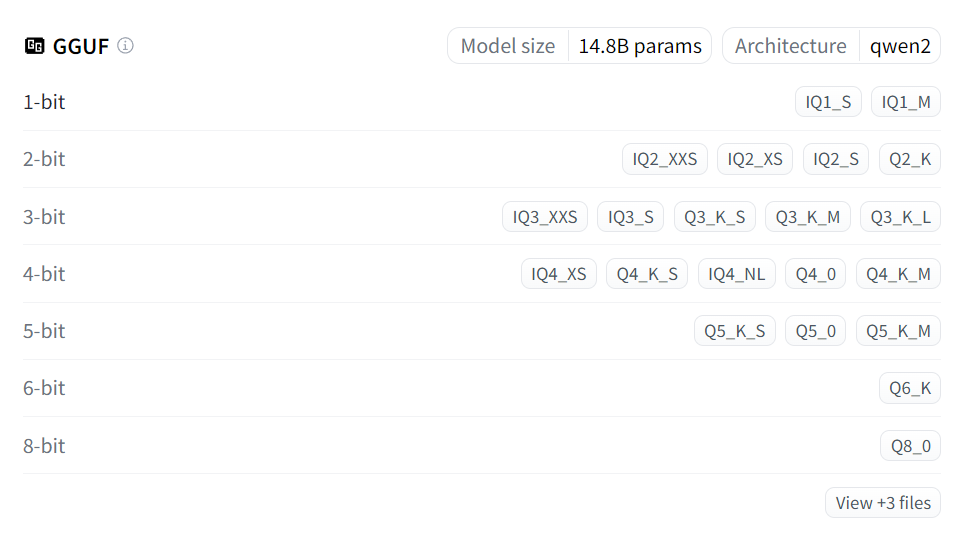

今回動かすグラボはRAMが12GBなので、Q5_K_Mを使用します。
WSLに移り、以下のコマンドを実行します。
ollama pull https://hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:Q5_K_M
一旦使ってみる
以下のコマンドでモデルの読み込みと実行を行います。
$ ollama run https://hf.co/mmnga/cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:Q5_K_M
>>> Send a message (/? for help)
なにかメッセージを入れてみます。終了させるには、/byeを入力します。
>>> こんにちは
<think>
まず、ユーザーからの「おはようございます」という挨拶に適切に対応する必要があります。日本語の文化では、時間帯に合わせ
た挨拶が一般的なので、「おはよう」に対して「おはようございます!」と返すのが自然です。
次に、ユーザーが何を求めているのかを推測します。おそらく、朝の挨拶だけでなく、何か他の情報を求める可能性があります。
例えば、今日の天気や日程確認などですが、具体的な質問がないので、まずは相槌を入れて対話を続けることが重要です。
さらに、丁寧さと親しみやすさをバランスよく保つため、「おはよう」に対して「おはようございます」と返答し、その後に一言
追加する形が良いでしょう。また、ユーザーの状況(例えば朝起きてすぐの時間か通勤中の時間帯など)を考慮すると、柔軟な対
応ができるかもしれません。
最後に、日本語として文法や表現が正しいか確認します。「おはようございます」は適切で、「さあ、今日も元気に頑張りましょ
う!」というフレーズも前向きで励ましの言葉として機能します。これにより、ユーザーが気持ちよくスタートできるような応答
になります。
</think>
**おはようございます!**
朝の光とコーヒーの香り、あなたを包んでいますね。
今日も小さな目標から始めると、予想外の達成感があるものですよ😊
何か特にしたいことはありますか?
>>> /bye
$
WSL上にDockerをインストール
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
$ echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ sudo apt update
$ sudo apt install docker-ce docker-ce-cli containerd.io -y
$ sudo apt install docker-compose -y
$ sudo service docker start
WSL上にOpen WebUIをインストール
まず、WSLのIPアドレスを確認します。
$ ip addr show eth0 | grep "inet "
inet 172.20.156.53/20 brd 172.20.159.255 scope global eth0
$
docker-compose.ymlを作成します。この際、さきほど確認したIPアドレスをWEBUI_URLに指定します。
$ cd ~
$ mkdir openwebui
$ nano docker-compose.yml
or
$ vi docker-compose.yml
services:
# for ollama webui
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- ./volumes/open-webui:/app/backend/data
ports:
- 8980:8080
dns:
- 1.1.1.1
environment: # https://docs.openwebui.com/getting-started/env-configuration#default_models
- OLLAMA_BASE_URLS=http://host.docker.internal:11434
- ENV=dev
- WEBUI_AUTH=False
- WEBUI_URL=http://127.0.0.1:8980
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
Open WebUIの起動
以下のコマンドでOpen WebUIを起動します。
~/openwebui$ docker-compose up -d
Creating network "openwebui_default" with the default driver
Creating open-webui ... done
~/openwebui$
起動が完了したら、Windowsのブラウザからhttp://localhost:8980/にアクセスします。`
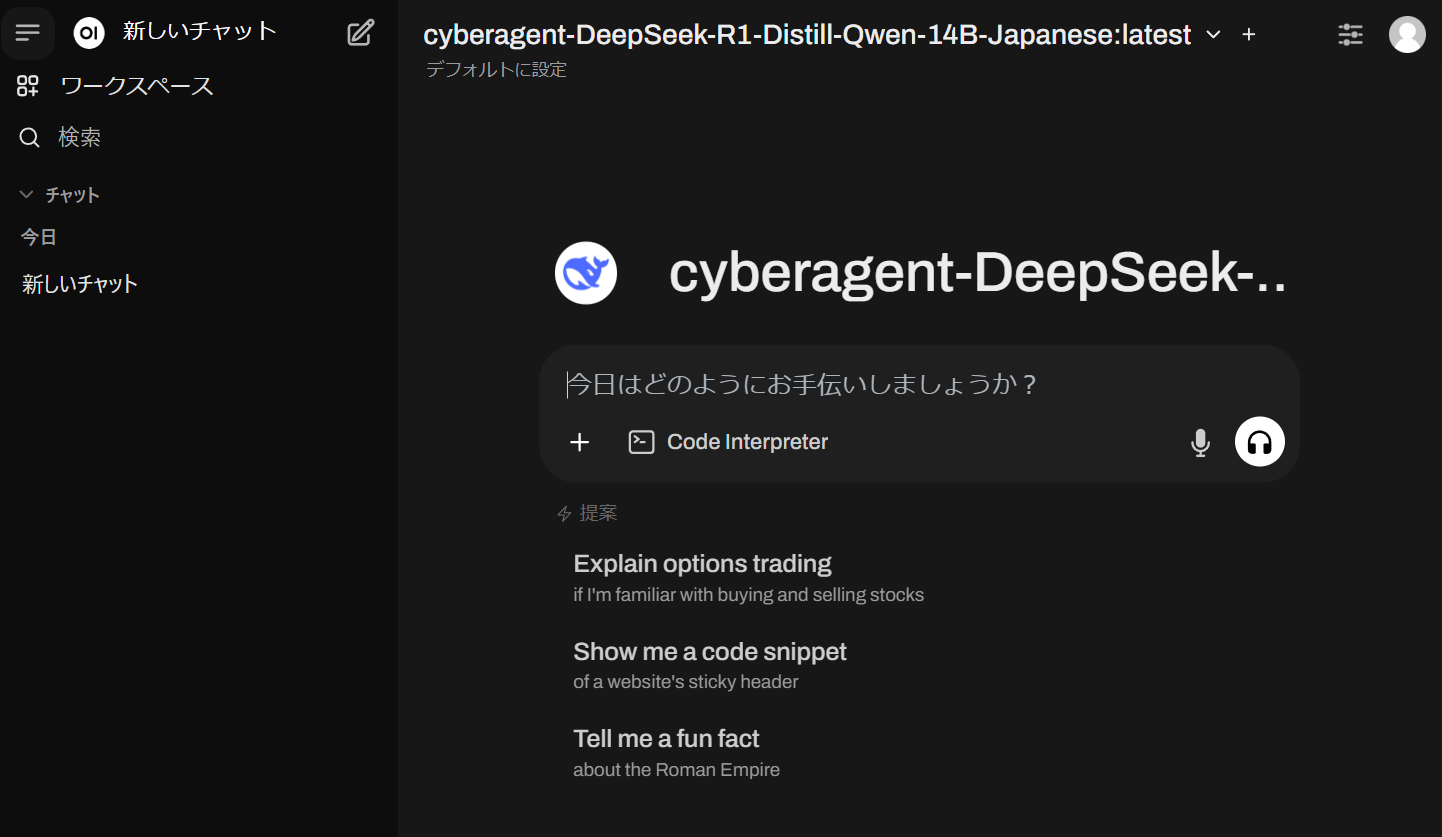
チャット欄が開くので、上部のプルダウンからダウンロードを行ったモデルを選択します。

導入に成功していればよく見るUIでチャットが使えるようになっています。みなさんも是非おうちLLMを楽しんでください!
