PDF Extract API
Adobe Acrobat Servicesの1つであるPDF Extract APIは、PDFからテキストや図、表の情報を文書の構造情報と共に抽出することができます。このAPIにはAdobe SenseiのAIテクノロジが利用され、段組みされている文書も読む流れを考慮して文章を抜き出すことができます。スタイル情報やタイトル、セクションなどの情報も抽出できるので、情報の重要度や構造がわかりやすく抽出したデータを取り扱うことができます。抽出された構造データはJSONデータとして出力されます。また図はPNGとして抽出することができます。表のデータは、CSVまたはXLSXフォーマットで出力することができます。
以下のサイトでPDFの文書の構成と抽出された情報の関連付けをわかりやすく理解することができます。また自分が持っているPDFファイルをアップロードして、抽出機能を試すことができます。手軽に利用できるため、ぜひお試しください。
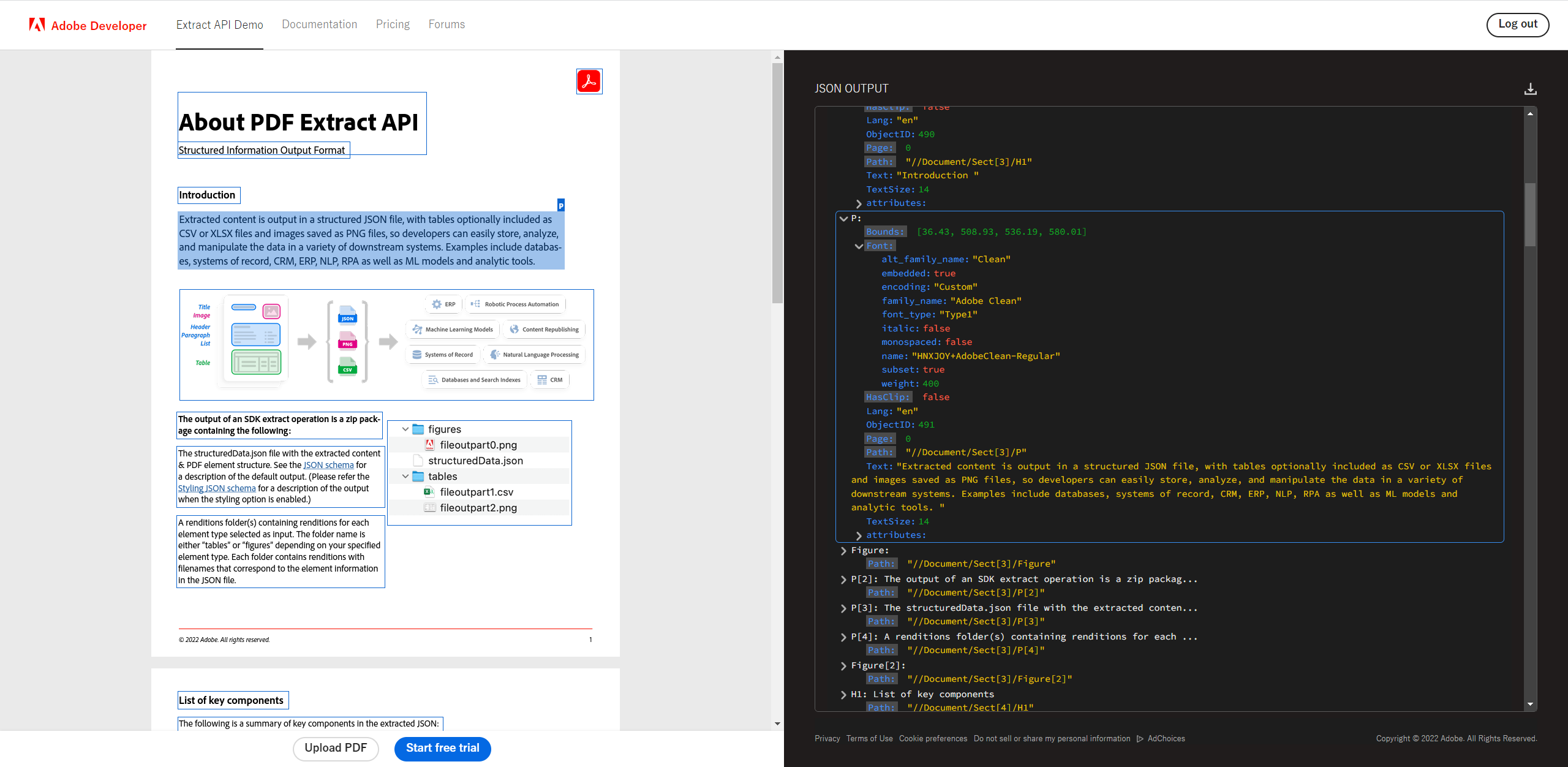
上の図は、当サイトのスクリーンショットで、左側がサンプルのPDFファイル、右側がPDF構造データをJSONフォーマットで表したものです。PDFファイルの解析された構成要素が青枠で表示され、クリックすると、右側にハイライトされます。その中には、位置、フォント、文書構造上の位置(パス)などの情報が示されます。
Extract APIから出力される構造データのJSONのスキーマはこちらから取得できます。
ユースケース
PDFのような非構造化データのから、埋もれた情報を取り出し再利用することは、ビジネスにおいて非常に重要です。PDFの文書を分解したり、表や図をエクスポートすることができるので、新しい情報コンテンツへの再利用が可能です。また、PDFの見積書や請求書のデータを取り込んで会計システムやERPなどに取り込むためのシステムで利用できます。最近ではAIの活用がますます進む中で、学習データに対する各特徴量の重みづけにExtract APIで出力された要素情報を適切に加重することで、より正確な学習モデルを構築することができます。例えば、ヘッダ情報が特定の予測タスクにとって重要である場合は、その特徴量に対して高い重みを付けることができます。
金融データサイエンスの分野の事例として、アドビが公開している三菱UFJトラスト投資工学研究所様の事例では、Extract APIを利用して企業の統合報告書などのPDFファイルから情報を抽出し、データ分析し、株式市場の予測などに利用されています。
APIの利用方法
PDF Extract APIは前回ご紹介したDocument Generation APIと同様、REST APIとして提供されていますので、言語を問わず利用できます。その他Java, .NET, Python, Node.js (JavaScript)をご利用の場合はSDKも用意されています。さらにPower Automateのアクションとしても用意されているので、簡単に試して業務の中でご利用いただくことができます。
ここではJavaを利用して、PDFからテキスト情報と、図、表の情報を抽出する、簡単なサンプルをご紹介します。呼び出し方はいたってシンプルです。コードのコメントをご覧ください。
package com.adobe.sample;
import java.io.IOException;
import java.util.Arrays;
import com.adobe.pdfservices.operation.ExecutionContext;
import com.adobe.pdfservices.operation.auth.Credentials;
import com.adobe.pdfservices.operation.auth.ServiceAccountCredentials;
import com.adobe.pdfservices.operation.exception.ServiceApiException;
import com.adobe.pdfservices.operation.exception.ServiceUsageException;
import com.adobe.pdfservices.operation.io.FileRef;
import com.adobe.pdfservices.operation.pdfops.ExtractPDFOperation;
import com.adobe.pdfservices.operation.pdfops.options.extractpdf.ExtractElementType;
import com.adobe.pdfservices.operation.pdfops.options.extractpdf.ExtractPDFOptions;
import com.adobe.pdfservices.operation.pdfops.options.extractpdf.ExtractRenditionsElementType;
/**
* Adobe Extract APIの簡単な使用サンプル
*
*/
public class SimpleExtractApiApp
{
public static void main( String[] args ) throws IOException, ServiceUsageException, ServiceApiException
{
// Credentialの取得
ServiceAccountCredentials credentials = Credentials.serviceAccountCredentialsBuilder()
.fromFile("pdfservices-api-credentials.json")
.build();
// 抽出のための操作オブジェクトの取得
ExecutionContext executionContext = ExecutionContext.create(credentials);
ExtractPDFOperation operation = ExtractPDFOperation.createNew();
// PDFファイルの入力と操作オブジェクトへのセット
FileRef fileRef = FileRef.createFromLocalFile("input/sample.pdf");
operation.setInputFile(fileRef);
// テキスト、テーブル、図を抽出するようにパラメータをセット
ExtractPDFOptions extractPDFOptions = ExtractPDFOptions.extractPdfOptionsBuilder()
.addElementsToExtract(Arrays.asList(ExtractElementType.TEXT, ExtractElementType.TABLES))
.addElementToExtractRenditions(ExtractRenditionsElementType.FIGURES)
.build();
operation.setOptions(extractPDFOptions);
// 抽出操作を実行
FileRef outFileRef = operation.execute(executionContext);
// 出力結果を保存
outFileRef.saveAs("output/extract-out");
}
}
Credentialの取得については、ここでは詳しく説明しません。Adobe Acrobat Servicesの公式Webサイトから、取得方法をご確認ください。リンクはこちらです。またビルドについては以下の記事もご参照ください。
PDFファイルをinput/sample.pdfに配置してこのコードを実行すると、output/extract-out.zip が出力されます。このZIPファイルの中は以下のように構成されていて、structureData.jsonにはテキストを含む構造情報がエクスポートされて、figuresとtablesの中には、それぞれPNGファイルとXLSXファイルがエクスポートされます。

実践的な対応管理への応用
Extract APIの利用の一例として、対応管理(照会事項管理)のシステム例ご紹介します。
対応管理は、ライフサイエンスの分野において規制当局とのQ&A(質問と回答)のやりとりをまとめるためのシステムです。各国の規制当局からの問合せに対して、一貫性のある回答を行うために、Q&Aをデータとして蓄積し、同様の問い合わせに迅速に回答することができます。PDFにまとめられたQ&Aを分離して、英語や中国語などの多言語で表示することができます。こうした質問と回答の管理は、ライフサイエンス分野にかかわらず、様々な分野で活用できます。

上の画面は、サンプルアプリケーションのスクリーンショットです。上部の四角の枠にPDFファイルをドロップすると、下部の左側にEmbeded APIを使用して読み込んだPDFのプレビューが表示されます。
"Extract"ボタンをクリックすると、PDFファイルがExtract APIで解析され、右側のペインに抽出された質問と回答のセットが表示されます。また、それぞれの英語、中国語への翻訳結果もタブで表示されます。(英語、中国語への翻訳にはGoogleのCloud Translation APIを利用しています)
実際の動作は以下のYouTubeでご覧いただけます。ソースコードはこちらです。
最後に
PDFファイルから情報を自動抽出するPDF Extract APIとその活用法について今回ご紹介しました。PDF Extract APIを活用することで、ビジネス上の問題に対する正確な予測や分析に役立つだけでなく、AIの学習データ作成にも利用することができます。PDF Extract APIを活用して、ビジネスにおける情報の再利用を加速させましょう。