どうも、もう立派な大人なので、会う人会う人に年の瀬という言葉を多用している者です。
今回は、Lambdaの実行上限時間による制限を喰らい、Lambda関数を使ってDBからCognitoへの大量のユーザデータ登録ができなかったので、実行上限時間を回避した方法を紹介します。
目次
- 背景
- Lambdaの実行上限時間を回避する方法を考える
- S3パケットへのPUT起因でLambdaを並列実行させるときのポイント
- おわりに
1.背景
DBに格納されている大量の情報をCognitoに登録したく、Lambda関数を作成して実行しましたが、件数が多すぎてLambdaの実行上限時間を超えてしまいました。また、Lambdaの制約だけではなくCognitoのパフォーマンス観点からも膨大な時間をかけないと、目的を達成できないことがわかりました。
そこで、Lambdaを並列実行させることで、この問題を回避したので、その方法を紹介します。
ちなみに、本記事の執筆時点では、Lambdaの実行上限時間は引き上げられないです。
2.Lambdaの実行上限時間を回避する方法を考える
実行方法を考える
まず、実行上限時間を回避させる方法は、ざっと4種類くらいありますかね?
- 分割処理
1-1:長時間実行するタスクを小さな処理に分割し、複数のLambda関数やステートレスなワークフローで実行する
1-2:StepFunctionsを使って複数のLambdaを連続して呼び出すワークフローを構築する - 異なるサービスの使用
AWS EC2やAWS Fargateのようなサービスを使う - Lambda関数の再トリガー
処理の途中で状態を保存し、再度Lambdaを呼び出す仕組みを構築。SQSやDynamoDBを活用して状態管理する - バッチ
バッチ処理で実行する
今回は、DBからデータを抽出して、そのデータをCognitoへ登録するというユースケースなので、DBからデータを抽出してS3バケットにファイルを格納するLambdaと、S3バケットへのPUT起因でCognitoにデータを登録するLambdaの2つのLambdaを作成しました。ファイルがPUTされるたびに、2つめのLambdaが実行(並列実行
)されます。
実行フロー
- 1つめのLambdaでDBからデータを抽出し、件数ごとにファイルを作成しS3の任意のディレクトリにPUT
- S3にファイルがPUTされることでLambda関数をトリガー
- 2つ目のLambdaが1つ目で抽出したファイルからデータを読み取りCognitoに登録
これによって、S3の特定のディレクトリにPUTされたファイル数分、Lambda関数が並列的に実行されます。ファイルを分割することで、1つのLambdaが実行される時間を短縮できるので、実行上限時間にひっかかることなく処理が完了できました。
3.S3パケットへのPUT起因でLambdaを並列実行させるときのポイント
本章では、ハマりそうなポイントを紹介します。
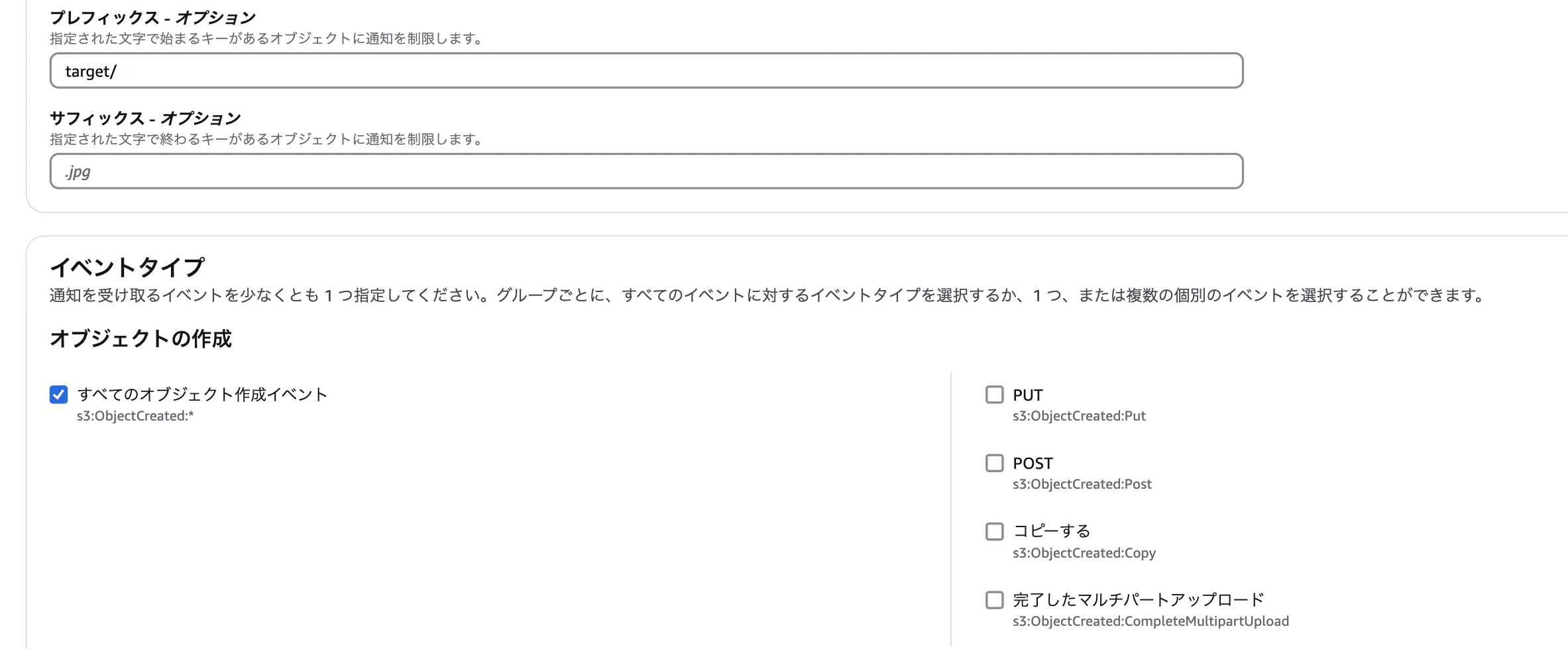
1:S3の設定方法
S3バケットのディレクトリへのイベント発生時の処理は、該当のS3バケット > プロパティ > イベント通知で設定することができます。
ここでは、targetディレクトリに、あらゆるファイルが、あらゆるイベント形式で実行されたときを発動条件と設定しています。
ここでは、トリガーするLambdaを設定します。

これで、targetディレクトリにファイルがputされたときに指定したLambdaへファイル情報を送信することができます。Lambdaではイベントとしてその情報を受け取ります。
2:PUT起因でトリガーされるLambdaに渡すもの
S3からLambdaに渡されるものは、ファイルそのものではなく、ファイルのありかを含むイベント情報が渡されます。Recordsと呼ばれるイベントの中に、ファイルを取得するためのkey情報があるので、そのkey情報を元にファイルとダウンロードすることで、当該Lambdaでファイルを処理することができます。以下に簡易的な例を示します。
import boto3
def lambda_handler(event, context):
s3 = boto3.client('s3')
for record in event['Records']:
bucket_name = record['s3']['bucket']['name']
object_key = record['s3']['object']['key']
# ファイルをダウンロード
s3.download_file(bucket_name, object_key, f"/tmp/{object_key.split('/')[-1]}")
# ファイルを処理
print(f"File {object_key} from bucket {bucket_name} has been downloaded and processed.")
3:Cognitoのパフォーマンス制限(クウォータ制限)のケア
Cognitoでは、一定のリクエスト数を超えるとスロットリングが発生します。
今回、Lambdaを並列実行することで、Lambdaの制限には引っかからないようになりましたが、分割したデータが記述されたファイルの数が多く、Cognitoではスロットリングが発生してしまいました。
これに対処するためには、以下2つの方法があります。
- リクエスト上限の引き上げをAWSに申請する
- ファイルを直接targetディレクトリにPUTするのではなく、tmpディレクトリにPUTし、Cognitoへの登録状況に合わせて、手動でファイルをtmpディレクトリからtargetディレクトリにアップロードする
ちなみに現時点で、Lambdaは実行上限時間を引き上げることはできませんが、Cognitoのクウォータは引き上げることができちゃいます。
おわりに
今回は、Lambdaの実行上限時間を回避するために、S3バケットへのPUT起因でLambdaを並列実行させる方法を紹介しました。
対戦ありがとうございました。