はじめに
Dataiku DSSチュートリアルのScoringをやってみました(ver7.0以上)。
ちなみにこの記事は、以下のシリーズの第5弾となります。
第4弾であるTutorial: Machine Learningの続きになっていますのでご注意ください。
Dataiku DSSをVirtual Boxを使って利用する方法
Tutorial: Basics(投稿記事、元記事)
Tutorial: From Lab to Flow( 投稿記事、元記事 )
Tutorial: Machine Learning(投稿記事、元記事)
Tutorial: Scoring(今回はここです、元記事)
ちなみに今回使ったDataiku DSSのメジャーバージョンは7です
概要
Tutorial:Scoring
https://academy.dataiku.com/latest/tutorial/scoring/index.html
テーマは変わらず「高収益顧客の分析」です。
今までは、高収益顧客かどうかわかっている、既存の顧客に対して、予測モデルを作成し、精度について論じていました。
今回は、高収益顧客かどうかわからない、新規顧客について高収益顧客かどうかの予測を行っていきたいと思います。
使用プロジェクトについて
前回のTutorial:Machine Learning projectの続きからはじまります。
前回の記事を実施していない方は、実施してからこちらをご参照ください。
フローは以下のようになっているはずです。
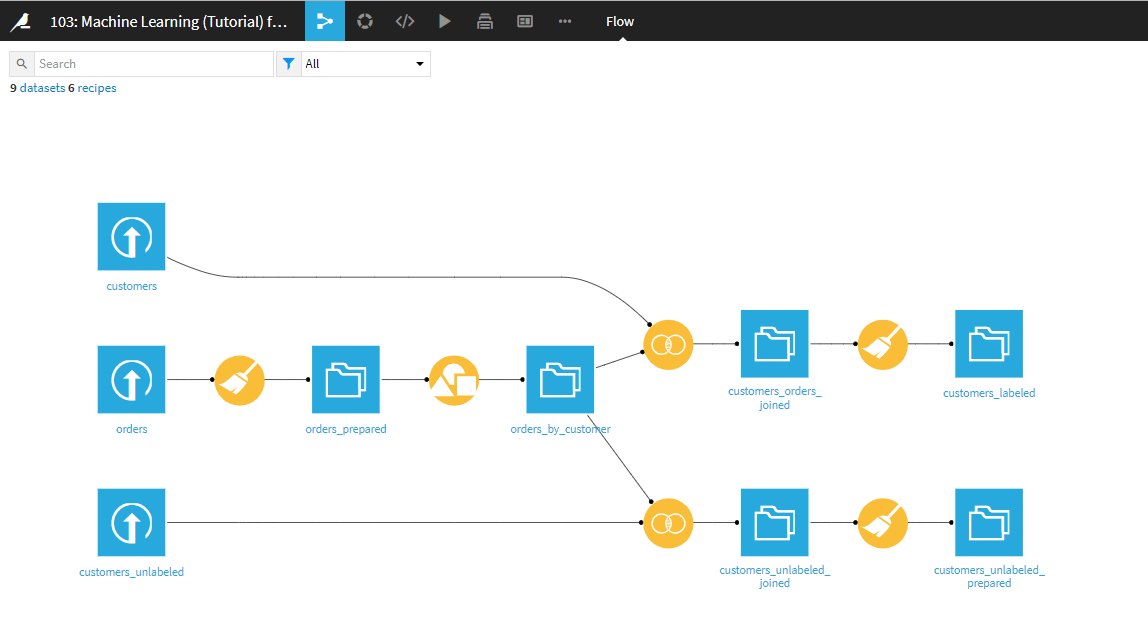
最初に、前回のモデル画面のフローへ。
まず、customers_labeledデータセットをクリックしてLABボタンをクリックしてください。
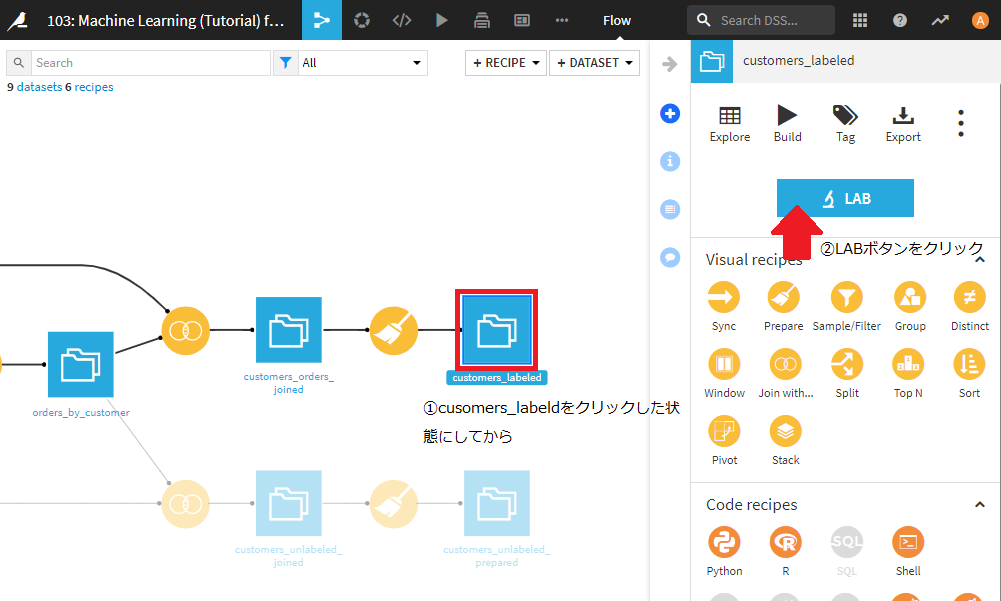
Visual analysisの下に、High revenue analysisという名前で先ほど作成したモデルがありますのでこちらをクリック。
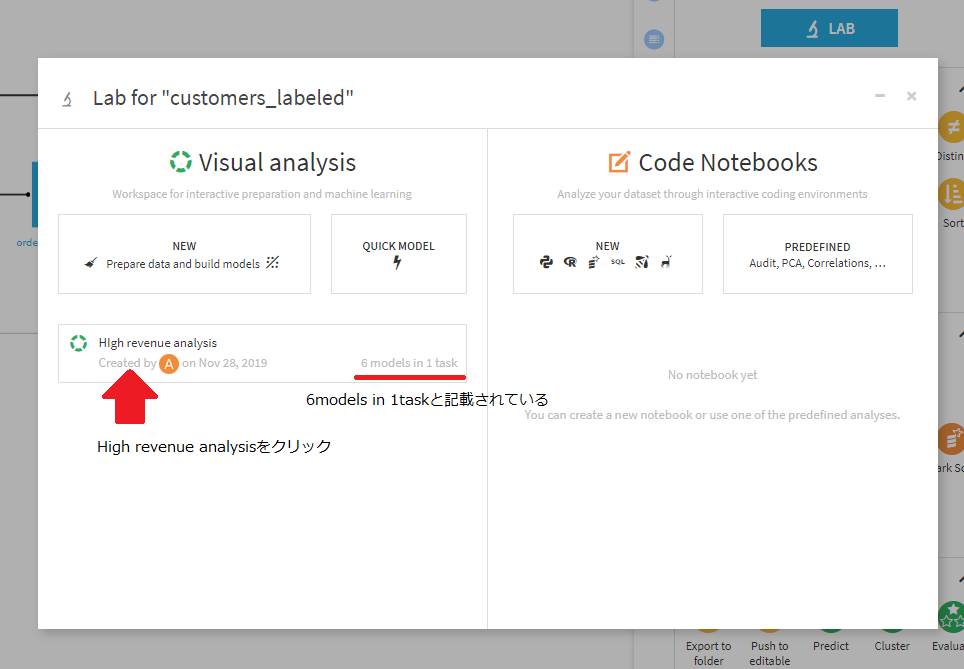
さらにModelタブをクリック。
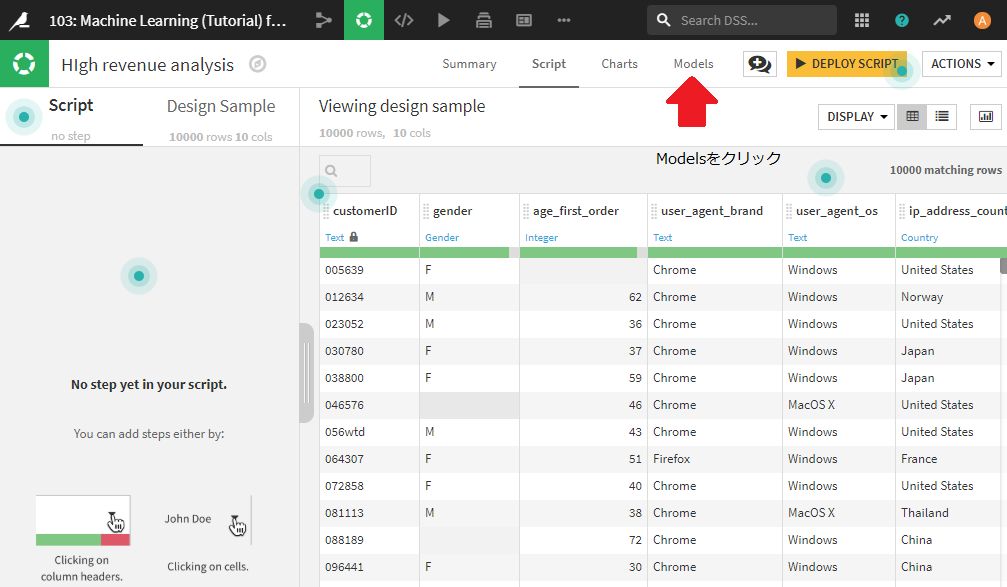
前回いろいろ試したモデル画面に到達できていると思います。
ちなみに、一番良い結果が、Random Forestとなっているはずです。このモデルを使って、新規顧客に対しての予測を行っていきます。
Random Forestの結果をクリックして、モデルのSummary画面に移ります。
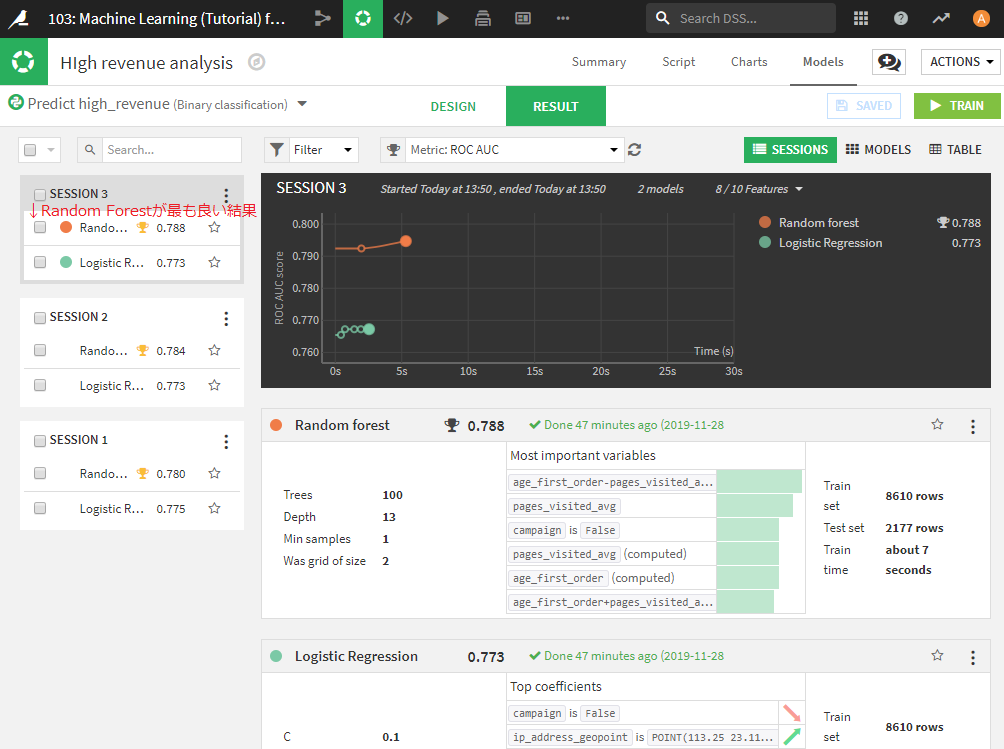
 メモ モデル名や詳細は編集可能
メモ モデル名や詳細は編集可能
モデル名やモデルの詳細を編集することが可能であるため、最も良いモデルの名前やdescriptionを編集しておき、あとからわかるようにしておくことができます。
編集のためには、モデルのSummary画面のモデル名横の薄いペンマークをクリック。
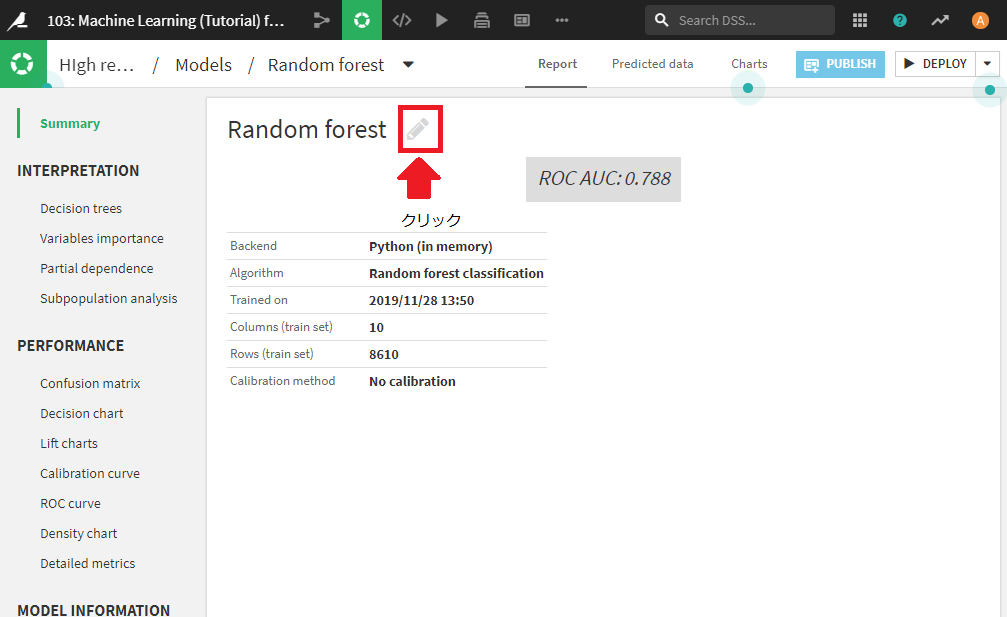
すると、編集画面に移ります。モデル名やモデルの詳細(description)を好きに変更し、SAVEボタンで変更反映できます。
モデルのデプロイ
モデルをデプロイすることにより、フローに組み込んで予測に使えるようになります。
まず、モデルのSummary画面右上、DEPLOYボタンをクリックします。
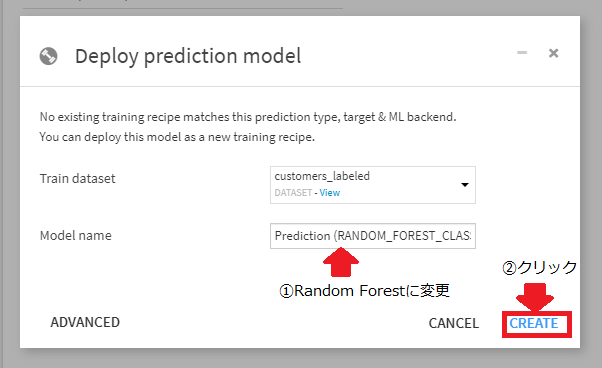
ポップアップが出てきます。ここでCREATEボタンを押すことにより、フローに新しいTrainレシピを追加することができます。
Model nameはこのままでも問題ありませんが、わかりやすくRandom Forestに変更します。たくさんモデルをデプロイして試す場合は、別の名前にした方が良いかもしれません。今回は、これしかデプロイしませんので安直なネーミングです。
Model name変更後にCREATEボタンをクリックしてください。CREATEボタンクリックにより、自動的にフロー画面に遷移します。
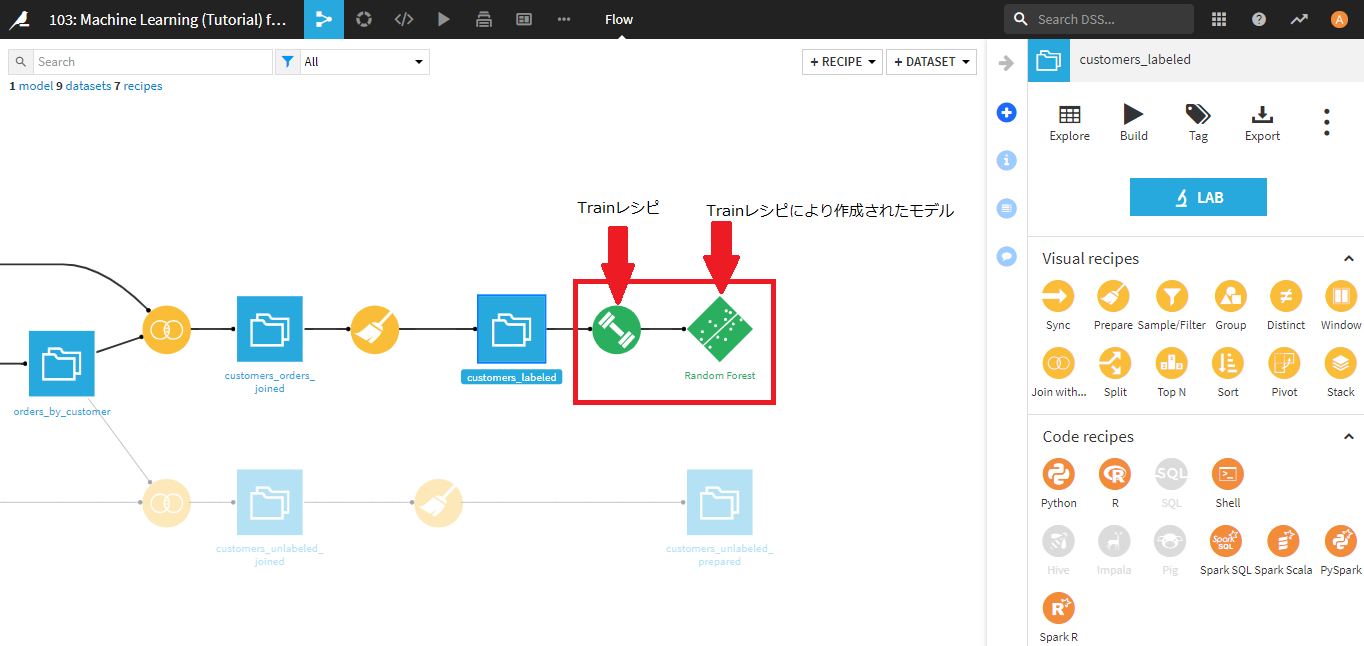
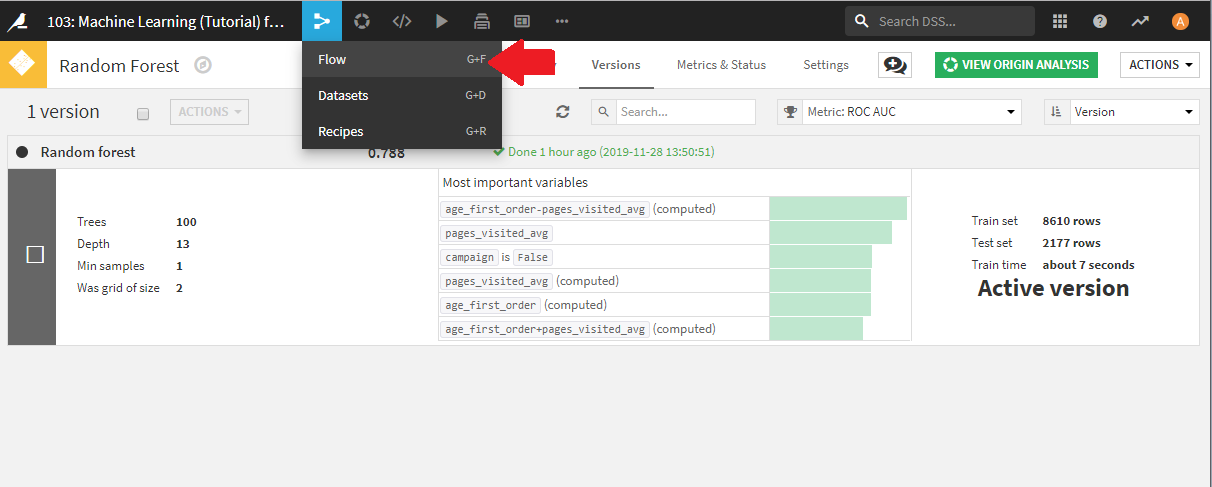
フロー画面では、右端に二つの緑の四角が追加されています。
左側が今回デプロイしたTrainレシピで、右側がTrainレシピにより作成されたモデルになります。
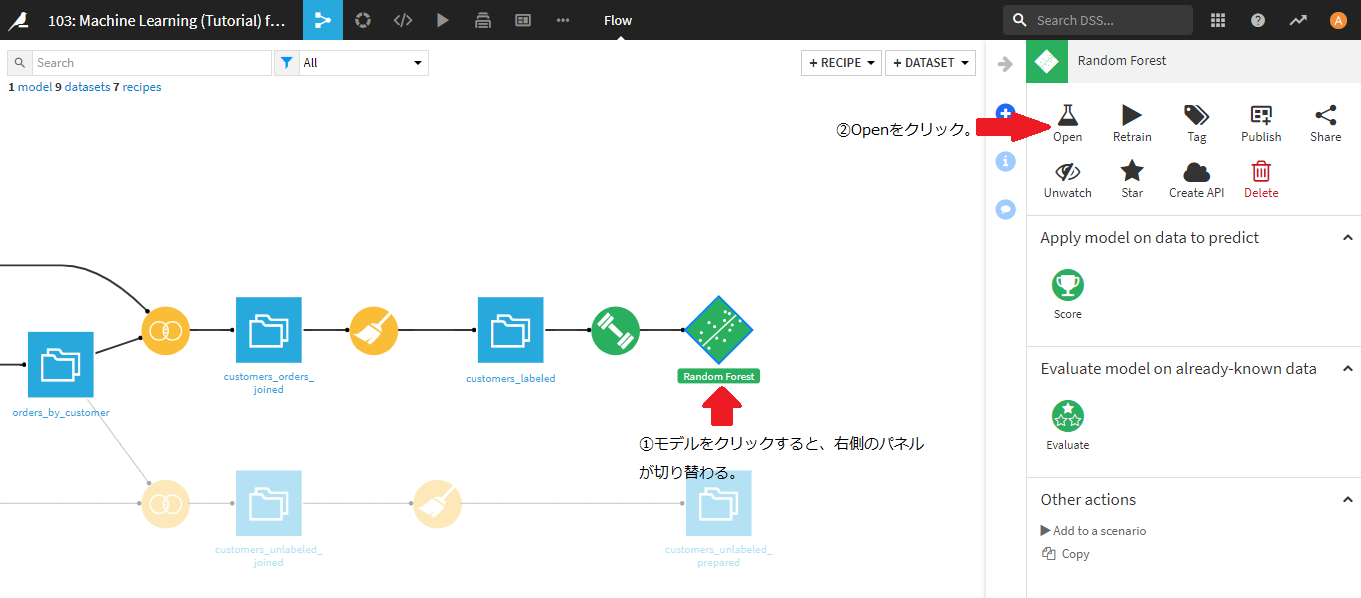
右側の緑四角、Random Forestモデルをクリックすると、右側のパネルが、Random Forest用のレシピに切り替わります。Random Forestモデルをクリックして選択した状態で、Openアイコンをクリックしてください。
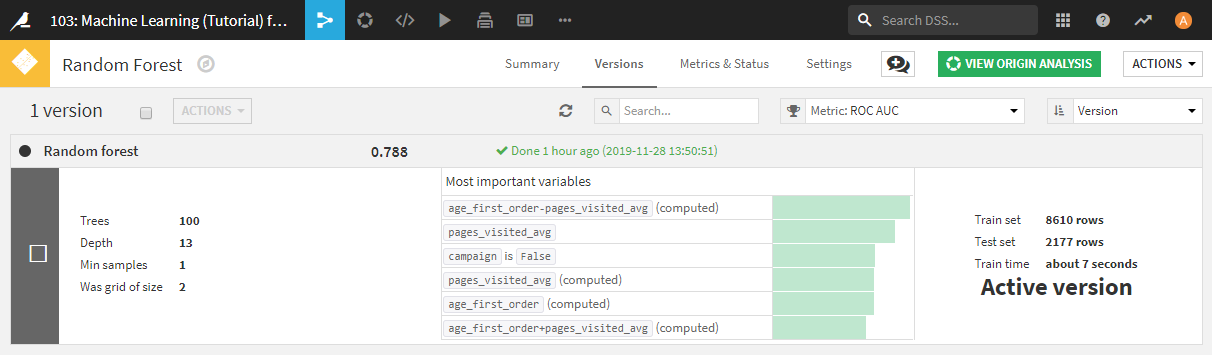
さきほどデプロイしたRandom Forestの精度が記載されたページが表示されます。ここでは詳細は述べませんが、このページからモデルの精度改善(Retrain)を行うことができます。作成したモデルのバージョン管理のようなことも可能です。
次はいよいよ、予測スコアの計算です。
Flowをクリックし、フロー画面に戻りましょう。
予測スコアの計算
ここまででモデル側の準備が終わりました。
最後にデプロイしたモデルを使って、新規顧客データに対しての予測スコア算出を行っていきます。
先ほどと同様に、Random Forest(緑の四角)をクリックした状態で、右側パネルのScoreアイコンをクリックします。
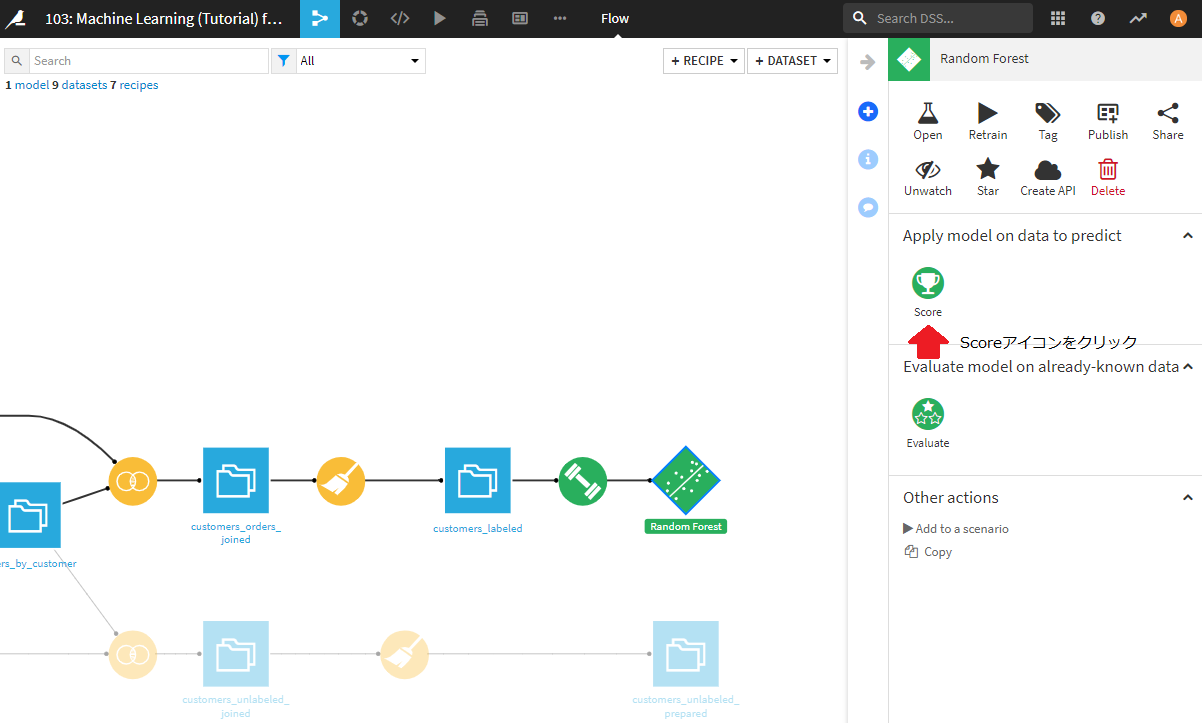
Score a datasetというポップアップウィンドウが開かれますので、以下のように設定してください。
- 左側のInput datasetに予測対象のデータセット(customers_unlabeled_prepared)を設定。これを設定すると、右側のOutput datasetが設定できるようになります。
- Prediction Modelに用いたいモデル(Random Forest)を設定。これはすでにRandom Forestが設定済みだと思います。
- output datasetの名前をNameに設定。任意のデータセット名(ただし、既出のデータセットとかぶらないもの)を記入します。ここでは、customers_unlabeled_scoredとしました。
- 結果の保存先をStore intoで選択。既に選択済みの、filesystem managedを用います。
- 結果の出力フォーマットをFormatで選択。すでに選択済みのCSVを用います。
上記設定後、CREATE RECIPEボタンをクリックします。
以下の画面でScoring recipeの設定を行います。
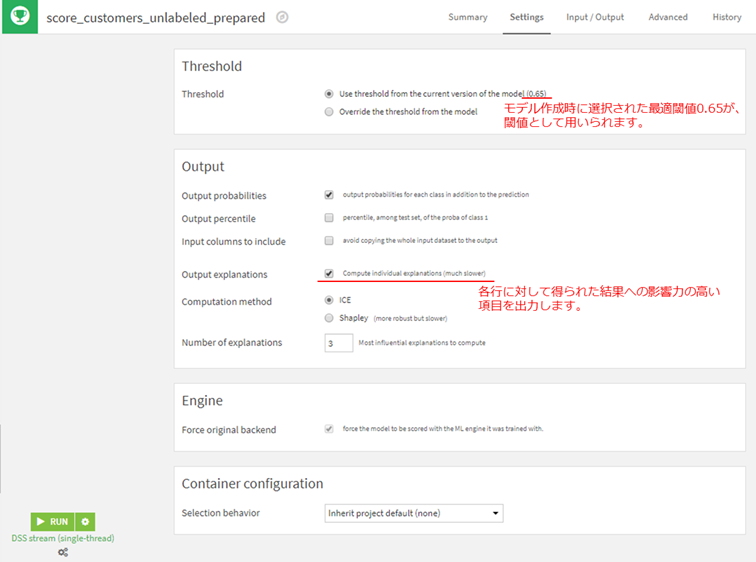
Thresholdは、Random Forestで得られた確率がいくつ以上なら高収益顧客であるとみなすかという閾値の設定になります。今回は、モデル作成時に得られた最適な閾値である0.625を用います。
また、Output explanationsを設定することで、なぜその結果が得られたのかの判断の根拠が出力されます。
この設定をチェックすると強制的に作成時と同じ学習エンジンを用いて予測スコア計算を行います。
Output explanationsを設定すると追加で以下の設定項目が表示されます。
- Computation method
"ICE"を選択してください。 - Number of explanations
3としてください。これは各行に対して結果への寄与が高い項目をいくつ表示するかという設定になります。
最後にRUNボタンを押すことで、予測スコア計算が行われます。
数秒後に画面下側に、Job Succeededと出れば成功です。

予測結果の確認
フロー画面に戻ってみましょう。
新しく、customer_unlabeled_scoredが追加されています。
クリックすることにより、予測結果を確認することができます。
表示されたデータの一番右の3列に予測結果が記載されています。
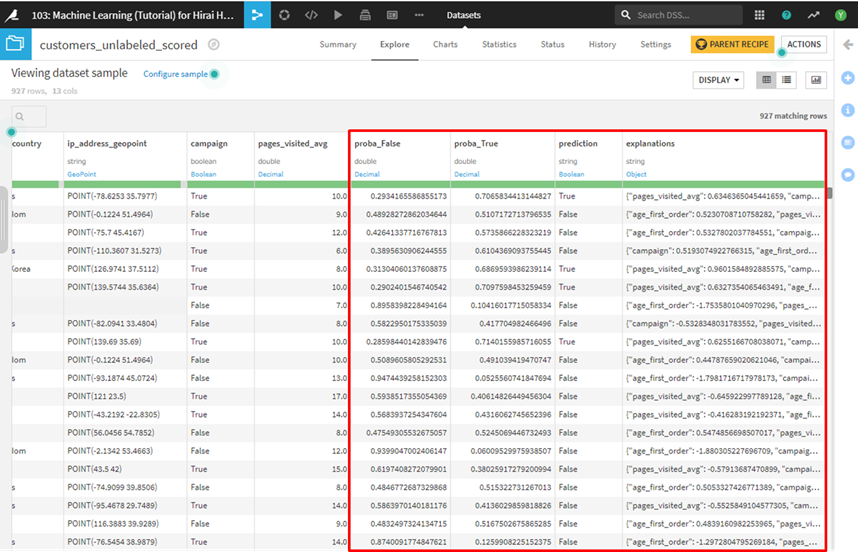
右の4列はそれぞれ以下の情報が記載されています。
- proba_False : 高収益顧客でない確率
- proba_True : 高収益顧客である確率
- prediction : 予測結果
- explanations: 予測結果への寄与が高い項目と寄与度(Scoring recipeで設定)
今回のモデルでは、予測対象の各顧客に対して、高収益顧客であるかどうかを0~1の確率で算出します。これが、proba_Trueに記載されます。この値が高いほど、高収益顧客である可能性が高いと解釈することができます。
一方、proba_Falseはproba_Trueとは逆で、この値が高いほど高収益顧客である可能性が低いと解釈することができます。
これらの値は確率ですので、proba_Falseとproba_Trueを合計すると1になります(多少の計算誤差は含む)。
predictionは、高収益顧客であるかどうかの予測結果です。予測対象の各顧客に対して、True(高収益顧客である)か、False(高収益顧客でない)かが記載されます。モデル作成時に設定された閾値を元に、TrueかFalseかのラベルがつきます。今回は、モデル作成時の閾値が0.625でしたので、0.625を超えればTrue(高収益顧客)となります。
explanationsの列には、項目名をキー、影響度を値とするJSONオブジェクトが含まれています。たとえば、次の図で強調表示されている行には、この行の結果に最も影響力のある3つの項目(age_first_order、campaign、およびpages_visited_avg)と、予測結果への寄与を示しています。

ちなみに、このJSON表記が扱いにくいは、Prepare recipeのUnnest objectを用いて各キーを各列に展開することが可能です。
cutomers_unlabeled_scoredデータセットに対してPrepare recipeを適用し、Unnest objectでexplanationsを指定してください。

おわりに
今回は、Dataiku DSS上で作成したモデルをどのように新規データに適用するかについて紹介しました。全5回でお送りした、Dataiku DSSの基本的なチュートリアルは、一通り終了となります。