アドベントカレンダー20日目です。
最近、Wordnetなどの階層構造データを扱うことがあるので、poincare embeddingにちょっと興味が湧いて試してみました。
poincare embeddingは、双曲空間を凸方向に射影したものなので、木構造データの表現に適したembeddingというのが私の中の雑な理解です。
詳細は他サイトに譲ります。
環境
ubuntu 20.04.5 LTS
python 3.9.6
使用データ
サイトなかほどのXLSXファイルをダウンロードし、作業者1シートをtsv形式にしたものを用いました。
前準備
gensim、ploylyともに古いバージョンでないと可視化のところでうまくいきません。
gensimインストール
pip install gensim==3.7.3
可視化用ライブラリインストール
pip install plotly==2.7.0
モデル作成
さっくりできます。
from gensim.models.poincare import PoincareModel, PoincareRelations
from gensim.test.utils import datapath
relations = PoincareRelations(file_path=datapath('/emotion1.tsv'))
model = PoincareModel(train_data=relations, size=2)
model.train(epochs=50)
可視化
ある意味ここが一番のはまりポイント。google colabとかだと、他にも呪文がいるとか。
import gensim.viz.poincare
import ployly.offline
plotly.offline.init_notebook_mode(connected=False)
prefecutre_map = gensim.viz.poincare.poincare_2d_visualization(model=model,
tree=relations,
figure_title="可視化",
num_nodes=10,
show_node_labels=model.kv.vocab.keys())
plotly.offline.iplot(prefecutre_map)
結果
丸いですね。期待通り。ごちゃっとしていますが、実際の画面ではカーソルおいたところの文字が紫枠で浮かんでくれます。
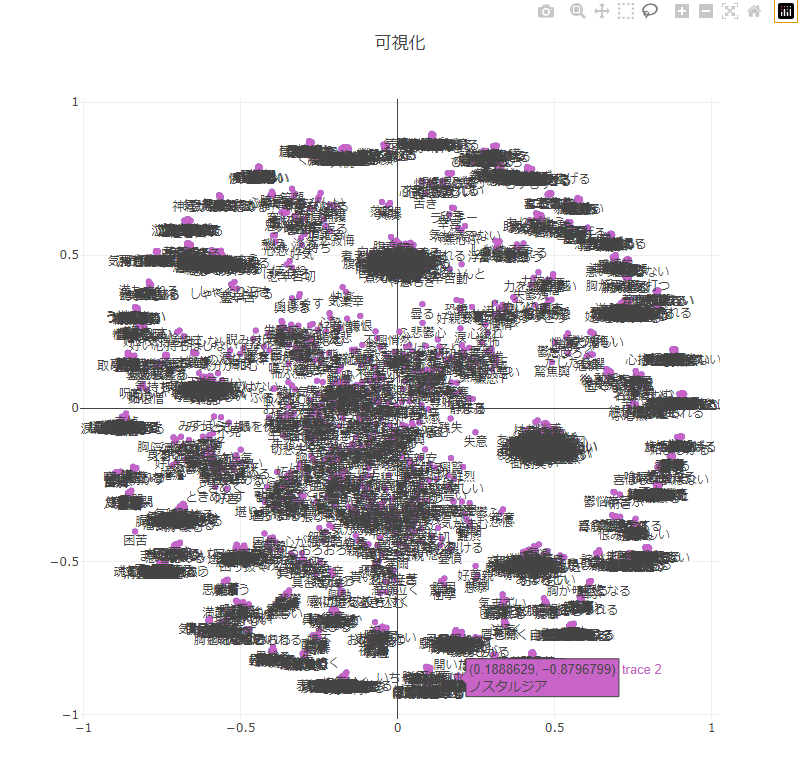
いくつか機能を紹介します。
類似度の高い言葉を引っ張ってくることができます。
"嬉しい"と近いもの2個を引っ張ってきます。
model.kv.most_similar("嬉しい",topn=2)
出力:[('良かった', 0.010566568678917252), ('歓心', 0.011028224138605661)]
"悲しい"と近いもの2個を引っ張ってきます。
model.kv.most_similar("悲しい",topn=2)
出力:[('悲哀', 0.023677410109664343), ('悲嘆', 0.02400493515592728)]
階層を反映させた形で、近いものを引っ張てくることもできます。
"嬉しい"の下位階層の最も近いもの
model.kv.closest_child("嬉しい")
出力:'嬉しがる'
"嬉しい"の上位階層の最も近いもの
model.kv.closest_parent("嬉しい")
出力:'良かった'
結果の妥当性としては、ちょっとよくわからないですね。使ったデータにもよる気がします。表記ゆれ対応とかにも使えるかもしれません。
gensimでの実装自体は結構古いですが、最近はDeepLearningでこのpoincare embeddingを実装した話が新しくでてきているようなので、またブームが来るのかもしれません。
参考
https://qiita.com/wwacky/items/3c33fa0add05c601f555
https://radimrehurek.com/gensim/models/poincare.html