コンポーネント単位 vs 集中型 i18n
コンポーネント単位のアプローチは新しい概念ではありません。例えば、Vue エコシステムでは、vue-i18n が SFC i18n(Single File Component) をサポートしています。Nuxt も コンポーネント単位の翻訳 を提供しており、Angular は Feature Modules を通じて同様のパターンを採用しています。
Flutter アプリでも、しばしば次のようなパターンが見られます:
lib/
└── features/
└── login/
├── login_screen.dart
└── login_screen.i18n.dart # <- 翻訳はここに格納されます
import 'package:i18n_extension/i18n_extension.dart';
extension Localization on String {
static var _t = Translations.byText("en") +
{
"Hello": {
"en": "Hello",
"fr": "Bonjour",
},
};
String get i18n => localize(this, _t);
}
しかし、Reactの世界では、主に異なるアプローチが見られ、ここではそれらを3つのカテゴリに分類します:
集中型アプローチ (i18next, next-intl, react-intl, lingui)
-
(namespaces を使わない場合) はコンテンツを取得する単一のソースを想定します。デフォルトでは、アプリ起動時にすべてのページのコンテンツを読み込みます。
細粒度アプローチ (intlayer, inlang)
-
キー単位、またはコンポーネント単位でコンテンツ取得を細分化する。
このブログでは、すでに解説したためコンパイラベースのソリューションには焦点を当てません: コンパイラ vs 宣言型 i18n.
コンパイラベースの i18n(例: Lingui)は、コンテンツの抽出と読み込みを自動化するだけであることに注意してください。内部的には、しばしば他のアプローチと同じ制約を共有します。
コンテンツ取得をより細かくすればするほど、コンポーネントに追加の状態やロジックを挿入してしまうリスクが高まることに注意してください。
グラニュラーなアプローチは集中型より柔軟ですが、多くの場合トレードオフになります。ライブラリが "tree shaking" を謳っていても、実際にはページごとにすべての言語を読み込むことが多いでしょう。
大まかに言うと、判断は次のように分かれます:
- アプリケーションのページ数が言語数より多い場合は、グラニュラーなアプローチを優先すべきです。
- 言語数がページ数より多い場合は、集中型アプローチを選ぶべきです。
もちろん、ライブラリの作者はこれらの制約を認識しており、回避策を提供しています。
その中には:ネームスペースに分割すること、JSONファイルを動的に読み込むこと(await import())、あるいはビルド時にコンテンツをパージすることなどがあります。
同時に、コンテンツを動的に読み込むとサーバーへの追加リクエストが発生することを知っておくべきです。追加の useState や他のフックごとに、追加のサーバーリクエストが必要になります。
この点を解決するために、Intlayer は複数のコンテンツ定義を同じキーの下にグループ化することを提案します。Intlayer はその後、それらのコンテンツをマージします。
しかし、これらの解決策を見ても、最も一般的に採用されているのは集中型のアプローチであることは明らかです。
では、なぜ集中型アプローチはこれほど人気があるのか?
- まず、i18next は広く使われるようになった最初のソリューションで、PHP や Java のアーキテクチャ(MVC)に触発された哲学に従っており、関心の厳格な分離(コンテンツをコードから切り離す)を前提としています。i18next は 2011 年に登場し、コンポーネントベースのアーキテクチャ(例: React)への大きな移行が起こる前にその基準を確立しました。
- 次に、一度ライブラリが広く採用されると、エコシステムを他のパターンに移行させるのは難しくなります。
- 中央集権的なアプローチは、Crowdin、Phrase、Localized のような翻訳管理システムでも扱いやすくなります。
- コンポーネント単位のアプローチのロジックは中央集権的なものよりも複雑で、特にコンテンツがどこにあるかを特定するといった問題を解決する必要がある場合、開発に余分な時間がかかります。
では、なぜ中央集約型アプローチに固執しないのか?
問題になり得る理由を説明します:
-
未使用データ:
ページが読み込まれると、しばしば他のすべてのページのコンテンツも読み込まれます。(10ページのアプリなら、読み込まれるコンテンツの90%が未使用です。)モーダルを遅延読み込みしても?i18nライブラリは気にせず、いずれにせよ文字列を先に読み込みます。 -
パフォーマンス:
再レンダリングごとに、すべてのコンポーネントが巨大なJSONペイロードでハイドレートされ、アプリが成長するにつれてリアクティビティに悪影響を与えます。 -
保守性:
大きなJSONファイルの保守は辛いです。翻訳を追加するためにファイル間を行き来し、翻訳漏れがないことや**孤立したキー(orphan keys)**が残っていないことを確認する必要があります。 -
デザインシステム:
それはデザインシステム(例:LoginFormコンポーネント)との非互換性を生み、異なるアプリ間でのコンポーネントの重複利用を制約します。
"でも私たちは Namespaces を発明した!"
確かに、それは大きな前進です。Vite + React + React Router v7 + Intlayer のセットアップにおけるメインバンドルサイズの比較を見てみましょう。20ページのアプリケーションをシミュレートしました。
最初の例はロケールごとの遅延読み込み(lazy-loaded)翻訳や namespace 分割を含んでいません。2番目の例はコンテンツのパージ(不要な翻訳の削除)と翻訳の動的ロードを含みます。
| 最適化されたバンドル | 最適化されていないバンドル |
|---|---|
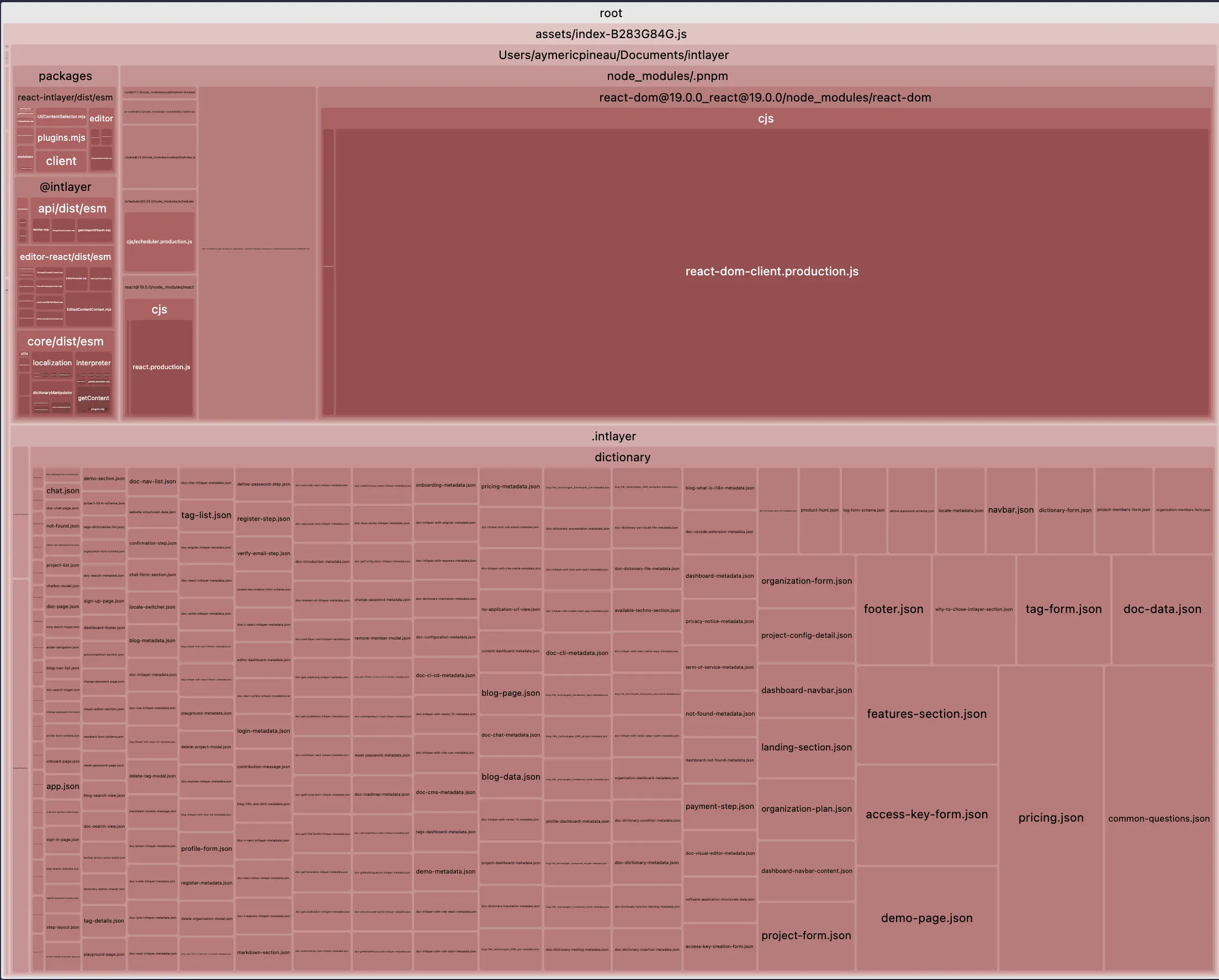 |
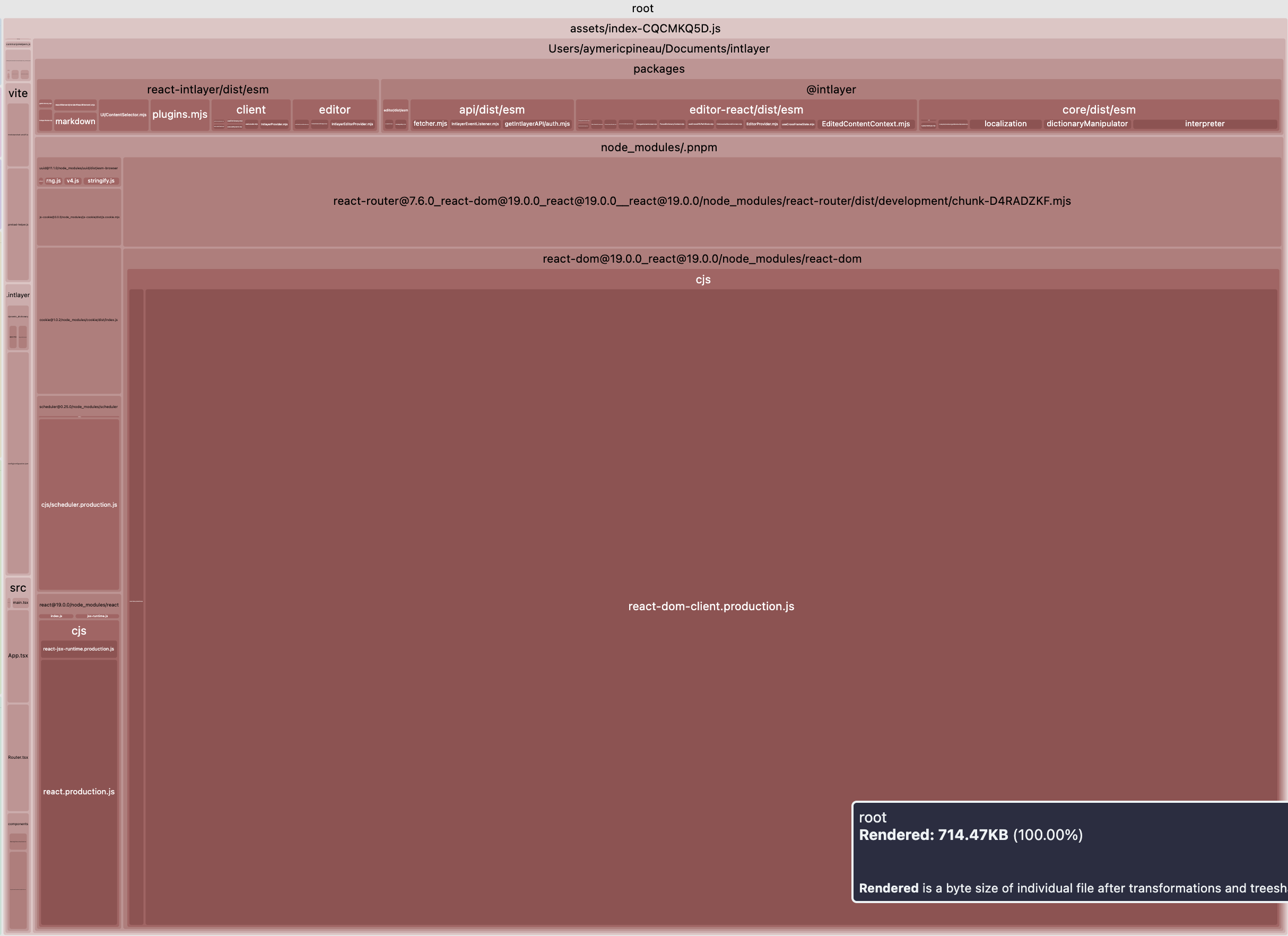 |
名前空間のおかげで、次のような構成から移行しました:
locale/
├── en.json
├── fr.json
└── es.json
To this one:
locale/
├── en/
│ ├── common.json
│ ├── navbar.json
│ ├── footer.json
│ ├── home.json
│ └── about.json
├── fr/
│ └── ...
└── es/
└── ...
ここでは、アプリのどのコンテンツをどこで読み込むかを細かく管理する必要があります。結論として、その複雑さのために大多数のプロジェクトはこの部分を省略してしまいます(例えば、良いプラクティスに従うだけでも直面する課題を確認するには next-i18next ガイド を参照してください)。その結果、これらのプロジェクトは前述した大量の JSON 読み込み問題に陥ります。
この問題は i18next 固有のものではなく、上で挙げたすべての集中型アプローチに共通する問題であることに注意してください。
ただし、すべての粒度を細かくしたアプローチ(granular approaches)がこの問題を解決するわけではないことを覚えておいてください。例えば、vue-i18n SFC や inlang のアプローチはロケールごとに翻訳を遅延読み込み(lazy load)する仕組みを本質的には持たないため、バンドルサイズの問題を別の問題に置き換えているに過ぎません。
さらに、関心の分離(separation of concerns)が適切に行われていないと、翻訳を抽出して翻訳者にレビュー用として渡すことがはるかに難しくなります。
Intlayerのコンポーネント単位アプローチがこれをどのように解決するか
Intlayerは以下の手順で進めます:
-
宣言(Declaration):
*.content.{ts|jsx|cjs|json|json5|...}ファイルを使用して、コードベースの任意の場所にコンテンツを宣言します。これにより、コンテンツをコロケート(colocated)したまま関心の分離を確保できます。コンテンツファイルはロケールごとのものでも多言語対応でも構いません。 - 処理: Intlayer はビルドステップを実行して、JS ロジックの処理、欠落した翻訳のフォールバック対応、TypeScript 型の生成、重複コンテンツの管理、CMS からのコンテンツ取得などを行います。
- パージ: アプリをビルドすると、Intlayer は未使用のコンテンツをパージ(Tailwind がクラスを管理する方法に少し似ています)し、コンテンツを次のように置き換えます:
宣言:
// src/MyComponent.tsx
export const MyComponent = () => {
const content = useIntlayer("my-key");
return <h1>{content.title}</h1>;
};
// src/myComponent.content.ts
export const {
key: "my-key",
content: t({
ja: { title: "私のタイトル" },
en: { title: "My title" },
fr: { title: "Mon titre" }
})
}
処理: Intlayer は .content ファイルに基づいて辞書を構築し、次を生成します:
// ファイル: .intlayer/dynamic_dictionary/en/my-key.json
{
"key": "my-key",
"content": { "title": "My title" },
}
置換: Intlayerはアプリケーションのビルド中にコンポーネントを変換します。
- 静的インポートモード:
// JSXライクな構文でのコンポーネント表現
export const MyComponent = () => {
const content = useDictionary({
key: "my-key",
content: {
nodeType: "translation",
translation: {
en: { title: "My title" },
fr: { title: "Mon titre" },
},
},
});
return <h1>{content.title}</h1>;
};
- 動的インポートモード:
// JSXライクな構文でのコンポーネント表現
export const MyComponent = () => {
const content = useDictionaryAsync({
en: () =>
import(".intlayer/dynamic_dictionary/en/my-key.json", {
with: { type: "json" },
}).then((mod) => mod.default),
// 他の言語も同様
});
return <h1>{content.title}</h1>;
};
useDictionaryAsyncは、必要なときにのみローカライズされた JSON を読み込む Suspense のような仕組みを使用します。
このコンポーネント単位のアプローチの主な利点:
-
コンテンツ宣言をコンポーネントに近くに置くことで、保守性が向上します(例:コンポーネントを別のアプリやデザインシステムに移動する場合など)。コンポーネントのフォルダを削除すれば関連するコンテンツも削除されます — これはおそらく
.testや.storiesに対して既に行っているのと同じです。 -
コンポーネントごとのアプローチにより、AIエージェントがすべての異なるファイルをまたいで参照する必要がなくなります。翻訳を一箇所で扱うため、タスクの複雑さと使用するトークン量を抑えられます。
制限事項
もちろん、このアプローチにはトレードオフがあります:
- 他の l10n システムや追加ツールとの接続が難しくなります。
- ロックインされやすくなります(これは特定の構文を持つ任意の i18n ソリューションで基本的に既に起こっていることです)。
そのため Intlayer は、独自の AI プロバイダーと API キーを使った AI 翻訳を含む、i18n のための包括的なツールセット(100% 無料かつ OSS)を提供しようとしています。Intlayer はまた、JSON を同期するためのツールチェーンを提供しており、ICU / vue-i18n / i18next のメッセージフォーマッターのように機能して、コンテンツを各フォーマットにマッピングします。
あなたの正直なフィードバックをぜひ聞かせてください。反対意見や懸念点こそが、より良いプロダクトを作るための助けになります。これは「オーバーキル(やりすぎ)」でしょうか? それとも、次世代のTailwind(デファクトスタンダード)になり得るでしょうか?