こんにちは ayalan です。
以前セミナーでデータ分析基盤の話を聞いたとき、規模が大きすぎてよくわからなかったことがありました。
CPUよりGPUがいいとか、IoTのデータをリアルタイムでアップロードするとか実際そんなことなかなかできないし、知らないと雰囲気つかめない人がほとんどだと思います。
しかし、もっと規模小さなデータでも分析使いたい、分析したいという人も多いかと思います。
今回やってみたのは、解析元のデータをETLツールでGoogleのBigQueryにデータを集約する仕組みをDockerを使って実装してみました。
動作環境
ホスト
| 項目 | バージョン |
|---|---|
| os | OS X El Capitan 10.11.6 |
| dokcer | 17.09.0-ce |
| docker-compose | 1.16.1 |
| ruby | 2.3.5 |
dockerが動作すればどのような環境でも問題ありません。ただ、dokcerとdocker-composeは古いバージョンだと動作しない可能性もあるので、なるべく最新バージョンの方がいいかと思います。
コンテナ
ETL+ジョブスケジューラー(ETL:Embulk,ジョブスケジューラー:kuroko2)
| 項目 | バージョン |
|---|---|
| base image | alpine:3.6 |
| openjdk | 1.8.0_131 |
| ruby | 2.3.5p376 |
| jruby | jruby 9.1.14.0 (2.3.3) |
| bundler | 1.16.0 |
| rails | 5.1.4 |
| puma | 5.1.4 |
| kuroko2 | 0.4.3 |
| Embulk | v0.8.38 |
ETLはEmblukを使っており、ジョブスケジューラはクックパッドのkuroko2を使っています。
Database
| 項目 | バージョン |
|---|---|
| base image | mariadb:latest |
| mariadb | 15.1 Distrib 10.2.11 |
リアルタイムモニタリング(netdata)
| 項目 | バージョン |
|---|---|
| base image | titpetric/netdata:latest |
| netdata | 1.8.0-624-gf14f228_rolling |
ETL+ジョブスケジューラーコンテナの作成
kuroko2の初期設定
クックパッドのkuroko2を使うためAdministrator Guideを参考に初期設定をします。
Dockerfile内でrails newするとイメージサイズが肥大化するので、イメージ外でrails newしたものをdockerのイメージの中に組み込みます。
rails new my_kuroko2 --database=mysql --skip-turbolinks --skip-javascript -m https://raw.githubusercontent.com/cookpad/kuroko2/master/app_template.rb
Dockerイメージ作成
本来は1プロセス1コンテナが理想ですが、ETLツールのEmbulkはコマンドツールであり、ジョブスケジューラーのKuroko2でRails Sever(puma)とジョブ実行するプロセスと複数稼働させないといけなかったので、1コンテナに複数機能を持たせることにしました。
FROM ayaran/openjdk:8u131
MAINTAINER oyamayu@firstserver.co.jp
RUN echo "http://dl-cdn.alpinelinux.org/alpine/edge/community" >> /etc/apk/repositories
RUN echo "http://dl-cdn.alpinelinux.org/alpine/v3.5/main" >> /etc/apk/repositories
RUN echo "http://dl-cdn.alpinelinux.org/alpine/v3.5/community" >> /etc/apk/repositories
RUN apk update && apk add --no-cache \
openrc \
curl \
cmake \
mysql-dev \
mysql-client \
build-base \
libxml2-dev \
libxslt-dev \
linux-headers \
libffi-dev \
openssl \
nodejs \
jruby \
tzdata
RUN apk add --no-cache \
ruby=2.3.6-r0 \
ruby-dev=2.3.6-r0 \
ruby-bigdecimal=2.3.6-r0 \
ruby-rdoc=2.3.6-r0 \
ruby-io-console=2.3.6-r0 \
ruby-irb=2.3.6-r0
RUN gem install --no-doc bundler
RUN curl -L "https://dl.embulk.org/embulk-latest.jar" -o /usr/local/bin/embulk
RUN chmod +x /usr/local/bin/embulk
COPY ./Gemfile /opt/embulk/Gemfile
RUN gem install --no-doc bundler --install-dir /opt/embluk/bundle/ruby/2.3.0/gems
RUN embulk bundle install --gemfile /opt/embulk/Gemfile --path /opt/embulk/bundle
ADD ./my_kuroko2 /opt/kuroko2
WORKDIR /opt/kuroko2
RUN bundle install --gemfile /opt/kuroko2/Gemfile --path /opt/kuroko2/bundle
COPY ./config/database.yml /opt/kuroko2/config/database.yml
COPY ./config/application.rb /opt/kuroko2/config/application.rb
RUN mkdir -p /opt/kuroko2/tmp/pids
COPY ./scripts/db-migrate /etc/init.d/db-migrate
COPY ./scripts/puma /etc/init.d/puma
COPY ./scripts/command-executor /etc/init.d/command-executor
COPY ./scripts/job-scheduler /etc/init.d/job-scheduler
COPY ./scripts/workflow-processor /etc/init.d/workflow-processor
RUN rc-update add db-migrate default
RUN rc-update add puma default
RUN rc-update add command-executor default
RUN rc-update add job-scheduler default
RUN rc-update add workflow-processor default
RUN rc-status && touch /run/openrc/softlevel
RUN sed -i -- 's/^tty/#tty/g' /etc/inittab
各プロセスをデーモン化して起動したかったのでOpenRCの起動スクリプトを作って設置しています。
特に、アプリケーションコンテナを起動する際にDatabaseの初期起動が完了していることが前提なので、docker docsを参考にDatabaseの初回起動完了を確認してからdb:migrateが動くスクリプト作成しています。
# !/sbin/openrc-run
prog=db-migrate
RAILS_ROOT=/opt/kuroko2
host=database
user=kuroko
password=kuroko
cmd="/usr/bin/bundle exec rails db:migrate"
start() {
echo -n $"Starting $prog: "
until mysql -h"$host" -u"$user" -p"$password" -e "show databases;"; do
echo -n "MySQL is unavailable - sleeping"
sleep 1
done
>&2 echo "MySQL is up - executing command"
cd $RAILS_ROOT
$cmd
RETVAL=$?
echo
eend $?
}
作ったコンテナたちの起動
docker-composeで起動させるため、下記docker-compose.ymlを準備。
version: '3.2'
services:
database:
hostname: mariadb
container_name: mariadb
image: mariadb
expose:
- 3306
environment:
- MYSQL_RANDOM_ROOT_PASSWORD=yes
- MYSQL_DATABASE=kuroko2_development
- MYSQL_USER=kuroko
- MYSQL_PASSWORD=kuroko
restart: always
kuroko2:
hostname: kuroko2
container_name: kuroko2
image: ayaran/kuroko2
expose:
- 80
ports:
- 80:80
links:
- database:database
depends_on:
- "database"
volumes:
- ./.env:/opt/kuroko2/.env
- /sys/fs/cgroup:/sys/fs/cgroup:ro
command: /sbin/init
restart: always
netdata:
hostname: netdata
container_name: netdata
image: titpetric/netdata
expose:
- 19999
ports:
- 19999:19999
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /var/run/docker.sock:/var/run/docker.sock
environment:
- "TZ=Japan"
tty: true
restart: always
Databaseを永続化する場合はホスト側のvolumeをマウントしておくとよい。
database:
hostname: mariadb
container_name: mariadb
image: mariadb
expose:
- 3306
environment:
- MYSQL_RANDOM_ROOT_PASSWORD=yes
- MYSQL_DATABASE=kuroko2_development
- MYSQL_USER=kuroko
- MYSQL_PASSWORD=kuroko
volumes:
- /path/to/mysql:/var/lib/mysql
restart: always
起動させる
docker-compose -f docker-compose.yml up -d
これで起動する。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
185609c9aba9 ayaran/kuroko2 "/sbin/init" 6 seconds ago Up 4 seconds 0.0.0.0:80->80/tcp kuroko2
5103d6d4b17f mariadb "docker-entrypoint..." 3 hours ago Up 26 minutes 3306/tcp mariadb
4fc893ed9d35 titpetric/netdata "/run.sh" 3 hours ago Up 26 minutes 0.0.0.0:19999->19999/tcp netdata
http://localhost/にアクセスするとGoogleAuthの画面が出てきて、
認証を行うとkuroko2の画面が現れます。
ここからBigQueryへデータ転送するJOBを登録して実行していきます。
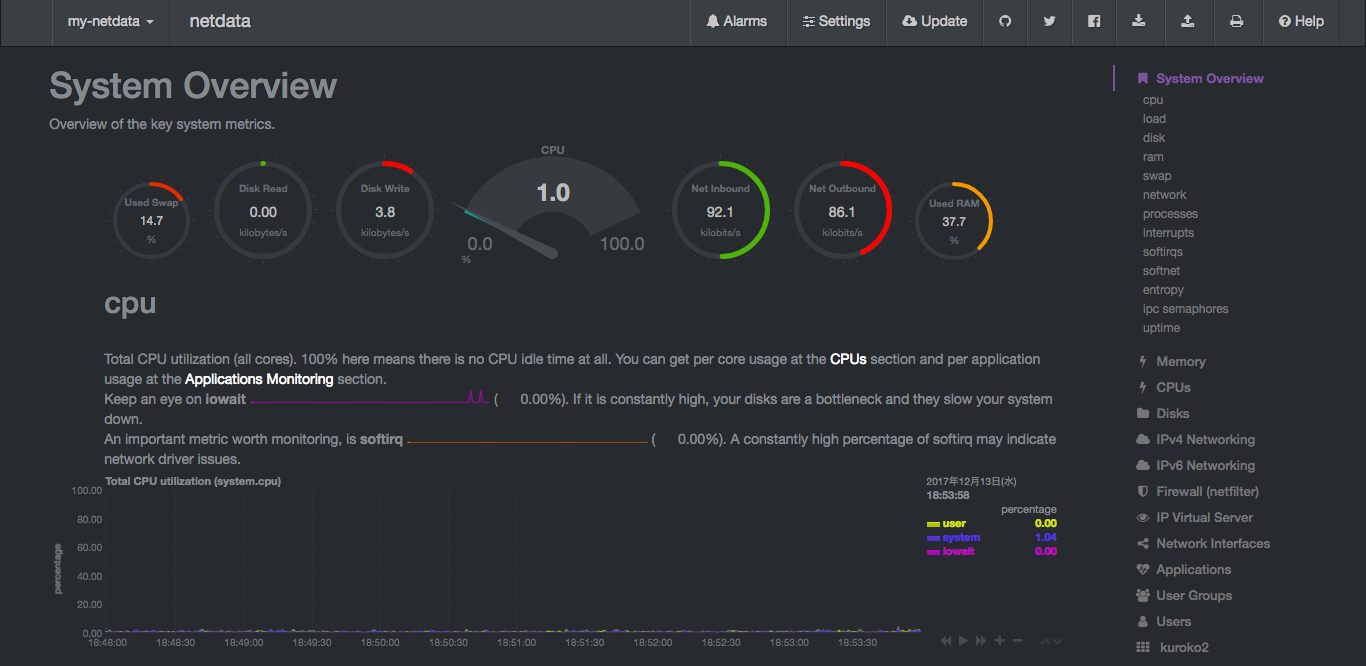
また、http://localhost:19999にアクセスするとリソースモニタリングの画面も見れるようになっています。
まとめ
実際データを転送するところまでかけませんでしたが、思った以上に簡単に仕組みを作ることはできました。
(コンテナのイメージさえあればちょっとしたconfigだけ用意ればコマンド一つ叩くだけで動くわけなので。)