PythonでEDINETの財務データを取りたい。検索すると、requestsでZIPをダウンロードしてzipfileで展開してlxmlでXBRLをパースする記事が出てくる。2023年の記事で50行。動く。
ただし1社分。
3,709社×15年分×3つの会計基準に対応しようとすると、50行が500行になり、2週間が溶ける。自分もそこを通った。この記事では、最初にその「つらい方」を見せてから、3行で同じ結果を得る方法を紹介する。
EDINETから直接取る方法(つらい方)
まずは正攻法。EDINET APIでトヨタの有報ZIPを取得して、XBRLから売上高を抜く。
import requests
import zipfile
import io
from lxml import etree
# Step 1: EDINET APIで書類一覧を取得
res = requests.get("https://api.edinet-fsa.go.jp/api/v2/documents.json", params={
"date": "2025-06-25",
"type": 2,
"Subscription-Key": "YOUR_EDINET_KEY",
})
docs = res.json()["results"]
# Step 2: トヨタ(E02144)の有報を探す
toyota_doc = next(d for d in docs if d["edinetCode"] == "E02144" and d["docTypeCode"] == "120")
# Step 3: ZIPダウンロード
zip_res = requests.get(
f"https://api.edinet-fsa.go.jp/api/v2/documents/{toyota_doc['docID']}",
params={"type": 1, "Subscription-Key": "YOUR_EDINET_KEY"},
)
# Step 4: ZIPからXBRLファイルを探す
with zipfile.ZipFile(io.BytesIO(zip_res.content)) as zf:
xbrl_files = [f for f in zf.namelist() if f.endswith(".xbrl") and "AuditDoc" not in f]
xbrl_content = zf.read(xbrl_files[0])
# Step 5: XBRLパース — ここからが地獄
tree = etree.fromstring(xbrl_content)
nsmap = {
"jppfs": "http://disclosure.edinet-fsa.go.jp/taxonomy/jppfs/2023-12-01/jppfs_cor",
"ifrs": "http://xbrl.ifrs.org/taxonomy/2023-03-23/ifrs-full",
}
# トヨタはIFRS。JP-GAAPなら別のnamespace。US-GAAPならさらに別。
revenue = tree.find(".//ifrs:Revenue", nsmap)
if revenue is None:
revenue = tree.find(".//jppfs:NetSales", nsmap) # JP-GAAPフォールバック
print(f"売上高: ¥{int(revenue.text):,}")
35行。動く(はず)。問題点:
-
会計基準の分岐: トヨタはIFRSだから
ifrs:Revenue。任天堂はJP-GAAPだからjppfs:NetSales。ソフトバンクGはIFRSだがRevenueじゃなくOperatingRevenue。全部ハードコーディング。 -
名前空間のバージョン: タクソノミは毎年更新される。
2023-12-01がいつ2024-12-01に変わるか。 -
単位: 円で出す会社、千円で出す会社、百万円で出す会社。XBRLの
unitRefとdecimals属性を見ないと金額が100万倍ずれる。 -
期間の判定:
contextRefで当期・前期を判別する必要がある。間違えると前年のデータを取ってくる。
1社ならなんとかなる。3,709社にスケールさせるのは別の話。
3行で同じ結果を得る方法
AxioraというAPIがある。EDINETの有報XBRLをパース・正規化して、REST APIで返してくれる。
pip install axiora
from axiora import Axiora
client = Axiora() # 環境変数 AXIORA_API_KEY から読み取り
toyota = client.companies.retrieve_financials("7203", years=1)
print(f"売上高: ¥{toyota.data[0].revenue:,}")
# 売上高: ¥48,036,704,000,000
3行。ZIP展開もXBRLパースもnamespace分岐もない。証券コード7203(東証のティッカーそのまま)を渡すだけ。
SDKはStainlessで生成されていて(OpenAI、AnthropicのSDKと同じツール)、型付きPydanticモデルが返る。toyota.data[0].revenueがIDEで補完される。
無料プラン。クレカ不要。1日10,000リクエスト。
会計基準の違いが消える
EDINETの最大の罠は、日本の上場企業が3つの会計基準を使っていること。
- トヨタ → IFRS(XBRLタグ:
ifrs-full:Revenue) - キーエンス → JP-GAAP(XBRLタグ:
jppfs_cor:NetSales) - 任天堂 → JP-GAAP(XBRLタグ:
jppfs_cor:NetSales)
自前パーサーだと3パターンの分岐が必要。APIだと:
from axiora import Axiora
client = Axiora()
# IFRS企業
toyota = client.companies.retrieve_financials("7203", years=1)
print(f"トヨタ(IFRS): 売上高 ¥{toyota.data[0].revenue:,}")
print(f" 会計基準: {toyota.data[0].accounting_standard}")
# JP-GAAP企業
keyence = client.companies.retrieve_financials("6861", years=1)
print(f"キーエンス(JP-GAAP): 売上高 ¥{keyence.data[0].revenue:,}")
print(f" 会計基準: {keyence.data[0].accounting_standard}")
nintendo = client.companies.retrieve_financials("7974", years=1)
print(f"任天堂(JP-GAAP): 売上高 ¥{nintendo.data[0].revenue:,}")
print(f" 会計基準: {nintendo.data[0].accounting_standard}")
トヨタ(IFRS): 売上高 ¥48,036,704,000,000
会計基準: IFRS
キーエンス(JP-GAAP): 売上高 ¥1,059,145,000,000
会計基準: JP-GAAP
任天堂(JP-GAAP): 売上高 ¥1,164,922,000,000
会計基準: JP-GAAP
同じ.revenueフィールド。会計基準が違っても同じ変数名。裏側で52フィールド×3会計基準のXBRLタグマッピングが動いているが、使う側はif文を書かなくていい。
accounting_standardフィールドで、どの基準で報告されたかは確認できる。
トヨタの5年分を取得
financials = client.companies.retrieve_financials("7203", years=5)
for f in financials.data:
rev = f.revenue / 1_000_000_000_000
ni = f.net_income / 1_000_000_000_000
print(f" {f.fiscal_year} 売上: ¥{rev:.1f}兆 純利益: ¥{ni:.2f}兆 ROE: {f.roe:.1f}%")
2025 売上: ¥48.0兆 純利益: ¥4.79兆 ROE: 13.0%
2024 売上: ¥45.1兆 純利益: ¥5.07兆 ROE: 14.4%
2023 売上: ¥37.2兆 純利益: ¥2.49兆 ROE: 8.5%
2022 売上: ¥31.4兆 純利益: ¥2.87兆 ROE: 10.6%
2021 売上: ¥27.2兆 純利益: ¥2.28兆 ROE: 9.4%
ROEまで計算済みで返ってくる。営業利益率、純利益率、自己資本比率なども同じ。52フィールド。
売上高ランキング:Top 10
pandasで表にする:
import pandas as pd
from axiora import Axiora
client = Axiora()
ranking = client.rankings.retrieve("revenue", limit=10)
rows = []
for r in ranking.data:
rows.append({
"順位": r.rank,
"企業名": r.name_jp,
"証券コード": r.securities_code,
"セクター": r.sector,
"売上高(兆円)": round(r.revenue / 1e12, 1),
})
df = pd.DataFrame(rows)
print(df.to_string(index=False))
順位 企業名 証券コード セクター 売上高(兆円)
1 トヨタ自動車株式会社 7203 輸送用機器 48.0
2 本田技研工業株式会社 7267 輸送用機器 21.7
3 三菱商事株式会社 8058 卸売業 18.6
4 伊藤忠商事株式会社 8001 卸売業 14.7
5 三井物産株式会社 8031 卸売業 14.7
6 日本電信電話株式会社 9432 情報・通信業 13.7
7 三菱UFJフィナンシャル・グループ 8306 銀行業 13.6
8 ソニーグループ株式会社 6758 電気機器 13.0
9 日産自動車株式会社 7201 輸送用機器 12.6
10 ENEOSホールディングス株式会社 5020 石油・石炭製品 12.3
1回のAPIコール。11,245社のデータベースから最新の有報データでランキング。
スクリーニング:ROE15%以上の大企業
「ROEが15%以上で売上1,000億円以上」— クオンツが最初に回すフィルタ:
screen = client.screen.retrieve(
roe_min=15.0,
revenue_min=100_000_000_000,
sort="roe_desc",
limit=10,
)
for r in screen.data:
name = r.company.name_jp
print(f" {name[:20]:<20} ROE: {r.metrics.roe:.1f}% 売上: ¥{r.financials.revenue/1e9:,.0f}億")
フィルタ条件:roe_min, roe_max, revenue_min, revenue_max, net_income_min, roa_min, sectorなど。全部サーバー側で処理される。
チャート:10年の売上推移
pip install axiora matplotlib
from axiora import Axiora
import matplotlib.pyplot as plt
client = Axiora()
companies = {"7203": "トヨタ", "6758": "ソニー", "6861": "キーエンス"}
fig, ax = plt.subplots(figsize=(10, 6))
for code, label in companies.items():
financials = client.companies.retrieve_financials(code, years=10)
years = [f.fiscal_year for f in reversed(financials.data)]
rev = [f.revenue / 1e12 for f in reversed(financials.data)]
ax.plot(years, rev, marker="o", label=label, linewidth=2)
ax.set_ylabel("売上高(兆円)")
ax.set_title("トヨタ vs ソニー vs キーエンス — 10年売上推移")
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("japan_revenue.png", dpi=150)
print("japan_revenue.png に保存しました")
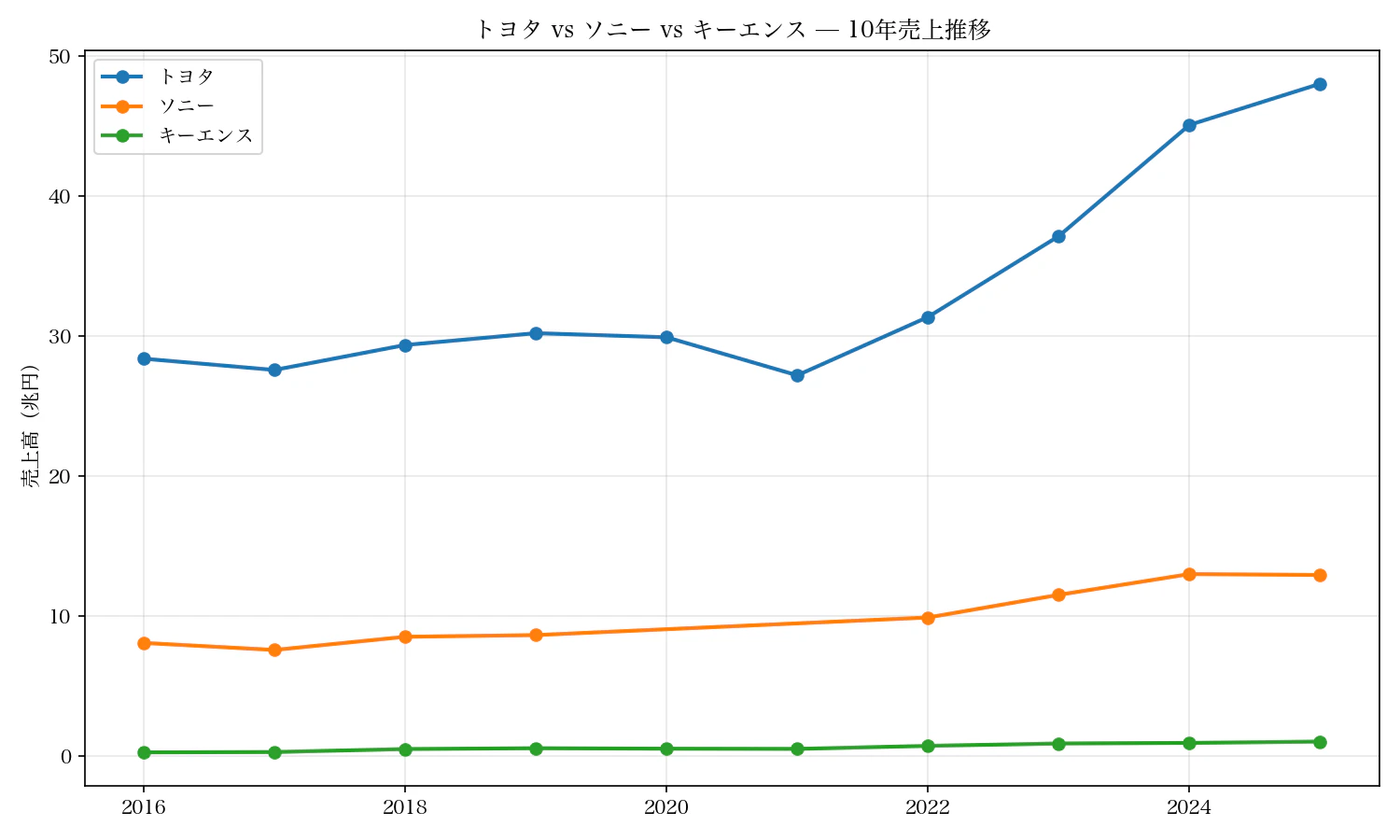
トヨタは圧倒的なスケール。でも傾きを見るとキーエンスが面白い。売上1兆円のセンサー企業が10年間ほぼ毎年2桁成長。しかも営業利益率51.9%。
非同期対応
複数社を並行で取りたい場合:
import asyncio
from axiora import AsyncAxiora
async def main():
async with AsyncAxiora() as client:
codes = ["7203", "6758", "6861", "9984", "6501"]
tasks = [client.companies.retrieve_financials(code, years=1) for code in codes]
results = await asyncio.gather(*tasks)
for result in results:
f = result.data[0]
print(f" {f.edinet_code} 売上: ¥{f.revenue/1e12:.1f}兆")
asyncio.run(main())
同じ型付きレスポンス。awaitするだけ。
コピペ用:完全スクリプト
ここまでの内容を1ファイルにまとめた。AXIORA_API_KEY環境変数をセットして実行するだけ。
#!/usr/bin/env python3
"""PythonでEDINET財務データを取得する — 完全スクリプト"""
import pandas as pd
from axiora import Axiora
client = Axiora() # 環境変数 AXIORA_API_KEY から読み取り
# === 1. トヨタの5年分 ===
print("=== トヨタ (7203) — 5年分 ===")
for f in client.companies.retrieve_financials("7203", years=5).data:
print(f" {f.fiscal_year} 売上: ¥{f.revenue/1e12:.1f}兆 純利益: ¥{f.net_income/1e12:.2f}兆 ROE: {f.roe:.1f}%")
# === 2. 会計基準の違いを確認 ===
print("\n=== 会計基準の正規化 ===")
for code, name in [("7203", "トヨタ"), ("6861", "キーエンス"), ("7974", "任天堂")]:
f = client.companies.retrieve_financials(code, years=1).data[0]
print(f" {name}({f.accounting_standard}): 売上 ¥{f.revenue/1e12:.2f}兆")
# === 3. 売上高ランキング Top 10 ===
print("\n=== 売上高ランキング Top 10 ===")
ranking = client.rankings.retrieve("revenue", limit=10)
rows = []
for r in ranking.data:
rows.append({
"順位": r.rank,
"企業名": r.name_jp,
"売上高(兆円)": round(r.revenue / 1e12, 1),
})
print(pd.DataFrame(rows).to_string(index=False))
# === 4. 高ROEスクリーニング ===
print("\n=== ROE > 15%、売上 > 1,000億円 ===")
for r in client.screen.retrieve(
roe_min=15, revenue_min=100_000_000_000, sort="roe_desc", limit=10
).data:
print(f" {r.company.name_jp[:20]:<20} ROE: {r.metrics.roe:.1f}%")
print("\n全データ: 監査済みEDINET有報、XBRLパース済み。")
print("無料プラン: https://axiora.dev")
pip install axiora pandas
export AXIORA_API_KEY="your-key"
python edinet_quickstart.py
まとめ
EDINETは日本の財務データの正式なソース。ただし生のXBRLは、1社取るだけなら50行、3,709社に対応するなら数千行のパーサーと2週間の工期が必要になる。
axiora SDKを使えば、3行で同じデータが取れる。会計基準(JP-GAAP/IFRS/US-GAAP)の違いは正規化済み。ランキング、スクリーニング、成長率、ROEなどの指標も計算済みで返ってくる。
無料プランで全11,245社・全エンドポイントにアクセスできる。クレジットカード不要。