はじめに
個人開発でバイクポータルサイト MotoHub を運営しています。
先日、サイトのSEO強化のために「駅別バイク駐車場ランディングページ」を実装しました。URL構造は以下の通りです。
/parking/station/tokyo ← 東京駅周辺のバイク駐車場まとめ
/parking/station/shinjuku ← 新宿駅周辺のバイク駐車場まとめ
/parking/station/okayama ← 岡山駅周辺のバイク駐車場まとめ
「東京駅 バイク 駐車場」のようなピンポイント検索クエリをカバーすることで、SEO流入を増やす狙いです。
データソースには国土交通省の「国土数値情報(鉄道駅データ)」(nlftp.mlit.go.jp)を使いました。全国約9,000駅の緯度経度データが無料・商用利用OKで入手できます。
しかし、このデータをそのまま取り込むと想像以上に落とし穴があり、3つの構造的な問題に遭遇しました。この記事では、実際に踏んだ罠と、それを解決するための設計を紹介します。
同じように国交省データを使ってサービスを作ろうとしている方の参考になれば幸いです。
環境と前提
- 言語・FW: Laravel 12 / PHP 8.3
- DB: MySQL
- データ源: 国土数値情報 N02(鉄道データ、2024年度版)
- 形式: GeoJSON(約3.2MB、10,235 Features)
データの構造を理解する
国土数値情報の駅データ(GeoJSON)は以下のような構造です。
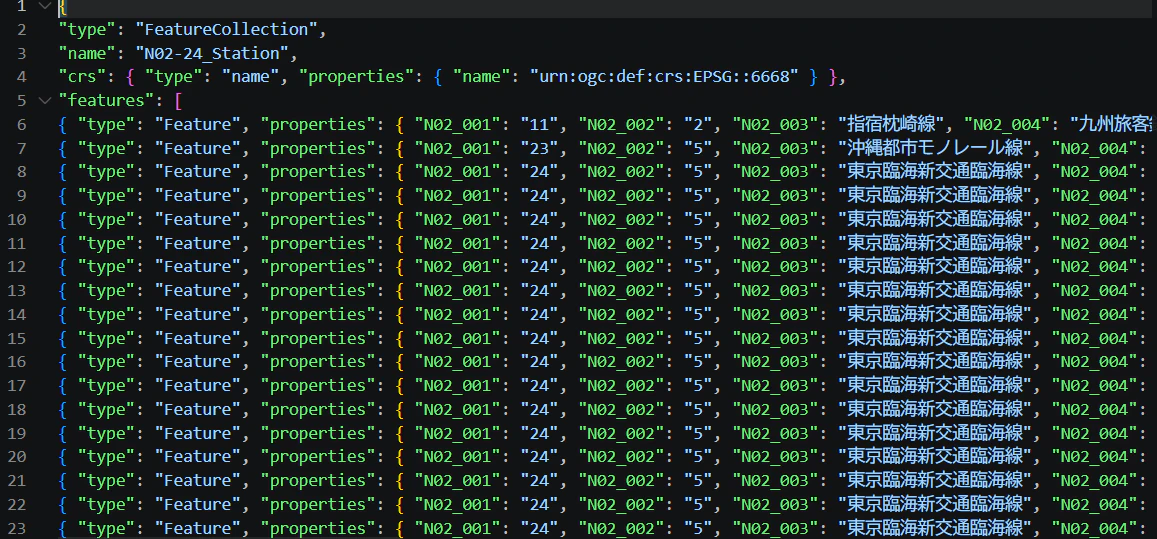
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"properties": {
"N02_001": "11", // 鉄道区分コード
"N02_002": "2", // 事業者種別コード
"N02_003": "指宿枕崎線", // 路線名
"N02_004": "九州旅客鉄道", // 運営会社名
"N02_005": "二月田", // 駅名
"N02_005c": "003580", // 駅コード
"N02_005g": "003580" // 駅グループコード
},
"geometry": {
"type": "LineString",
"coordinates": [
[130.6504, 31.2511],
[130.6506, 31.2513]
]
}
}
]
}
重要なポイントは以下の通りです。
-
N02_005が駅名(日本語) - 座標は
LineString(線路の区間)で、駅の中心ではない -
N02_005gが駅グループコード(同一駅の識別に使える) - 総件数は 10,235 Features(駅×路線の組み合わせ)
実際には同じ駅が複数の路線で重複しているため、集約すると約9,000駅になります。
落とし穴① 同名駅が大量に分散している
最初にハマったのは、同じ駅名が大量のFeatureに分散している問題です。
どういうこと?
たとえば「東京駅」は、以下のように10以上のFeatureに分かれています。
東京 / JR東海道本線 / 東日本旅客鉄道
東京 / JR中央線 / 東日本旅客鉄道
東京 / JR京浜東北線 / 東日本旅客鉄道
東京 / JR山手線 / 東日本旅客鉄道
東京 / JR京葉線 / 東日本旅客鉄道
東京 / JR横須賀線 / 東日本旅客鉄道
東京 / JR東海道新幹線 / 東海旅客鉄道
東京 / 東京メトロ丸ノ内線 / 東京地下鉄
...
これを愚直にインポートすると、stations テーブルに 東京駅のレコードが10個以上作られてしまいます。
N02_005g だけでは解決しない
最初、「N02_005g(駅グループコード)でグルーピングすればOK」と考えました。確かにある程度は集約できます。しかし、異なる事業者の駅は別のグループコードを持つので、完全には統合できません。
たとえば「東京駅」は、JRと東京メトロで別のグループコードを持っている可能性があります。
解決策:駅名 + 緯度経度の近接判定
結局、以下の2段階の集約処理を実装しました。
// Phase 1: N02_005g でグルーピング
$groupedByCode = $features->groupBy(fn($f) => $f['properties']['N02_005g']);
// Phase 2: 中間レコードを作成(緯度経度は LineString の中点)
$intermediateRecords = $groupedByCode->map(function ($features) {
$first = $features->first();
$coords = collect($features)->flatMap(fn($f) => $f['geometry']['coordinates']);
$avgLat = $coords->avg(fn($c) => $c[1]);
$avgLng = $coords->avg(fn($c) => $c[0]);
return [
'name' => $first['properties']['N02_005'],
'latitude' => $avgLat,
'longitude' => $avgLng,
'line_names' => $features->pluck('properties.N02_003')->unique()->values(),
'company_names' => $features->pluck('properties.N02_004')->unique()->values(),
];
});
// Phase 3: 同名駅かつ 500m以内を統合(クラスタリング)
$mergedRecords = $this->clusterByProximity($intermediateRecords, 500);
ポイントは Phase 3 のクラスタリングです。「同じ駅名」かつ「半径500m以内」のレコードを1つに統合します。これで東京駅のJR・地下鉄・新幹線がすべて1レコードにまとまります。
結果
- 10,235 Features → 9,032 stations(16駅が統合)
- 東京駅は10以上のレコード → 1レコードに統合され、路線名はカンマ区切りで保持
落とし穴② 同名駅が別の都道府県にもある
次に出くわしたのが、同じ駅名が別の都道府県にも存在する問題です。
「大宮駅」は1つじゃない
「大宮」と聞けば、多くの人が埼玉県さいたま市のJR大宮駅を思い浮かべるでしょう。しかし、国土数値情報には以下の駅も含まれています。
- 埼玉県の大宮駅(JR宇都宮線、京浜東北線、東北新幹線など)
- 京都府の大宮駅(京福電鉄・嵐山線の小駅)
主要駅としてslug=omiya を割り振る時、駅名だけで判定すると京都府の大宮駅にヒットする可能性があります。実際、最初の実装ではそうなっていました。
slug=omiya → 京都府の大宮駅(京福電鉄) ← ❌ 本命じゃない
slug=st-002914 → 埼玉県の大宮駅(JR) ← ✅ これが本命
「高松駅」に至っては3つある
もっと極端な例が「高松駅」です。
- 香川県の高松駅(JR予讃線、本命)
- 東京都荒川区の高松駅(都電荒川線の小駅)
- 石川県の高松駅(七尾線の小駅)
主要駅判定で name = '高松' でマッチングすると、どれがヒットするかわからないのです。
解決策:(name, prefecture) のペアで一意特定
この問題は、主要駅リストを「駅名+都道府県」のペアで定義することで解決しました。
// config/stations.php
return [
'major' => [
['name' => '東京', 'prefecture' => '東京都', 'slug' => 'tokyo'],
['name' => '新宿', 'prefecture' => '東京都', 'slug' => 'shinjuku'],
['name' => '大宮', 'prefecture' => '埼玉県', 'slug' => 'omiya'], // 埼玉県のみ
['name' => '高松', 'prefecture' => '香川県', 'slug' => 'takamatsu'], // 香川県のみ
['name' => '岡山', 'prefecture' => '岡山県', 'slug' => 'okayama'],
// ... 30駅
],
];
インポート処理では、この設定を使って厳密に主要駅を判定します。
$majorStationsConfig = config('stations.major');
foreach ($stations as $station) {
foreach ($majorStationsConfig as $major) {
if ($station['name'] === $major['name'] &&
$station['prefecture'] === $major['prefecture']) {
$station['is_major'] = true;
$station['slug'] = $major['slug'];
break;
}
}
}
これで「大宮(京都府)」や「高松(東京都)」が主要駅として誤判定されることはなくなります。
教訓:「駅名」だけではキーにならない
Web系エンジニアとしてはユニーク性の設計をもっと意識すべきでした。駅名は 「都道府県」と組み合わせて初めて一意になるケースが多いです。
落とし穴③ 本番データ量が想像の10倍だった
3つ目は実装ではなくインフラ面の問題でしたが、地味に効きました。
ローカルと本番の差
ローカル開発環境で動作確認した時、駐車場データは3,567件でした。駅と駐車場の紐付け処理(半径500m以内の駐車場を探して station_id を更新)は、数分で完了。何の問題もありません。
しかし本番デプロイ後、紐付けコマンドを実行すると…
駅数: 9032 / 半径: 0.5km
対象駐車場: 40569件
15095/40569 [▓▓▓▓▓▓▓▓▓▓░░░░░░░░░░░░░░░░░░] 37%
本番は40,569件! ローカルの約11倍のデータ量だったのです。
何が起きたか
- 開発中は小規模データで動作確認
- 本番は全国の駐車場データ(40,569件)が蓄積済み
- PHPのメモリ上限
256Mを超えて処理が落ちる - ネットワーク経由のssh接続で、PCスリープにより途中終了
解決策:メモリ上限を上げて、バックグラウンド実行
最終的に以下のコマンドで紐付けを完走させました。
nohup docker compose exec -T app \
php -d memory_limit=2048M \
artisan station:link-parkings \
> /tmp/link-parkings.log 2>&1 &
ポイントは3つ。
-
-d memory_limit=2048MでPHPのメモリを2GBに拡張 -
nohupで SSH切断されても処理継続 -
-Tで TTY を割り当てず、バックグラウンド実行を可能に
この構成で、40,569件の紐付けが最後まで完走しました。
教訓:本番データ量を事前に把握すること
ローカルと本番で10倍以上のデータ量差がある場合、メモリ・実行時間・タイムアウトなど、実装時に想定していなかった制約に引っかかります。
大量データのバッチ処理は、以下を最初から考慮すべきでした。
- メモリ上限の拡張
- バックグラウンド実行(nohup / screen / systemd timer など)
- 中断再開可能な設計(どこまで処理したかを記録)
- ログ出力と進捗可視化
まとめ:国交省データを使う時のチェックリスト
この経験を踏まえ、同じような実装をする時のチェックリストを作りました。
データ取り込み時
- 同名駅の統合ロジックを実装したか?(クラスタリング)
- 路線名・会社名は統合前にユニーク化してマージしたか?
- 緯度経度は LineString の中点を計算したか?
-
駅グループコード (
N02_005g) だけに頼らず、近接判定も併用したか?
主要駅判定
-
(name, prefecture)のペアで一意に指定したか? - 駅名だけでマッチングしていないか?
- 主要駅リストを config or Enum で設定駆動にしたか?
- 同名駅が複数存在する場合のフォールバックを考慮したか?
インフラ面
- 本番データ量を事前に把握したか?
- メモリ上限を本番相当に上げて検証したか?
- バックグラウンド実行の仕組みを準備したか?
- 中断時の再開可能性を考慮したか?
副次効果:SEO資産としての駅別LP
実装後、以下の波及効果がありました。
- SEOカバレッジ拡大: 「東京駅 バイク 駐車場」「新宿駅 バイク 駐車場」等のロングテールキーワードを捕捉
-
駅×車種の組み合わせ: 将来的に
/station/tokyo/bike/rebel-250のような掛け合わせLPも作れる - B2B営業の材料: 駐車場運営会社への営業時に「駅別アクセス解析」を提供可能
-
データ構造の整備:
stationsテーブルができたことで、駅を起点にしたサービス展開が容易に
おわりに
国土数値情報は無料・商用利用OKという素晴らしいデータソースですが、そのまま取り込むにはデータ構造の理解が不可欠です。
特に「同じ名前の駅が複数ある」という当たり前の事実をコードに落とし込む時は注意が必要です。駅名だけをキーにすると、意図しない駅が選ばれたり、重複が発生したりします。
同じような実装をする方は、ぜひこの記事のチェックリストを参考にしてください。
参考リンク
- 国土数値情報 鉄道データ
- MotoHub - バイクポータルサイト
- 駅別駐車場ページの例: 東京駅周辺のバイク駐車場
出典
本記事で紹介したサービスの駅情報は、国土交通省「国土数値情報(鉄道駅データ)」(https://nlftp.mlit.go.jp/)を加工して利用しています。