はじめに
「ジャンルなしオンラインもくもく会 Advent Calendar 2025」の6日目の記事です。
本記事は、Kubernetesクラスタ構築シリーズの第4回です。今回は、構築したクラスタに本番を意識した監視スタックをデプロイします。
本シリーズの全体構成
前回のおさらい
本記事で学べること
- kube-prometheus-stackのHelmインストール
- AlertManager → Discord Webhook連携
- 専用ノードへのデプロイ(NodeSelector + Toleration)
- Ingress経由での外部アクセス設定
1. kube-prometheus-stackとは
1.1 含まれるコンポーネント
公式Helmチャートに含まれるもの
| コンポーネント | 役割 |
|---|---|
| Prometheus Operator | CRDベースの自動化 |
| Prometheus | メトリクス収集・保存 |
| Grafana | 可視化ダッシュボード |
| AlertManager | アラート管理・通知 |
| Node Exporter | ノードメトリクス収集 |
| kube-state-metrics | Kubernetesオブジェクトのメトリクス |
一括デプロイで監視基盤が構築可能!
1.2 アーキテクチャ
監視専用ノードの利点
- アプリケーションとのリソース競合回避
- 安定した監視基盤
- Taint/Tolerationで確実に分離
2. 事前準備
2.1 Helmのインストール
# Mac
brew install helm
# バージョン確認
helm version
2.2 Discord Webhookの作成
- Discordサーバーの設定 → 連携サービス
- ウェブフック → 新しいウェブフック
- ウェブフックURLをコピー
2.3 監視専用ノードの確認
昨日(12/5)でラベル付けしたノードを確認
※ノード名は環境に合わせて読み替えてください
# ラベル確認
kubectl get node talos-worker-3 --show-labels | grep monitoring
# Taint確認
kubectl describe node talos-worker-3 | grep Taints
# Taints: dedicated=monitoring:NoSchedule
3. Helmでのインストール
3.1 Helm Repositoryの追加
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
3.2 values.yamlの作成
実際に使用した設定ファイル
# kubernetes/infrastructure/monitoring/values.yaml
# kube-prometheus-stack Helm values
# 監視専用ノード(talos-worker-3)への配置設定付き
commonLabels:
app.kubernetes.io/part-of: homelab-infra
# =============================================================================
# Prometheus
# =============================================================================
prometheus:
prometheusSpec:
# 監視専用ノードに配置
nodeSelector:
node-role.kubernetes.io/monitoring: "true"
tolerations:
- key: dedicated
operator: Equal
value: monitoring
effect: NoSchedule
# リソース制限(homelab向け)
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 1000m
memory: 2Gi
# データ保持期間
retention: 15d
retentionSize: "10GB"
# ストレージ設定(StorageClass がないため emptyDir を使用)
# Longhorn導入後にPVCに変更可能
storageSpec: {}
# 全Namespaceからメトリクス収集
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
# =============================================================================
# Alertmanager
# =============================================================================
alertmanager:
alertmanagerSpec:
nodeSelector:
node-role.kubernetes.io/monitoring: "true"
tolerations:
- key: dedicated
operator: Equal
value: monitoring
effect: NoSchedule
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 256Mi
# AlertManager設定
config:
global:
resolve_timeout: 5m
route:
receiver: discord
group_by: ['alertname', 'namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
# Critical は即座に通知
- match:
severity: critical
receiver: discord
group_wait: 10s
repeat_interval: 1h
# Warning は通常通知
- match:
severity: warning
receiver: discord
receivers:
- name: discord
webhook_configs:
- url: "YOUR_DISCORD_WEBHOOK_URL" # ← 実際のURLに置き換え
send_resolved: true
inhibit_rules:
- source_match:
severity: critical
target_match:
severity: warning
equal: ['alertname', 'namespace']
# =============================================================================
# Grafana
# =============================================================================
grafana:
nodeSelector:
node-role.kubernetes.io/monitoring: "true"
tolerations:
- key: dedicated
operator: Equal
value: monitoring
effect: NoSchedule
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
# 管理者パスワード(本番ではSecret化推奨)
adminPassword: "admin" # TODO: 変更してください
# Ingress設定
ingress:
enabled: true
ingressClassName: nginx
hosts:
- grafana.homelab.local
# サイドカー設定(ConfigMap からダッシュボード自動読み込み)
sidecar:
dashboards:
enabled: true
label: grafana_dashboard
searchNamespace: ALL
datasources:
enabled: true
label: grafana_datasource
# =============================================================================
# Node Exporter(全ノードで実行 - DaemonSet)
# =============================================================================
nodeExporter:
enabled: true
# =============================================================================
# kube-state-metrics
# =============================================================================
kubeStateMetrics:
enabled: true
# =============================================================================
# Prometheus Operator
# =============================================================================
prometheusOperator:
nodeSelector:
node-role.kubernetes.io/monitoring: "true"
tolerations:
- key: dedicated
operator: Equal
value: monitoring
effect: NoSchedule
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
# =============================================================================
# 追加のアラートルール
# =============================================================================
additionalPrometheusRulesMap:
homelab-rules:
groups:
- name: homelab-node-alerts
rules:
# ノードダウン検知
- alert: NodeDown
expr: up{job="node-exporter"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Node {{ $labels.instance }} is down"
description: "Node {{ $labels.instance }} has been down for more than 2 minutes."
# CPU使用率 > 85%
- alert: HighCpuUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
for: 10m
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
description: "CPU usage is above 85% (current: {{ $value }}%)"
# メモリ使用率 > 85%
- alert: HighMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage on {{ $labels.instance }}"
description: "Memory usage is above 85% (current: {{ $value }}%)"
# ディスク使用率 > 85%
- alert: HighDiskUsage
expr: (1 - (node_filesystem_avail_bytes{fstype!="tmpfs"} / node_filesystem_size_bytes{fstype!="tmpfs"})) * 100 > 85
for: 15m
labels:
severity: warning
annotations:
summary: "High disk usage on {{ $labels.instance }}"
description: "Disk usage is above 85% on {{ $labels.mountpoint }} (current: {{ $value }}%)"
- name: homelab-kubernetes-alerts
rules:
# Pod CrashLoopBackOff
- alert: PodCrashLoopBackOff
expr: increase(kube_pod_container_status_restarts_total[1h]) > 5
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} is in CrashLoopBackOff"
description: "Pod has restarted {{ $value }} times in the last hour"
# Pod Pending 状態が続く(10分以上)
- alert: PodPendingTooLong
expr: kube_pod_status_phase{phase="Pending"} == 1
for: 10m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} is Pending"
description: "Pod has been in Pending state for more than 10 minutes"
- name: homelab-lb-alerts
rules:
# MetalLB Speaker Pod停止(4台中2台以上停止でCritical)
- alert: MetalLBSpeakerDown
expr: count(up{job="metallb-speaker"} == 1) < 3
for: 2m
labels:
severity: critical
annotations:
summary: "MetalLB Speaker pods are down"
description: "Only {{ $value }} MetalLB Speaker pods running"
# Ingress Controller停止
- alert: IngressControllerDown
expr: kube_deployment_status_replicas_ready{deployment="ingress-nginx-controller"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Ingress Controller is down"
description: "No ready replicas for ingress-nginx-controller"
3.3 Namespaceの作成とPodSecurity設定
Node Exporterはホストネットワークを使用するため、privileged設定が必要
# Namespace作成
kubectl create namespace monitoring
# PodSecurityをprivilegedに設定(Node Exporter用)
kubectl label namespace monitoring pod-security.kubernetes.io/enforce=privileged --overwrite
3.4 Helmインストール
helm install kube-prometheus prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--values kubernetes/infrastructure/monitoring/values.yaml
3.5 デプロイ確認
kubectl get pods -n monitoring -o wide
出力例:
NAME READY STATUS NODE
alertmanager-kube-prometheus-kube-prome-alertmanager-0 2/2 Running talos-worker-3
kube-prometheus-grafana-xxx 3/3 Running talos-worker-3
kube-prometheus-kube-prome-operator-xxx 1/1 Running talos-worker-3
kube-prometheus-kube-state-metrics-xxx 1/1 Running talos-worker-2
kube-prometheus-prometheus-node-exporter-xxx 1/1 Running (各ノード)
prometheus-kube-prometheus-kube-prome-prometheus-0 2/2 Running talos-worker-3
ポイント: Prometheus, Grafana, AlertManager, Operatorが監視専用ノード(talos-worker-3)に配置されていることを確認。
4. Ingress経由での外部アクセス設定
4.1 Prometheus/AlertManager用Ingressの作成
Grafanaはvalues.yamlでIngressを有効化済み。PrometheusとAlertManager用に追加のIngressを作成。
# kubernetes/infrastructure/monitoring/ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus
namespace: monitoring
labels:
app.kubernetes.io/part-of: homelab-infra
spec:
ingressClassName: nginx
rules:
- host: prometheus.homelab.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kube-prometheus-kube-prome-prometheus
port:
number: 9090
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alertmanager
namespace: monitoring
labels:
app.kubernetes.io/part-of: homelab-infra
spec:
ingressClassName: nginx
rules:
- host: alertmanager.homelab.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kube-prometheus-kube-prome-alertmanager
port:
number: 9093
kubectl apply -f kubernetes/infrastructure/monitoring/ingress.yaml
4.2 hostsファイル設定
MBPの/etc/hostsに追加
echo "10.0.0.210 grafana.homelab.local prometheus.homelab.local alertmanager.homelab.local" | sudo tee -a /etc/hosts
注: 10.0.0.210 はMetalLBで割り当てられたIngress ControllerのExternal IP。
4.3 アクセス確認
# 動作確認(HTTPコード308が戻り値でした)
curl -s -o /dev/null -w "%{http_code}" -H "Host: grafana.homelab.local" http://10.0.0.210
curl -s -o /dev/null -w "%{http_code}" -H "Host: prometheus.homelab.local" http://10.0.0.210
curl -s -o /dev/null -w "%{http_code}" -H "Host: alertmanager.homelab.local" http://10.0.0.210
ブラウザでアクセス
- http://grafana.homelab.local (admin/admin)
- http://prometheus.homelab.local
- http://alertmanager.homelab.local
AlertManager画面
Prometheus画面
5. Grafanaダッシュボード
5.1 デフォルトで含まれるダッシュボード
kube-prometheus-stack には多数のダッシュボードがプリインストール
| ダッシュボード | 用途 |
|---|---|
| Kubernetes / Compute Resources / Cluster | クラスタ全体のリソース |
| Kubernetes / Compute Resources / Node | ノード別リソース |
| Node Exporter / Nodes | ノードの詳細メトリクス |
| Alertmanager / Overview | アラート状況 |
5.2 ダッシュボードへのアクセス
- http://grafana.homelab.local にアクセス
- admin / admin でログイン
- 左メニュー → Dashboards → Browse
- 任意のダッシュボードを選択
Grafanaダッシュボード画面
6. Discord通知のテスト
6.1 アラートの確認
Prometheusのアラート画面で設定したルールを確認:
open http://prometheus.homelab.local/alerts
6.2 テスト用の高負荷Podデプロイ
# high-cpu-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: high-cpu-test
namespace: default
spec:
containers:
- name: stress
image: polinux/stress
command: ["stress"]
args: ["--cpu", "2", "--timeout", "300s"]
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
kubectl apply -f high-cpu-pod.yaml
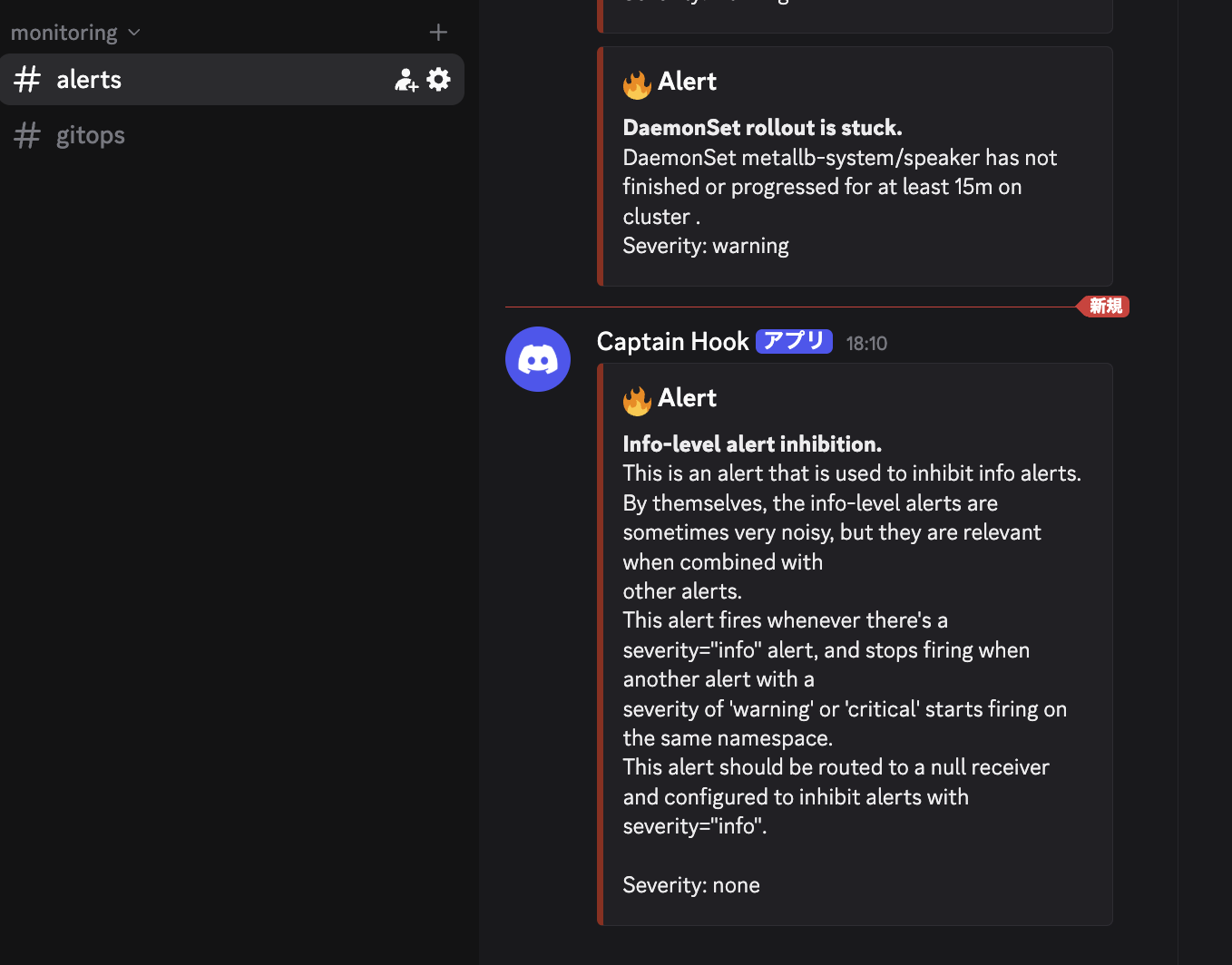
約5分後、Discordにアラート通知が届きます。
Discord通知の例
7. トラブルシューティング
7.1 Prometheusが起動しない
症状: Pod が Pending のまま
確認事項:
# イベント確認
kubectl describe pod -n monitoring prometheus-kube-prometheus-kube-prome-prometheus-0
# よくある原因
# 1. PVC が Pending → storageSpec: {} で emptyDir を使用
# 2. NodeSelector が合わない → ラベル確認
# 3. Toleration が不足 → Taint 確認
7.2 Node Exporterが起動しない
症状: PodSecurity違反エラー
kubectl get events -n monitoring | grep node-exporter
解決策
kubectl label namespace monitoring pod-security.kubernetes.io/enforce=privileged --overwrite
7.3 Discord通知が届かない
確認事項
# Webhook URL の確認
kubectl get secret -n monitoring alertmanager-kube-prometheus-kube-prome-alertmanager \
-o jsonpath='{.data.alertmanager\.yaml}' | base64 -d | grep url
# AlertManager ログ確認
kubectl logs -n monitoring alertmanager-kube-prometheus-kube-prome-alertmanager-0
# 手動テスト
curl -X POST \
-H "Content-Type: application/json" \
-d '{"content":"Test from AlertManager"}' \
YOUR_DISCORD_WEBHOOK_URL
8. まとめ
本記事では、Kubernetesクラスタに本番を意識した監視スタックを構築しました。
達成したこと
| 項目 | 状態 |
|---|---|
| kube-prometheus-stack デプロイ | ✅ |
| 監視専用ノードへの配置 | ✅ |
| Discord Webhook 連携 | ✅ |
| Ingress 経由の外部アクセス | ✅ |
| カスタムアラートルール | ✅ |
Week 1 完了!
所感
- 設定ファイルは相変わらず読みづらいね...でも通知できたのでよかったが監視設定などもう少し踏み込みたかったがボリューの都合で別で考えたい
- kube-prometheus-stack は一発で監視基盤が揃うので便利。NMS/Nagios/Zabbixを個別にセットアップしていた時代を思うと隔世の感
- リソース設定はとりあえずの値だが、ホームラボ規模では問題なく動作している
- アラートのしきい値設計は昔の知識がベースになっているので、Kubernetes ネイティブな考え方(自己修復前提)も今後やりたいかな
9. 次回予告: TLS証明書管理
明日(12/7)は Week 1 最終回: cert-manager による TLS 証明書管理 です。
学べること:
- cert-manager のインストールと設定
- 自己署名証明書の発行
- Ingress への TLS 適用