はじめに
「ジャンルなしオンラインもくもく会 Advent Calendar 2025」の18日目の記事です。
今日は、意図的に障害を起こすカオスエンジニアリングを実践します。「本番環境で障害が起きる前に、障害を起こして耐障害性を検証する」というアプローチです。
本シリーズの全体構成
前回までのおさらい
カオスエンジニアリングとは?
定義
本番環境に近い状況で意図的に障害を注入し、システムの耐障害性を検証する手法
なぜ生まれたのか?
| 従来のテスト | カオスエンジニアリング |
|---|---|
| 正常系のテスト | 異常系のテスト |
| 正しく動くか? | 壊れても大丈夫か? |
| 理想的な環境 | 現実的な環境 |
| ユニットテスト、結合テスト | 本番環境での検証 |
現実
- ネットワークは必ず遅延する
- Podは予期せず落ちる
- ディスクI/Oは突然遅くなる
- メモリ不足は突然起きる
Netflixの事例: Chaos Monkey
Netflixが開発した本番環境でランダムにサーバーを停止するツール
- ✅ 障害に強いアーキテクチャを実現
- ✅ 障害発生時の復旧時間を短縮
- ✅ エンジニアの障害対応スキル向上
Chaos Mesh とは?
特徴
- CNCFプロジェクト(現在Incubating)
- Kubernetes Native(CRDベース)
- 豊富な障害シナリオ(Network, Pod, Stress, I/O, Time など)
- WebベースのUI(Chaos Dashboard)
- 定期的な障害注入(Workflow, Schedule)
サポートする障害タイプ(代表的なものを抜粋)
| 障害タイプ | 説明 | 用途 |
|---|---|---|
| PodChaos | Pod削除/強制終了 | 再起動耐性検証 |
| NetworkChaos | 遅延/パケットロス/帯域制限 | ネットワーク障害検証 |
| StressChaos | CPU/メモリ負荷 | リソース枯渇検証 |
| IOChaos | I/O遅延/エラー | ディスク障害検証 |
| TimeChaos | 時刻ずれ | タイムスタンプ依存処理検証 |
| DNSChaos | DNS解決失敗/遅延 | 外部サービス依存検証 |
| HTTPChaos | HTTPエラー/遅延 | API障害検証 |
Chaos Meshインストール
1. Helm
# Helm Repositoryを追加
helm repo add chaos-mesh https://charts.chaos-mesh.org
helm repo update
# インストール(Talos Linux + containerd環境)
helm install chaos-mesh chaos-mesh/chaos-mesh \
-n chaos-mesh --create-namespace \
--set chaosDaemon.runtime=containerd \
--set chaosDaemon.socketPath=/run/containerd/containerd.sock
# PodSecurity を privileged に設定(chaos-daemonに必要)
kubectl label namespace chaos-mesh pod-security.kubernetes.io/enforce=privileged
# Pod起動確認
kubectl get pods -n chaos-mesh -o wide
NAME READY STATUS RESTARTS AGE
chaos-controller-manager-f864656b8-9k66w 1/1 Running 0 2m
chaos-daemon-jpndf 1/1 Running 0 2m # Worker-03
chaos-daemon-px7dv 1/1 Running 0 2m # Worker-02
chaos-daemon-q42tp 1/1 Running 0 2m # Worker-01
chaos-dashboard-696c7d7796-94gk6 1/1 Running 0 2m
chaos-dns-server-7449ff89-whh67 1/1 Running 0 2m
ポイント: chaos-daemon は DaemonSet で全ノードに配置。これが実際に障害を注入するエージェント。
2. Chaos Dashboard アクセス
# Ingress経由でアクセス
https://chaos.homelab.local
3. Dashboard 認証(RBAC トークン)
Dashboard にアクセスすると、RBAC トークンの入力を求められます。
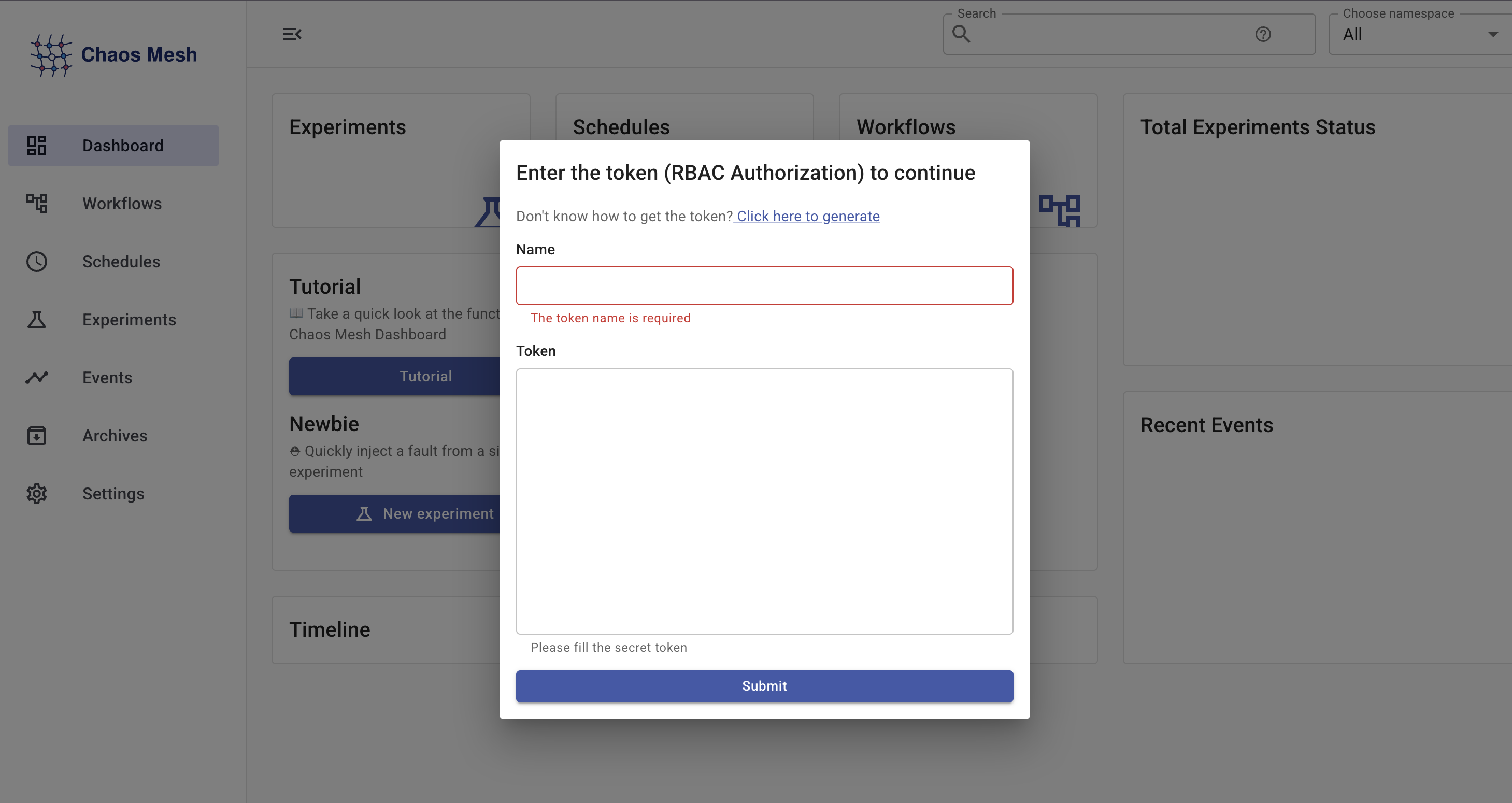
ServiceAccount とトークンを作成します
# ServiceAccount と ClusterRole を作成
cat << 'EOF' | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: chaos-admin
namespace: chaos-mesh
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: chaos-admin
rules:
- apiGroups: ["chaos-mesh.org"]
resources: ["*"]
verbs: ["*"]
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: chaos-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: chaos-admin
subjects:
- kind: ServiceAccount
name: chaos-admin
namespace: chaos-mesh
EOF
# トークン生成(有効期限: 1年)
kubectl create token chaos-admin -n chaos-mesh --duration=8760h
生成されたトークンを Dashboard に入力
-
Name:
chaos-admin - Token: 生成されたJWTトークン
補足: このトークンは ClusterRole なので、全 namespace で chaos 実験を実行可能。特定 namespace に制限する場合は Role + RoleBinding を使用。
実践1: PodChaos(Pod障害)
デモアプリのデプロイ
まず、カオス実験対象のアプリ(podinfo)をデプロイします。
# podinfo をデプロイ(3レプリカ)
helm install podinfo podinfo/podinfo \
-n demo --create-namespace \
--set replicaCount=3 \
--set ui.message="Chaos Target App"
# Pod確認
kubectl get pods -n demo -o wide
NAME READY STATUS RESTARTS AGE NODE
podinfo-86cd999777-bj6rm 1/1 Running 0 13s k8s-worker-01
podinfo-86cd999777-ld69k 1/1 Running 0 13s k8s-worker-02
podinfo-86cd999777-whl58 1/1 Running 0 13s k8s-worker-02
シナリオ: Podが突然落ちる
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-kill-demo
namespace: chaos-mesh
spec:
action: pod-kill
mode: one # 1つだけ削除
selector:
namespaces:
- demo
labelSelectors:
app.kubernetes.io/name: podinfo
duration: "30s"
# PodChaos適用
kubectl apply -f podchaos-kill.yaml
# 実行確認
kubectl get podchaos -n chaos-mesh
NAME AGE
pod-kill-demo 10s
# Podが強制終了される → 自動復旧
kubectl get pods -n demo -o wide
NAME READY STATUS RESTARTS AGE NODE
podinfo-86cd999777-bj6rm 1/1 Running 0 86s k8s-worker-01
podinfo-86cd999777-r8vpf 1/1 Running 0 6s k8s-worker-02 # ← 新規作成!
podinfo-86cd999777-whl58 1/1 Running 0 86s k8s-worker-02
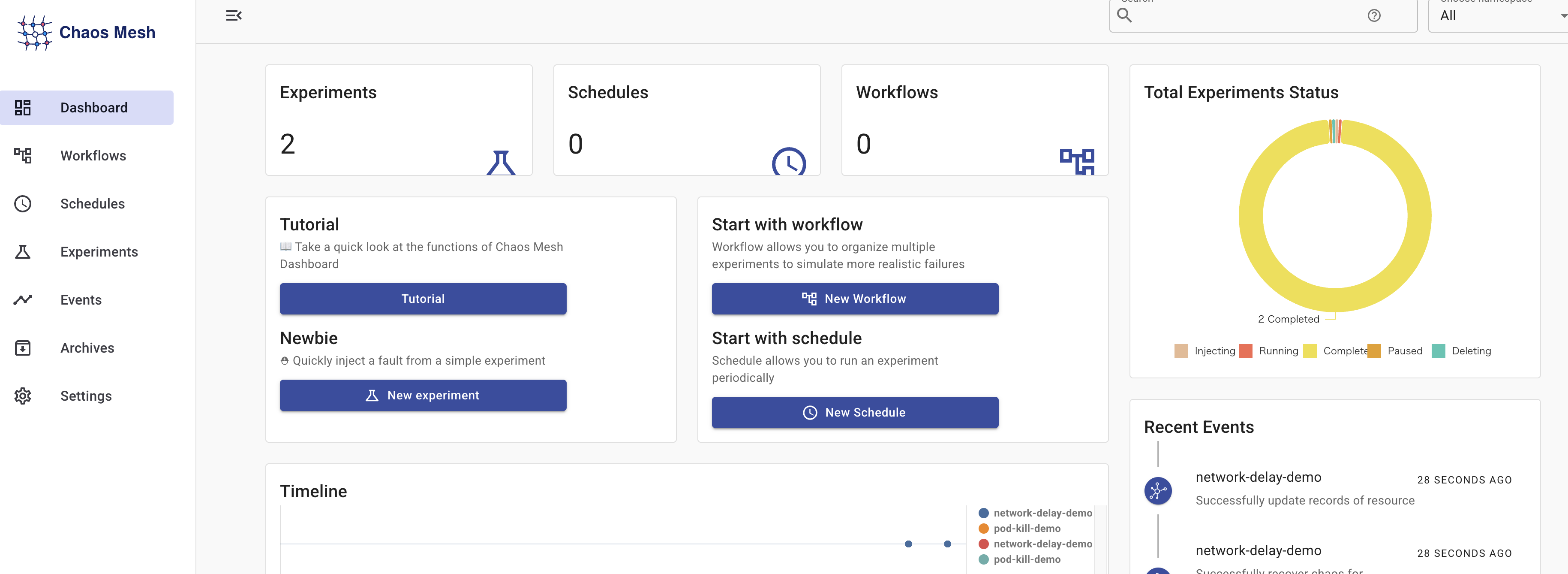
結果: ld69k が kill され、r8vpf が自動で作成された。ReplicaSet が即座に復旧。
検証ポイント
- ✅ ReplicaSet: 自動的に新しいPodが作成されるか? → 即座に復旧
- ✅ Service: トラフィックが正常なPodにルーティングされるか?
- ✅ Graceful Shutdown: アプリケーションが安全に終了するか?
実践2: NetworkChaos(ネットワーク障害)
シナリオ1: ネットワーク遅延
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-delay-demo
namespace: chaos-mesh
spec:
action: delay
mode: all
selector:
namespaces:
- demo
labelSelectors:
app.kubernetes.io/name: podinfo
delay:
latency: "3000ms" # 3秒遅延
correlation: "100" # 100%の確率で適用
jitter: "500ms" # ±500msの揺らぎ
direction: to # 受信トラフィックに遅延
duration: "60s"
# NetworkChaos適用
kubectl apply -f networkchaos-delay.yaml
# Ingress経由でレスポンス時間を計測
curl -sk -w "Time: %{time_total}s\n" -o /dev/null \
https://10.0.0.210 -H "Host: podinfo.homelab.local"
# 遅延注入中: Time: 2.899952s 〜 5.732055s
# 通常時: Time: 0.259037s
結果: 3秒の遅延注入により、レスポンス時間が約 11〜22 倍に増加。体感でも明らかに遅い。
シナリオ2: パケットロス
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-loss
namespace: chaos-mesh
spec:
selector:
namespaces:
- demo
labelSelectors:
app: backend
action: loss
mode: all
# パケットロス設定
loss:
loss: "30" # 30%のパケットをロス
correlation: "80"
direction: to
duration: "5m"
シナリオ3: 帯域制限
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: network-bandwidth
namespace: chaos-mesh
spec:
selector:
namespaces:
- demo
labelSelectors:
app: backend
action: bandwidth
mode: all
# 帯域制限
bandwidth:
rate: "1mbps" # 1Mbpsに制限
limit: 20000 # バッファサイズ
buffer: 10000
direction: to
duration: "5m"
検証ポイント
- ✅ Timeout設定: タイムアウトは適切か?
- ✅ Retry: リトライロジックは機能するか?
- ✅ Circuit Breaker: サーキットブレーカーは動作するか?
- ✅ Fallback: フォールバック処理は適切か?
実践3: StressChaos(リソース負荷)
シナリオ1: CPU負荷
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: stress-cpu
namespace: chaos-mesh
spec:
selector:
namespaces:
- demo
labelSelectors:
app: backend
mode: one
# CPU負荷
stressors:
cpu:
workers: 4 # 4ワーカー
load: 80 # 各ワーカーが80%負荷
duration: "5m"
シナリオ2: メモリ負荷
apiVersion: chaos-mesh.org/v1alpha1
kind: StressChaos
metadata:
name: stress-memory
namespace: chaos-mesh
spec:
selector:
namespaces:
- demo
labelSelectors:
app: backend
mode: one
# メモリ負荷
stressors:
memory:
workers: 4
size: "512MB" # 各ワーカーが512MB消費
duration: "5m"
# リソース使用量確認
kubectl top pod -n demo -l app=backend
NAME CPU(cores) MEMORY(bytes)
backend-5d8b9d8d9f-xxxxx 3200m 2048Mi # ← 負荷注入中
backend-5d8b9d8d9f-yyyyy 100m 256Mi
backend-5d8b9d8d9f-zzzzz 100m 256Mi
検証ポイント
- ✅ HPA: Horizontal Pod Autoscalerは動作するか?
- ✅ Resource Limits: Pod Evictionは適切に発生するか?
- ✅ OOM Kill: Out Of Memoryでの再起動は正常か?
実践4: Workflow(複合障害シナリオ)
シナリオ: 段階的な障害注入
apiVersion: chaos-mesh.org/v1alpha1
kind: Workflow
metadata:
name: demo-chaos-workflow
namespace: chaos-mesh
spec:
entry: entry
templates:
# エントリーポイント
- name: entry
templateType: Serial
children:
- network-delay
- pod-kill
- stress-cpu
# Step 1: ネットワーク遅延(5分間)
- name: network-delay
templateType: NetworkChaos
deadline: 5m
networkChaos:
selector:
namespaces:
- demo
labelSelectors:
app: backend
action: delay
mode: all
delay:
latency: "500ms"
direction: to
duration: "5m"
# Step 2: Pod削除(1つ)
- name: pod-kill
templateType: PodChaos
deadline: 1m
podChaos:
selector:
namespaces:
- demo
labelSelectors:
app: backend
action: pod-kill
mode: one
duration: "30s"
# Step 3: CPU負荷(5分間)
- name: stress-cpu
templateType: StressChaos
deadline: 5m
stressChaos:
selector:
namespaces:
- demo
labelSelectors:
app: backend
mode: one
stressors:
cpu:
workers: 4
load: 90
duration: "5m"
# Workflow適用
kubectl apply -f workflow.yaml
# 実行状態確認
kubectl get workflow -n chaos-mesh
NAME AGE PHASE
demo-chaos-workflow 2m Running
# 詳細確認
kubectl describe workflow demo-chaos-workflow -n chaos-mesh
並列実行(Parallel)
apiVersion: chaos-mesh.org/v1alpha1
kind: Workflow
metadata:
name: parallel-chaos
namespace: chaos-mesh
spec:
entry: entry
templates:
- name: entry
templateType: Parallel # 並列実行
children:
- network-delay
- stress-cpu
- io-delay
# 同時に3つの障害を注入
- name: network-delay
# ...
- name: stress-cpu
# ...
- name: io-delay
# ...
実践5: Schedule(定期実行)
毎日10時にPodを1つ削除
apiVersion: chaos-mesh.org/v1alpha1
kind: Schedule
metadata:
name: scheduled-pod-kill
namespace: chaos-mesh
spec:
# Cron形式
schedule: "0 10 * * *" # 毎日10時
# 実行履歴を保持
historyLimit: 5
# 同時実行を許可しない
concurrencyPolicy: Forbid
type: PodChaos
podChaos:
selector:
namespaces:
- demo
labelSelectors:
app: backend
action: pod-kill
mode: one
duration: "30s"
# Schedule適用
kubectl apply -f schedule.yaml
# 実行履歴確認
kubectl get schedule scheduled-pod-kill -n chaos-mesh -o yaml
status:
active:
- kind: PodChaos
name: scheduled-pod-kill-xxxxx
namespace: chaos-mesh
lastScheduleTime: "2025-12-18T01:00:00Z"
Chaos Dashboard(Web UI)
機能
- Chaos実験作成: GUIで障害シナリオを作成
- 実行状況監視: リアルタイムで実験の進捗を確認
- 結果分析: メトリクス、ログ、イベントを統合表示
- アーカイブ: 過去の実験結果を保存
Dashboard での実験作成
1. New Experiment をクリック
2. 障害タイプを選択(PodChaos, NetworkChaos, etc.)
3. 対象Podをラベルセレクタで指定
4. パラメータを設定(遅延時間、削除モードなど)
5. Submit で実験開始
Chaos Meshで実現できること
| 障害シナリオ | 検証内容 |
|---|---|
| PodChaos | 再起動耐性、ReplicaSetの動作 |
| NetworkChaos | タイムアウト、リトライ、Circuit Breaker |
| StressChaos | HPA、Resource Limits、OOM対応 |
| Workflow | 複合障害シナリオ |
| Schedule | 定期的な耐障害性検証 |
導入効果
- ✅ 本番障害の事前検証: 障害が起きる前に対策
- ✅ 復旧時間の短縮: 障害対応の練習
- ✅ 自信: 「壊れても大丈夫」という確信
- ✅ 継続的改善: 定期的な検証で劣化を防止
まとめ
所感
実際にホームラボ環境で Chaos Mesh を動かしてみて感じたこと
良かった点
- 導入は簡単: Helmコマンドで導入完了
- 即座に効果が見える: PodChaosでPodをkillすると、ReplicaSetが数秒で復旧する様子が確認できた
- NetworkChaosが強力: 1秒未満だと体感としてわかりにくいが、3秒の遅延を注入するとレスポンス時間が11〜22倍に。ブラウザでも体感できるレベルの遅延がでてよかったです
今後試したいこと
- カオス実験中はGrafanaでメトリクスを見ながら実施する仕組みをいれる
- Scheduleを使った定期的な障害注入を行って慣れていきたい
- Workflowで複合障害シナリオ(遅延 → Pod kill → CPU 負荷の順番で実行)、ただし自分の首を絞めない程度で
シリーズを通して
- 取り上げたいがボリュームからできないものも多かったので、後日気になるものを継続していきたいと思います
- 数年前と比べてかなりの頻度でバージョンも上がっていたり、機能も増えているので、開発者に感謝しつつ追いかけていきます
- なぜ〇〇が実現できるの?がいくつかあったので深堀りをして理解に努めていきたいですね
さいごに
- 今回アドベントカレンダーの場を作ってくれたサーバー管理者様に感謝して来年はもうちょいアウトプットをしていきたいと思います!
シリーズ完走
9日間のKubernetes学習シリーズ、お疲れさまでした!