概要
Yukarinライブラリでの音質変換で、悩まされるのは音質の向上です。
パラレルデータ(第1段用の学習データ)を100〜300程用意すれば、大まかなターゲットボイスへの変換はできます。
しかし、クオリティをヒホ様のデモ動画レベルまで引き上げるには、試行錯誤が必要となります。
本記事では、手順通りに処理をスクリーニングするだけで、第1段の音質変換クオリティをあげる方法を紹介します。
本手法は、経験や勘に頼らず、定量的にパラレルデータの品質を評価することができると言うメリットが大きいと思っています(多少強引ですが)。
1. そんで、どれくらい効果あるの?
一番気になるところかと思いますので、まずはデモ音声を紹介します。
Loss: "discriminator/loss"
Acc: "discriminator/accuracy"
iteration : 音声変換に使った学習データのイテレーション数
| データ数 | f0推定 | 評価値 | floor | ceil | Iteration | Acc | loss | 音声 | |
|---|---|---|---|---|---|---|---|---|---|
| hervest No1 | 504 | hervest | 3,157 | - | - | 75,000 | 0.98 | 0.159 | link |
| hervest No2 | 402 | hervest | 2,748 | - | - | 60,000 | 0.98 | 0.147 | link |
| hervest No3 | 304 | hervest | 2,469 | - | - | 50,000 | 0.98 | 0.149 | link |
| dio No1 | 504 | dio | 3,006 | - | - | 75,000 | 0.99 | 0.083 | link |
| dio No2 | 504 | dio | 2,879 | 50 | 200 | 95,000 | 0.98 | 0.152 | link |
| dio No3 | 419 | dio | 2,701 | 50 | 200 | 100,000 | 0.98 | 0.160 | link |
| dio No4 | 300 | dio | 2,506 | 50 | 200 | 65,000 | 0.98 | 0.134 | link |
2. 評価方法について
2.1 何をしているの?
学習用のパラレルデータの f0のズレを算出して、その値を評価値としています。
つまり、差分値が小さいほど、f0の波形の対応が取れており、学習データとして優れていると評価しています。
2.2 何で f0の値に着目したの?
Yukarinライブラリ(yukarin)は、音声を下記の3つに分解し、自分のスペクトル包絡をターゲットのスペクトル包絡へ変換しています。
よって、学習用のパラレルデータは精度よくスペクトル包絡が算出できている必要があります。
- 基本周波数(f0): 音声解析のベースとなる周波数、声が高いとこの値も高くなる。
- スペクトル包絡: 声の特徴を表します。ゆかりっぽい声の情報はこの値で表される。
- 非周期性指標: ゆらぎ・雑音を表します。この成分が無いと機械的な声になる。
Yukarinライブラリでの音質変換は、自分の"スペクトル包絡"をターゲットの"スペクトル包絡"へ変換することで実現しています。
この"スペクトル包絡"を精度よく検出するたには、f0を高精度に推定されていることが前提となります。
つまり、『f0 の精度が低ければ、学習データ("スペクトル包絡")の精度は低い』と言うことができます。
本記事では、**「パラレルデータの f0の推定が自声・ターゲットボイス共に同等に推定できている」**場合、学習データとして適切であると仮定しています。
この f0がうまく推定できない場合、主に2つの"ズレ"が発生しています。
2.3 "ズレ"とは?
f0の推定プロットは2軸で、下図のように2つ軸があります。
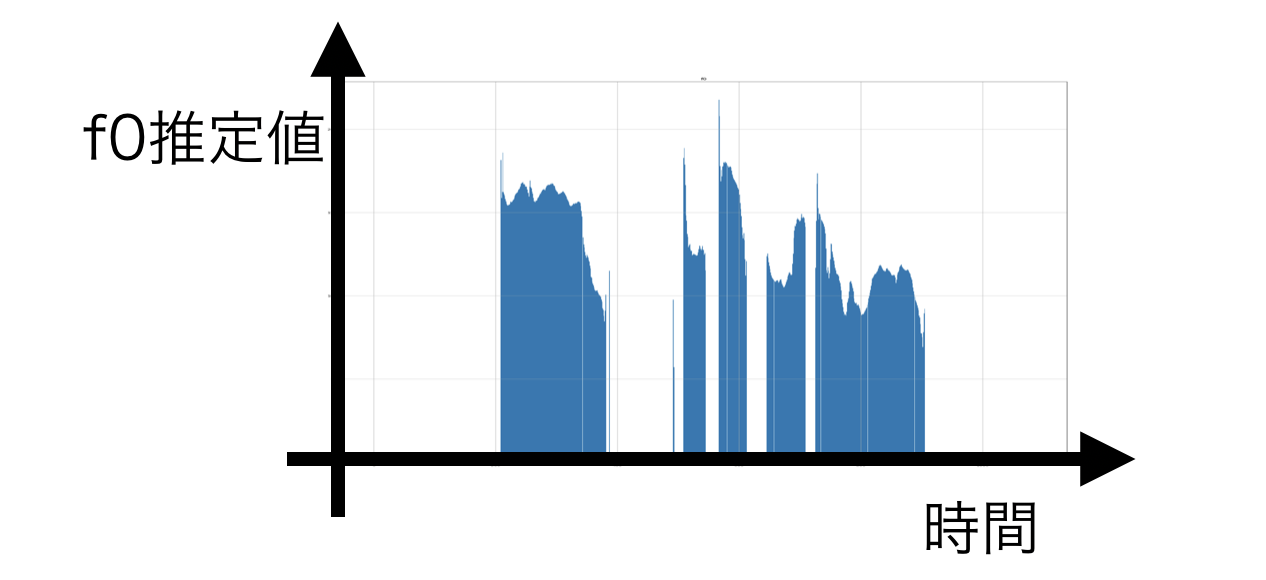
そして、”ズレ”には2種類あります。
- 時間軸のズレ
- f0推定のズレ
まずは、ズレが少ない例を提示します。
下図が、自分・ターゲットボイスをf0をプロットして、ズレが少なかった例です。
*差分画像(一番右)で茶色に見えているのが差分です。より茶色が少ない画像が一致度が高いとなります。

時間軸のズレ
時間軸のズレは、自声とターゲット音声の発話タイミングがずれているということです。

Z.3.2 第1段のゆかり・自声の収録で、自声とターゲット音声が**『ハモって聞こえる』レベルに合わせるのがベストです。この音声データが精度を左右します!** と書いています。
これは時間軸のズレを少なくするということを言っています。
これは、学習データを生成する際に、プログラムで調整されますが、精度に限界があるためズレが発生することがあります。
(yukarin リポジトリでは B.2 音響特徴量のアライメントの処理が時間軸のズレを調整する処理)
このズレは音声をプロットしたり、調整後の音声を比較して聞いてみることで、直感的に理解できます。
アジャスト後のwav音声の出力は、Yukarinライブラリのyukarin/scripts/generate_aligned_wave.pyコマンドを使うことで確認できます。
コマンド例
mkdir dat/1st_models_y/yukari/aligned_wav_split
python yukarin/scripts/generate_aligned_wave.py \
-if1 './dat/1st_models_y/yukari/npy_pair/own/*.npy' \
-if2 './dat/1st_models_y/yukari/npy_pair/target/*.npy' \
-ii './dat/1st_models_y/yukari/aligned_indexes/*.npy' \
-o 'dat/1st_models_y/yukari/aligned_wav_split'
上記を実行するとdat/1st_models_y/yukari/aligned_wav_splitディレクトリに、調整後の音声が左右から再生されます。
ヘッドフォンを使うと確認しやすいです。
f0推定のズレ
経験則ですが、f0の推定にもブレが発生します。
例えば、下図は自分のf0推定値にスパイクが発生して、f0推定値がずれています。
f0は声の高さの抑揚と解釈することができますので、一瞬だけだ音声が2倍以上高くなると言うのは f0の推定誤差と言うことができます。
(f0推定がうまくできていないケースは様々あります)

経験則では、下記の要素で f0の推定精度が変化すると思われます。
- マイク・ノイズの特性
- 話者の特性
- f0推定手法の違い(harvest, dio)
- f0推定オプション(floor, ceil)
自分の場合は、下記の設定が一番安定してf0推定ができていました。
その結果は記事冒頭の表・音声サンプルの通り、音声変換精度の向上に寄与しました。
- f0推定法 dio
- floor: 50, ceil: 200
補足: 厳密的に計算するには
本手法は下記の2点の厳密性を無視しています。
-
画像比較の方法の選定
現在では自動的に縦軸をスケーリングしたプロット画像を単純比較しています。この比較方法が適切かどうかは議論の余地があると思います。 -
音声データ長による正規化
パラレルデータの録音時間はそれぞれ違うので、差分値を録音時間に応じて正規化する必要があります。
しかし、処理が煩雑になるので、無視しています。
3. どうやって使うの?
『Yukarinライブラリ』become-yukarin, yukarin コマンド解説 のディレクトリ構成であることを前提に解説します。
また、本コマンドは yukarinライブラリ用のパラレルデータを処理する前提です。
3.a 筆者自作 yukarin-tools を更新する
cd yukarin-tools
git pull
- git を使っていない場合はこちらからダウンロードしてください。
3.b f0をプロットする
# ディレクトリ作成
mkdir dat/1st_models_y/yukari/aligned_wav_split
# 差分イメージ
python yukarin-tools/generate_aligned_wave_split.py \
-if1 './dat/1st_models_y/yukari/npy_pair/own/*.npy' \
-if2 './dat/1st_models_y/yukari/npy_pair/target/*.npy' \
-ii './dat/1st_models_y/yukari/aligned_indexes/*.npy' \
-o 'dat/1st_models_y/yukari/aligned_wav_split'
3.c プロットイメージ(b)の差分画像を生成する
# f0 差分イメージ
./yukarin-tools/generate_f0_diff.js dat/1st_models_y/yukari/aligned_wav_split
sh /tmp/command4generate_diff_images.sh
./yukarin-tools/generate_f0_diff.js dat/1st_models_y/yukari/aligned_wav_splitは差分を計算するコマンドを出力するだけです。
差分を計算する処理自体はsh /tmp/command4generate_diff_images.shで実行されます。
3.d 差分画像(c)から差分の数値を取得する
# f0 の差分値
./yukarin-tools/calculate_f0_diff.js dat/1st_models_y/yukari/aligned_wav_split
3.e 差分数値(d)の簡易プロット・統計値を取得する
下記コマンドを実行すると、パラレルデータの差分値のレポートを確認できます。
# f0 統計値テキスト出力
./yukarin-tools/analysis_f0_diff.js dat/1st_models_y/yukari/aligned_wav_split/all_diff.json
出力例
v_art001_sjis 2527 : ###################################################
v_art002_sjis 2360 : ################################################
v_art003_sjis 2128 : ###########################################
v_art004_sjis 3383 : ####################################################################
...
v_art502_sjis 4959 : ############################################################################
v_art503_sjis 3977 : #############################################################
-------------------------------------------
OK statistics
length: 503
min: 1,953
max: 6,528
sum: 1,893,704
ave: 3,764
sigma: 768
自分は評価値の平均値(ave)がより小さい方が f0の推定誤差が小さいと言うことができます。
経験則的にもこの値が小さい方が音声変換の精度が高くなりました。
3.f 評価値が指定値以下のものだけをレポートする
-t [評価値]オプションをつけてanalysis_f0_diff.jsを実行すると、指定数値以上の評価値のパラレルデータのレポート表示されます。
コマンド例
./yukarin-tools/analysis_f0_diff.js -t 3910 dat/1st_models_y/yukari/aligned_wav_split/all_diff.json
結果例
v_art002_sjis 2124 : #############################################################
v_art003_sjis 2168 : ##############################################################
v_art006_sjis 2233 : ################################################################
...
v_art500_sjis 2619 : ###########################################################################
v_art502_sjis 3043 : #######################################################################################
v_art503_sjis 2287 : ##################################################################
-------------------------------------------
OK statistics
length: 336
min: 1,270
max: 3,482
sum: 858,643
ave: 2,555
sigma: 490
当たり前ですが、平均値は-tで指定した値以下になります。
3.g 評価値が指定値以上のものだけをレポートする
-tオプションに加えて、-fオプションを加えてanalysis_f0_diff.jsを実行すると、指定した評価値以下のデータを表示します。
コマンド例
./yukarin-tools/analysis_f0_diff.js -f -t 3500 dat/1st_models_y/yukari/aligned_wav_split/all_diff.json
出力例
v_art004_sjis 3619 : ###########################################################################################
v_art017_sjis 3721 : #############################################################################################
v_art031_sjis 3881 : #################################################################################################
...
v_art480_sjis 3914 : ##################################################################################################
v_art484_sjis 3983 : ####################################################################################################
v_art501_sjis 3556 : #########################################################################################
-------------------------------------------
NG statistics
length: 66
min: 3,508
max: 3,987
sum: 246,136
ave: 3,729
sigma: 150
3.h 評価値が指定値以上のものだけを削除する
-t [評価値]オプションに加えて-c [aligned_wav_splitまでのパス]を指定します。
コマンド例
./yukarin-tools/analysis_f0_diff.js -c dat/1st_models_y/yukari -t 4410 dat/1st_models_y/yukari/aligned_wav_split/all_diff.json
削除コマンドを実行と必要な再計算
削除コマンドの実行は上記の出力を実行するだけですが、削除後に "f0の平均値" と "e.差分画像(から差分の数値を取得" は再実行する必要があります。
一連のコマンドは下記の通りです。
注: 下記コマンドを実行すると該当するデータが下記ディレクトリから削除されます
念の為、実行前にディレクトリごとコピーしたりして、バックアップしてください。
- dat/1st_models_y/yukari/aligned_indexes: 自分とターゲット音声の調整データディレクトリ
- dat/1st_models_y/yukari/npy_pair/target: 自分の音声の学習データディレクトリ
- dat/1st_models_y/yukari/npy_pair/own : ターゲット音声の学習データディレクトリ
- dat/1st_models_y/yukari/voice_pair/target : 自分の音声ディレクトリディレクトリ
- dat/1st_models_y/yukari/voice_pair/own : ターゲット音声ディレクトリ
# 削除コマンドを dat/1st_models_y/yukari/delete.sh に出力
./yukarin-tools/analysis_f0_diff.js -c dat/1st_models_y/yukari -t 4410 dat/1st_models_y/yukari/aligned_wav_split/all_diff.json > dat/1st_models_y/yukari/delete.sh
# 削除コマンドを実行
sh dat/1st_models_y/yukari/delete.sh
# パラレルデータが削除されたので、f0の平均値は再計算する必要がある
python yukarin/scripts/extract_f0_statistics.py\
-i './dat/1st_models_y/yukari/npy_pair/own/*.npy' \
-o './dat/1st_models_y/yukari/statistics/own.npy'
python yukarin/scripts/extract_f0_statistics.py\
-i './dat/1st_models_y/yukari/npy_pair/target/*.npy' \
-o './dat/1st_models_y/yukari/statistics/target.npy'
# e.差分画像(から差分の数値を取得 も再計算
./yukarin-tools/analysis_f0_diff.js dat/1st_models_y/yukari/aligned_wav_split/all_diff.json
以上を実行したら、通常の手順で学習yukarin/train.pyを行ってください。
4. 終わりに
わかりにくいところ、上記手法で逆に音質が悪くなったなど、何かあればご気軽にコメントください。
特にわかりにくいところなどのご質問は、下記のサーバでお話しいただくのが一番早いかと思います。
ご気軽にご参加ください。
Yukarinライブラリ Discord サーバ 招待リンク
以上、楽しい音声変換ライフを!
おまけ f0 推定方を dioに変更する方法
yukarin リポジトリでは f0推定を dioにするオプションがなくなったので、コードを書き換えてください。
(注: realtime-yukarinでも f0推定を dioにする場合は、requirements.txt から git+https://github.com/Hiroshiba/yukarin を削除してください)
yukarin/yukarin/acoustic_feature.py L:123〜131あたりのコードを
f0, t = pyworld.harvest(
x,
fs,
frame_period=frame_period,
f0_floor=f0_floor,
f0_ceil=f0_ceil,
)
を
f0, t = pyworld.dio(
x,
fs,
frame_period=frame_period,
f0_floor=f0_floor,
f0_ceil=f0_ceil,
)
に書き換える。