はじめに
1台のDockerホスト上のコンテナのリソース監視はcAdvisorが一般的になっているような気がします。
それでは複数台のDockerホスト上のコンテナのリソース監視はどうするのかなと調べてみると、以下のような方法があるようです。
- cAdvisorで直接InfluxDBに保存し、Grafanaで可視化
- HeapsterでcAdvisorから情報を収集してInfluxDBに保存し、Grafanaで可視化
- cAdvisorからfluentでInfluxDBに保存し、Grafanaで可視化
この記事では一つ目の方法を試してみようと思います。
とりあえず今出てきた登場人物の簡単な紹介とリンク紹介を。
なお、この記事はだいたい3月中旬に書いた内容です。
cAdvisor
- Dockerコンテナのリソースモニタリングツール
- Kuberenetesで使うために主にGoogle社が開発したオープンソースソフトウェア
- cAdvisor自体もDockerコンテナとして動かすのが標準だが、Go言語で実装されており依存ライブラリの必要なく単体でもインストール可能。
- 公式サイト
- google/cadvisor
- 解説記事
- cAdvisorとInfluxDBとGrafanaでDockerリソースの可視化を行うDockerコンテナ群をFigでデプロイしたPaaS上にてGo言語でRedisを叩く
InfluxDB
- 時系列データベース。
- 現在のStableバージョンは0.8.8
- 0.9が3月末にリリース予定(が、今見たら4月リリースに書き換わっていた)
- 根本からの全体的な改善であり、大きな機能追加はない。
- 特徴
- HTTP APIでアクセス可能
- databaseとseriesの2階層(seriesはRDBのテーブルに相当)
- スキーマレス
- SQLライクなクエリ言語
- 時系列での集計関数が豊富
- 分散ストレージ
- 豊富なクライアントライブラリ
- 管理Web UI
- 公式サイト
- InfluxDB - Open Source Time Series, Metrics, and Analytics Database
- 解説記事
- InfluxDB の概要 - sonots #tokyoinfluxdb
- InfluxDBきほんのき - Qiita
- InfluxDBとGrafanaとfluentdで、twitterデータのリアルタイム集計・可視化 - Qiita
- 便利な時系列データベースのInfluxDBと、その可視化ツールGrafanaについて - geniee’s tech blog
Grafana
- Kibanaをベースに作られたダッシュボードツール。
- 特に時系列データのグラフ表示にフォーカスしている。
- Graphite、InfluxDB、OpenTSDBに対応。
- InfluxDB以外で使う場合は、ダッシュボードデータの保存のためにElasticsearchが必要。
- 公式サイト
- Grafana Documentation
- 解説記事
- Grafana on InfluxDB をちょっとだけ触ってみた - Qiita
Heapster
- Kubernetesクラスタ内のコンテナのリソースモニタリングツール。
- Kubernetesのモニタリングツールとして作られたが、CoreOSでも動作、対象ホストを設定すればクラスタリングツールなしでも動作する。
- cAdvisorを各サーバーに入れ、Heapsterが各cAdvisorからデータを取得し、InfluxDBに保存、Grafanaで可視化する。という仕組み
- メリット
- Kubernetesクラスタ内の全てのminionを自動で発見
- pod ID、コンテナ名、pod IP、ホスト名、ラベルを統計情報と一緒に保存
- クラスタリングツールを使わない場合、あまりメリットがない。
- 公式サイト
- GoogleCloudPlatform/heapster
- 解説記事
- Monitoring Kubernetes - Hatena Developer Blog
- Installing cAdvisor and Heapster on bare metal Kubernetes - Das Blinken Lichten
環境構築手順
では、表題の「cAdvisor、InfluxDB、GrafanaでDockerコンテナのリソース監視」をする環境を構築していきましょう。
cAdvisorとInfluxDBとGrafanaでDockerリソースの可視化を行うDockerコンテナ群をFigでデプロイしたPaaS上にてGo言語でRedisを叩くの手順を参考に、Figは使わずに複数サーバーに対して構築していきます。(でも、今見るとページが開かなくなっている。。。)
以下のような構成を作っていきます。
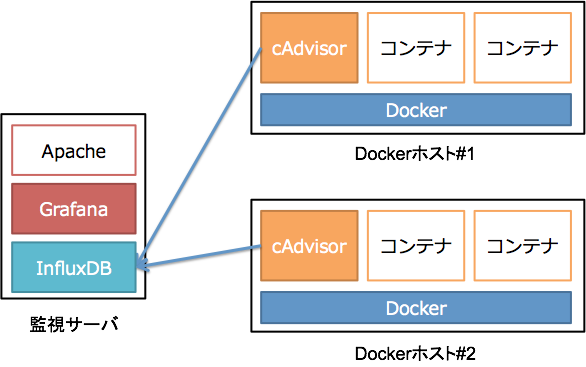
CentOS 7のインスタンスを作成
CentOS 7 (x86_64) with Updates HVM on AWS Marketplaceを3つ作成。
- influxDB, Grafana
- Dockerホスト、cAdvisor(2台)
としましょう。
全部同じセキュリティーグループにしておきます。(別にしなくてもいいです。)
SSHログインはcentosユーザです。
$ ssh -i <SSHキー> centos@<IPアドレス>
全サーバーのパッケージを最新にし、wgetをインストールしておきます。
$ sudo yum -y update
$ sudo yum -y install wget
influxDB、Grafanaサーバーのセットアップ
InfluxDBインストール
InfluxDB Documentationの通りインストールします。
$ wget http://s3.amazonaws.com/influxdb/influxdb-latest-1.x86_64.rpm
$ sudo rpm -ivh influxdb-latest-1.x86_64.rpm
InfluxDBを起動し、OS起動時に起動するように設定。
$ sudo service influxdb start
$ sudo chkconfig influxdb on
セキュリティグループで8083と8086を開けます。
管理Web UIにアクセスして動くことを確認します。
http://<IPアドレス>:8083/ にアクセスすると以下の画面が表示されます。
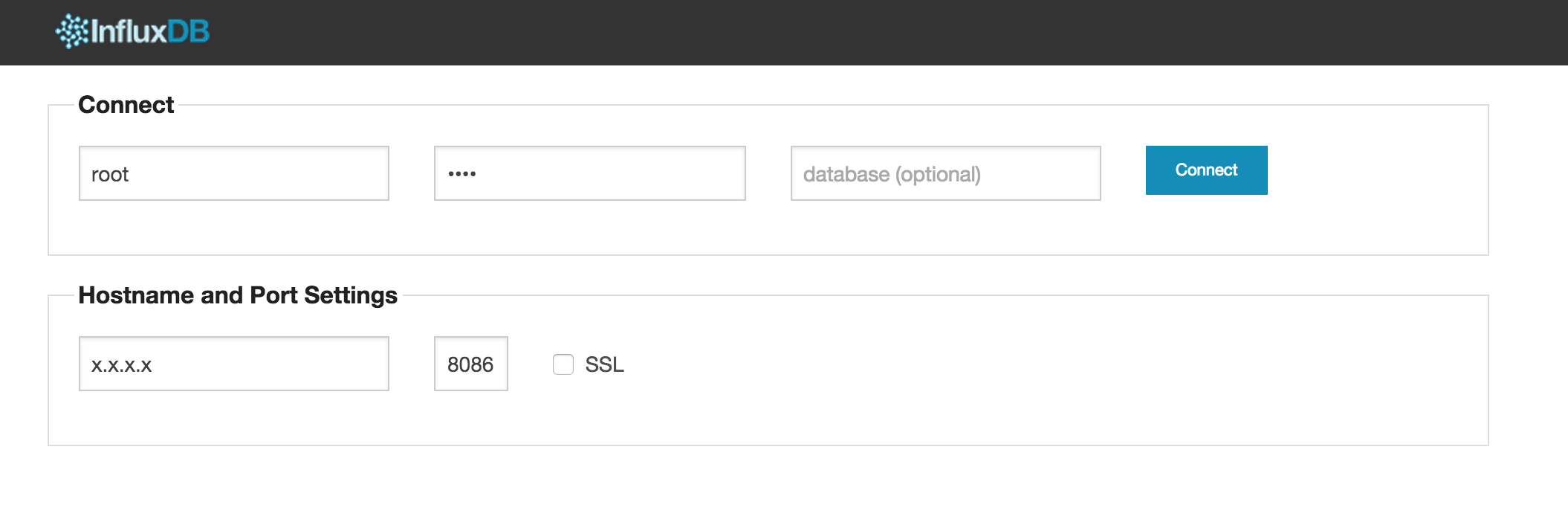
ユーザ、パスワードにroot/rootを入力し、ホスト名はサーバーのIPアドレス、ポートに8086を入力し、「Connect」を押します。
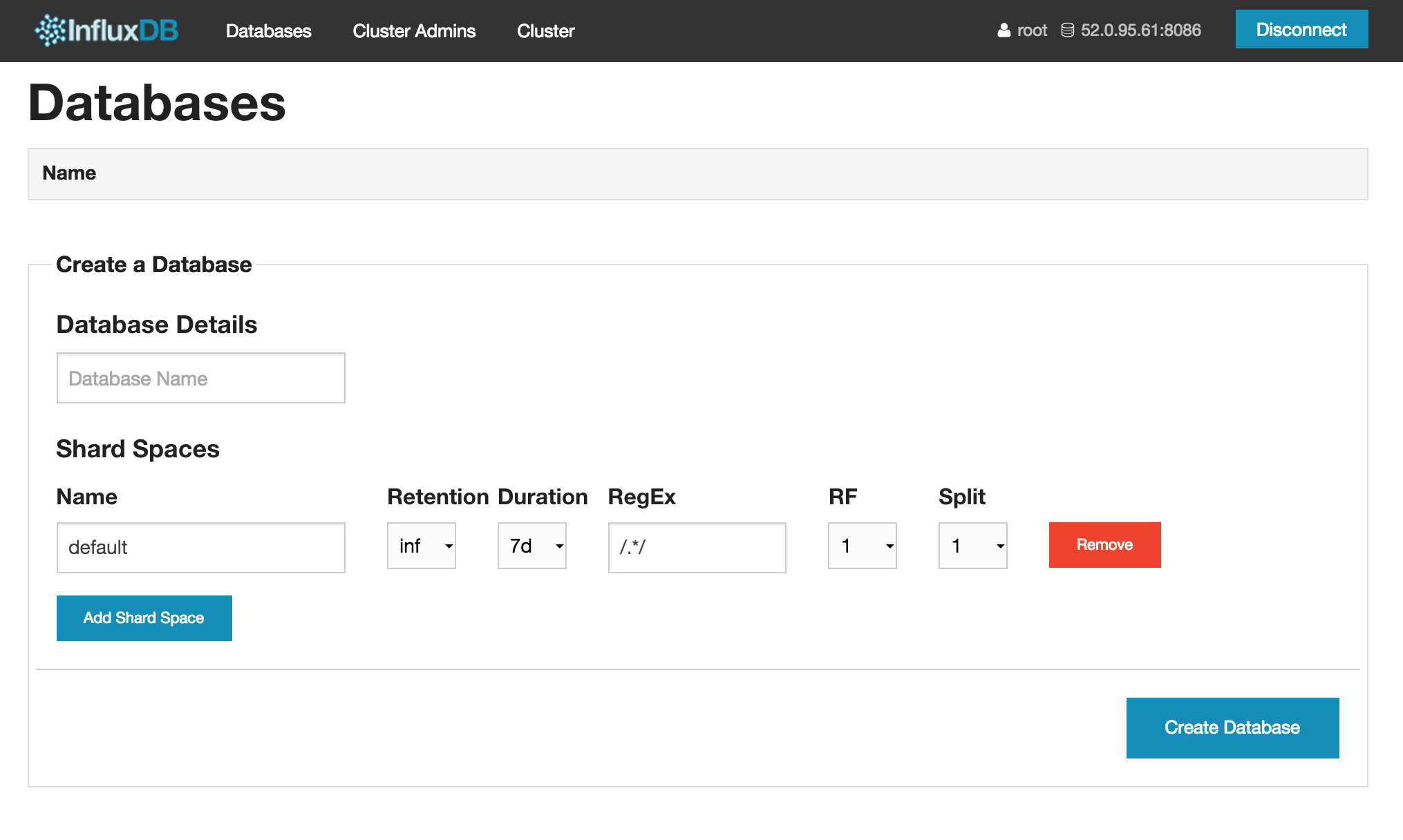
サンプルデータベースを作ってみます。Database Nameにtestと入力し、「Create Database」をクリックします。
後でGrafanaの設定情報を入れるgrafanaデータベースとcAdvisorのデータを入れるcadvisorデータベースも作成しておいてください。
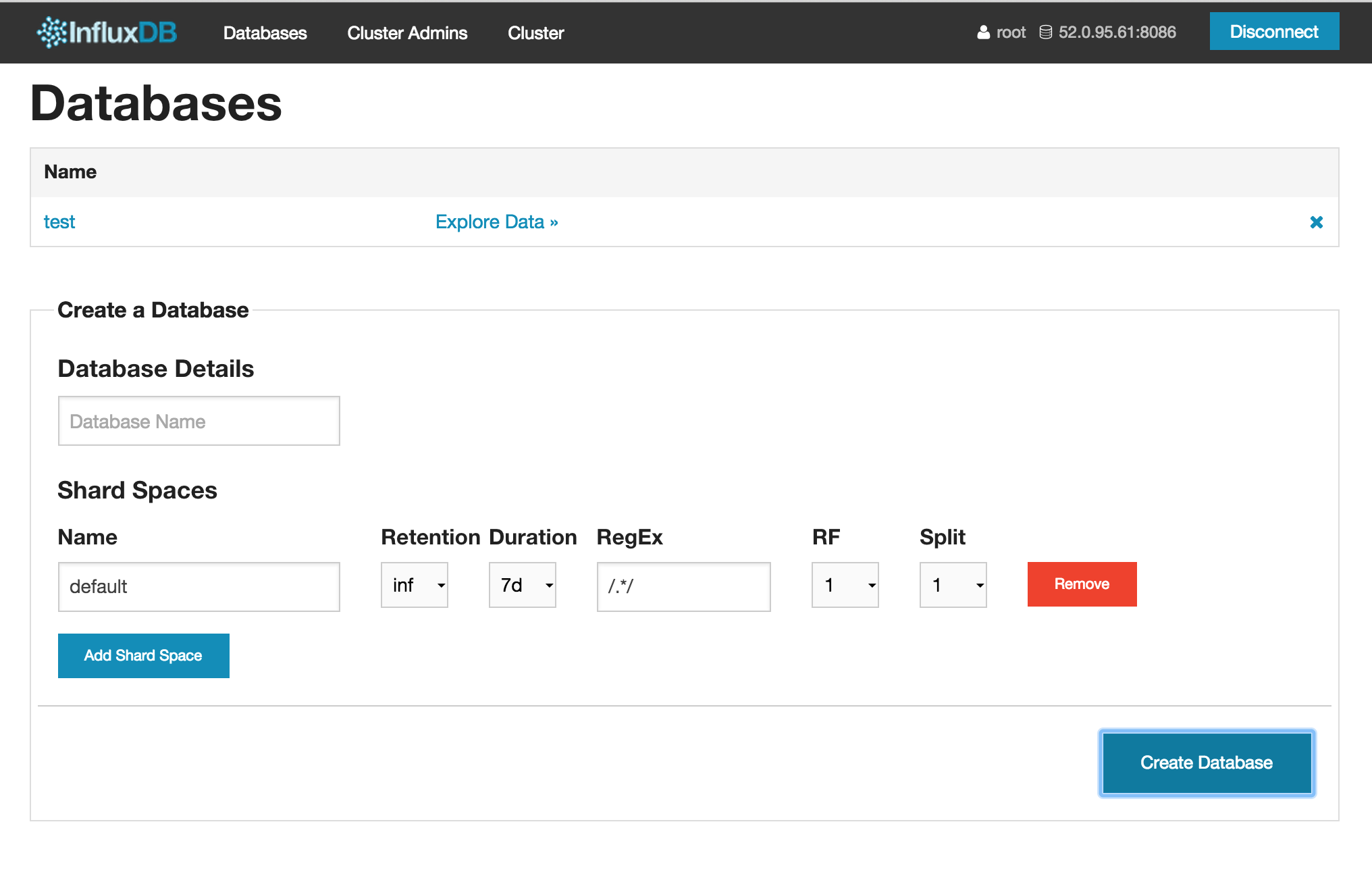
WebUIからもデータを入れられるのですが、一件ずつしか入れられないので、REST APIでデータを入れてみます。
$ curl -X POST 'http://localhost:8086/db/test/series?u=root&p=root' -d \
'[{"name": "nikkei_average", "columns": ["time", "price"], "points": [[1419778800000, 17729.84], [1419519600000, 17818.96], [1418083200000, 17450.77]]}]'
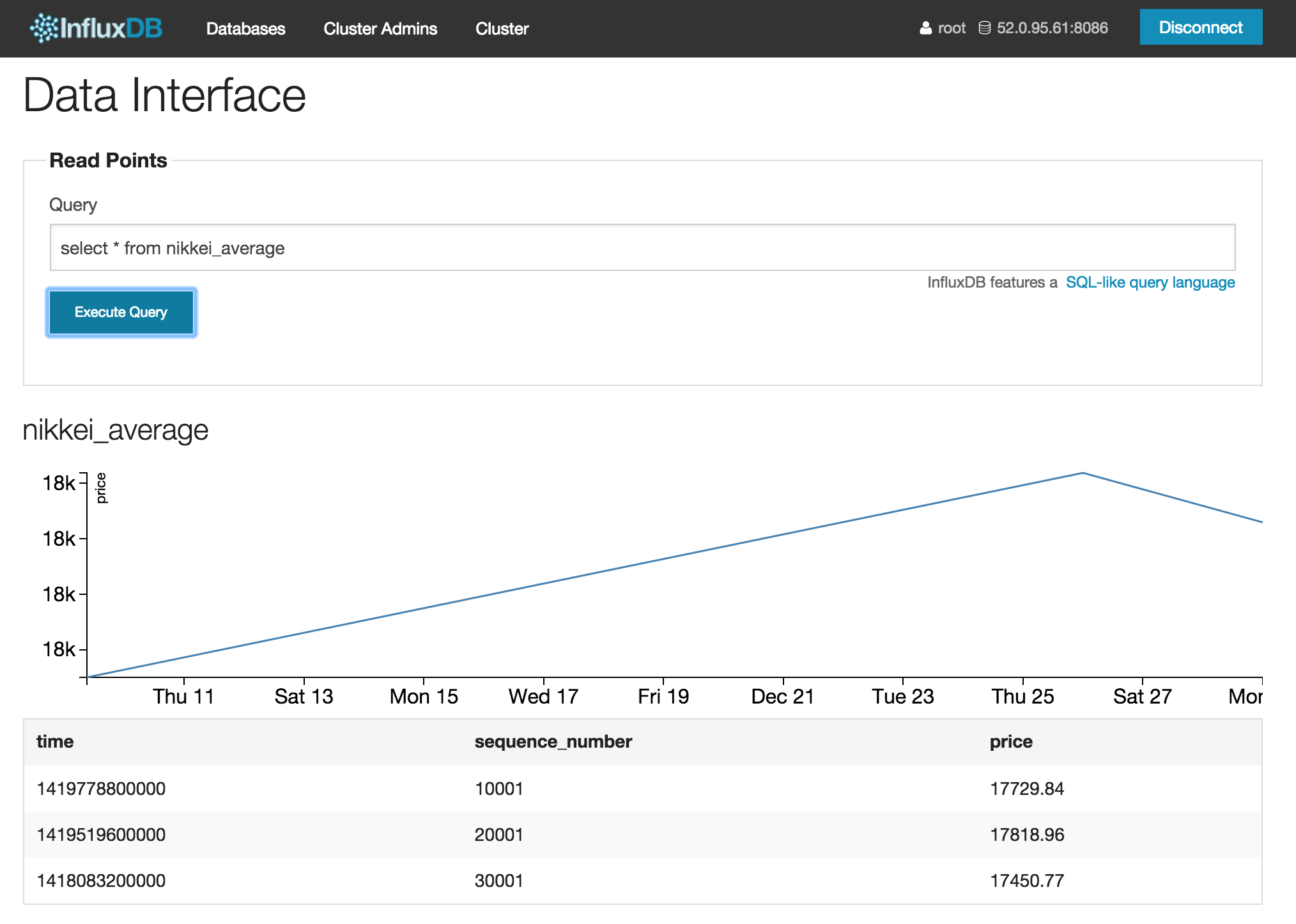
testデータベースの「Explore Data »」からデータベースのRead/Writeをする画面に行き、select * from nikkei_averageというQueryを実行すると以下のようにデータを見ることができます。
Grafanaインストール
Install & Configure - Grafana Documentationを参考にインストール。
$ wget http://grafanarel.s3.amazonaws.com/grafana-1.9.1.tar.gz
$ tar zxvf grafana-1.9.1.tar.gz
$ sudo mv grafana-1.9.1 /opt/
$ cd /opt/grafana-1.9.1
$ cp config.sample.js config.js
influxdbの設定サンプルを参考にconfig.jsを以下のように設定します。
とりあえず先ほど作成したtestデータベースに接続してみます。
cadvisorは後でcAdvisorが収集したデータを入れるデータベースです。まだありませんが、先に設定しておきます。
grafanaデータベースはGrafanaのダッシュボードの設定情報を保存するデータベースです。
<IPアドレス>にはこのサーバーのIPアドレスを指定します。
datasources: {
test: {
type: 'influxdb',
url: "http://<IPアドレス>:8086/db/test",
username: 'root',
password: 'root',
},
cadvisor: {
type: 'influxdb',
url: "http://<IPアドレス>:8086/db/cadvisor",
username: 'root',
password: 'root',
},
grafana: {
type: 'influxdb',
url: "http://<IPアドレス>:8086/db/grafana",
username: 'root',
password: 'root',
grafanaDB: true
},
},
Webサーバーが入っていないので、Apacheをインストールします。
$ sudo yum -y install httpd
$ sudo vim /etc/httpd/conf.d/grafana.conf
grafana.confは以下のように設定しました。
alias /grafana /opt/grafana-1.9.1
<Directory /opt/grafana-1.9.1>
Require all granted
</Directory>
Webサーバープロセスからのアクセス許可設定。
$ sudo restorecon -R /opt/grafana-1.9.1/
セキュリティーグループで80も開けます。
Apacheを起動します。自動起動も設定します。
$ sudo systemctl start httpd
$ sudo systemctl enable httpd.service
http://<IPアドレス>/grafana/にアクセスすると以下のように表示されます。
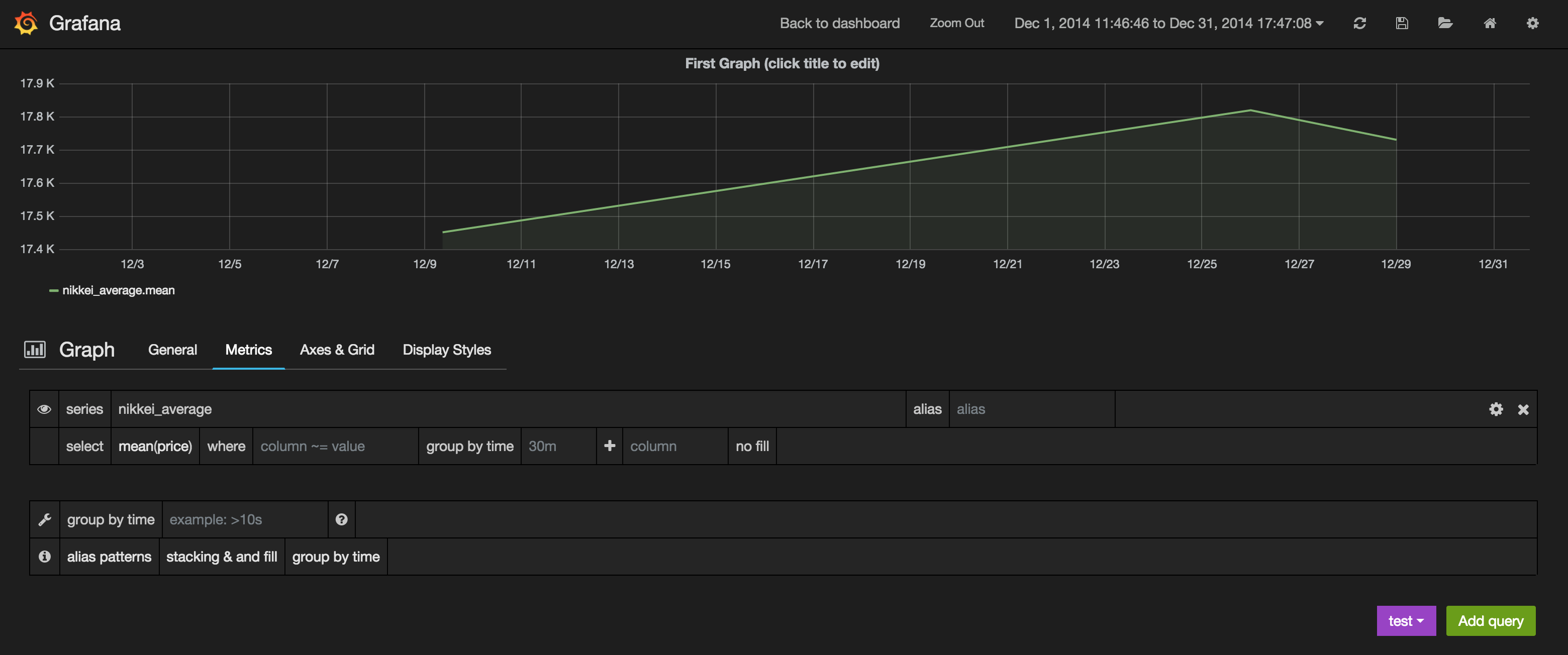
グラフをEditし、日付範囲を2014/12/01-2014/12/31にして、条件を以下のように設定すると以下のようにInfluxDBのデータを見ることができます。
Dockerホストサーバーをセットアップ(2台)
監視対象の2台のサーバーです。DockerとcAdvisorを入れます。
Dockerをインストール
$ sudo yum install -y docker
$ sudo systemctl start docker
$ sudo systemctl enable docker
cAdvisorをDockerコンテナとして起動。
$ sudo docker run \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--publish=8080:8080 \
--detach=true \
--privileged\
--name=cadvisor_with_influxdb \
google/cadvisor:latest \
--log_dir=/ \
--storage_driver=influxdb \
--storage_driver_host=<InfluxDBサーバーのIP>:8086\
--storage_driver_user=root \
--storage_driver_password=root \
--storage_driver_secure=False
cAdvisorの動作確認。http://<cAdvisorサーバーのIP>:8080にアクセス。2台とも確認。
適当にDockerコンテナを立ち上げる。
$ sudo docker run --name redis -d redis
$ sudo docker run --name nginx -d -p 50080:80 dockerfile/nginx
InfluxDBで確認
InfluxDBのダッシュボードでInfluxDBに入っていることを確認します。
list seriesでseries名を確認します。
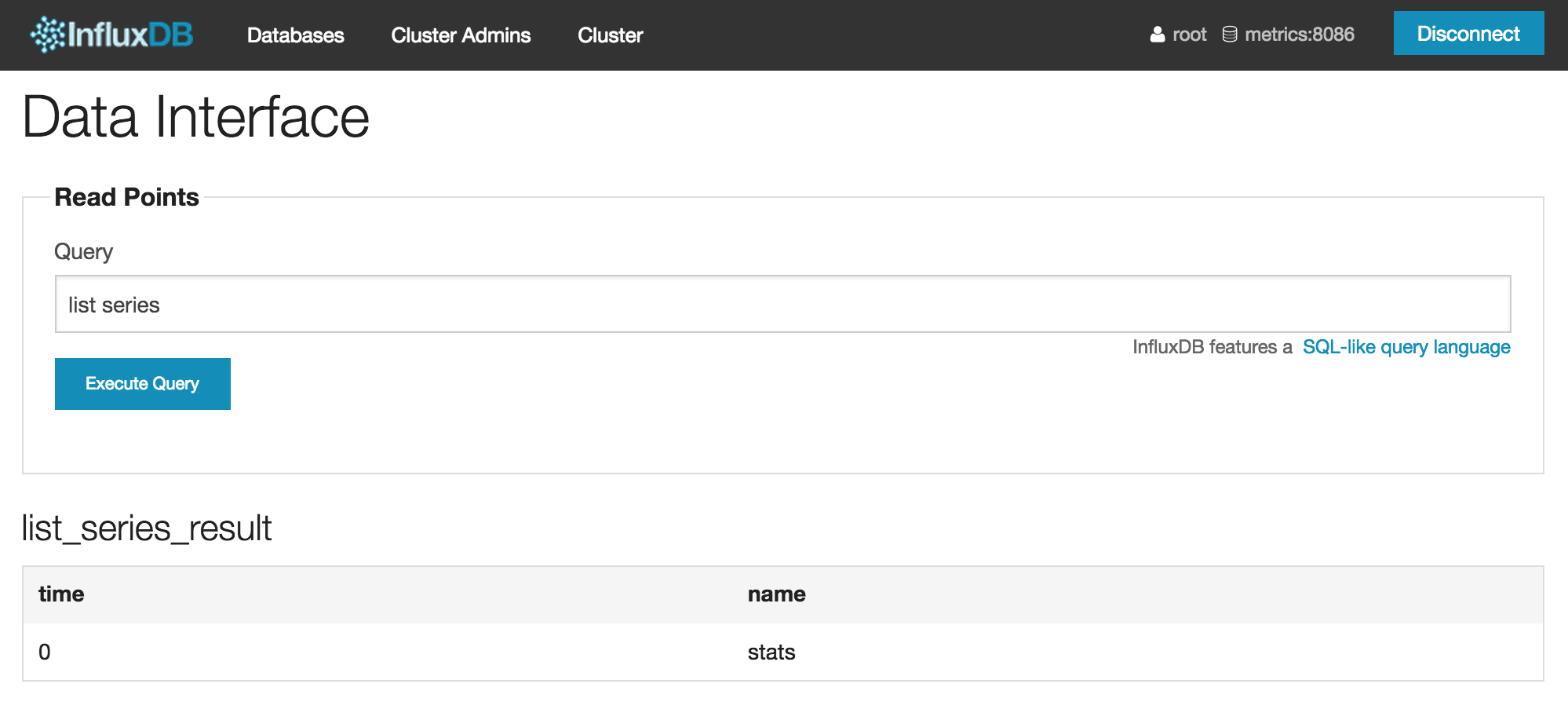
statsというseriesがあることがわかったので、select * from stats limit 10と中身を確認します。
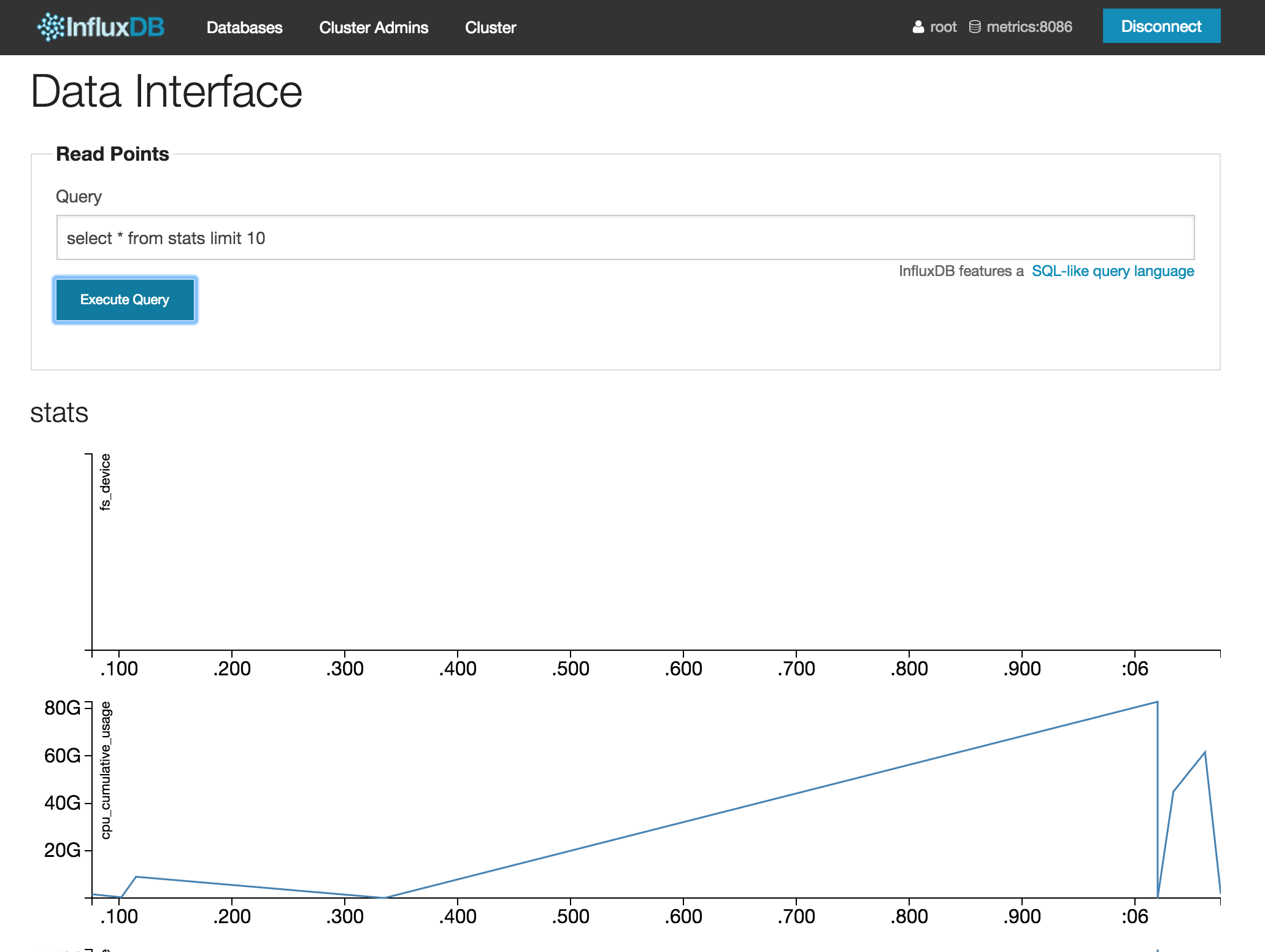
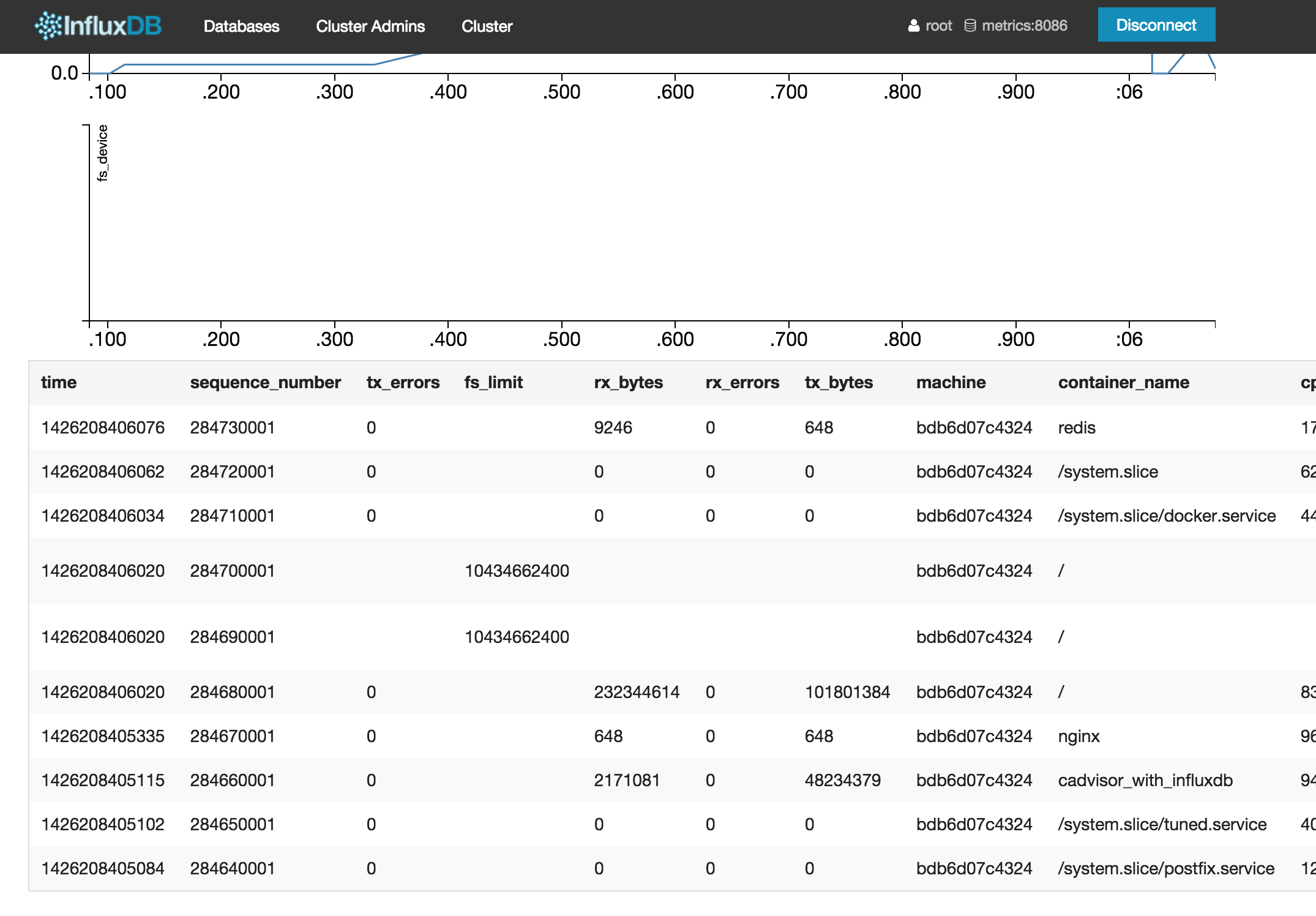
stats seriesに入っているデータは以下のカラムで構成されています。
| カラム | 説明 |
|---|---|
| time | UNIX時間(ミリ秒) |
| sequence_number | シーケンス番号(InfluxDBによる自動採番) |
| machine | マシンID(/etc/machine-id, /var/lib/dbus/machine-id 起動時に設定も可能) |
| container_name | コンテナ名 |
| memory_working_set | ワーキングセットメモリサイズ(バイト) |
| memory_usage | メモリ使用量(バイト) |
| cpu_cumulative_usage | 累計CPU使用時間(ナノ秒) |
| fs_device | デバイス名 |
| fs_usage | ディスク使用量(バイト) |
| fs_limit | ディスクサイズ(バイト) |
| rx_bytes | ネットワークの受信バイト数 |
| rx_errors | ネットワークの受信エラー数 |
| tx_bytes | ネットワークの送信バイト数 |
| tx_errors | ネットワークの送信エラー数 |
参考
- https://github.com/google/cadvisor/blob/master/info/v1/container.go
- https://github.com/google/cadvisor/blob/master/storage/influxdb/influxdb.go
Grafanaで確認
ちょこちょこと設定するとこんな風に表示できます。
HeapsterのGrafanaのダッシュボード設定のサンプル(heapster/grafana/kubernetes-dashboard.json)を真似ると楽です。
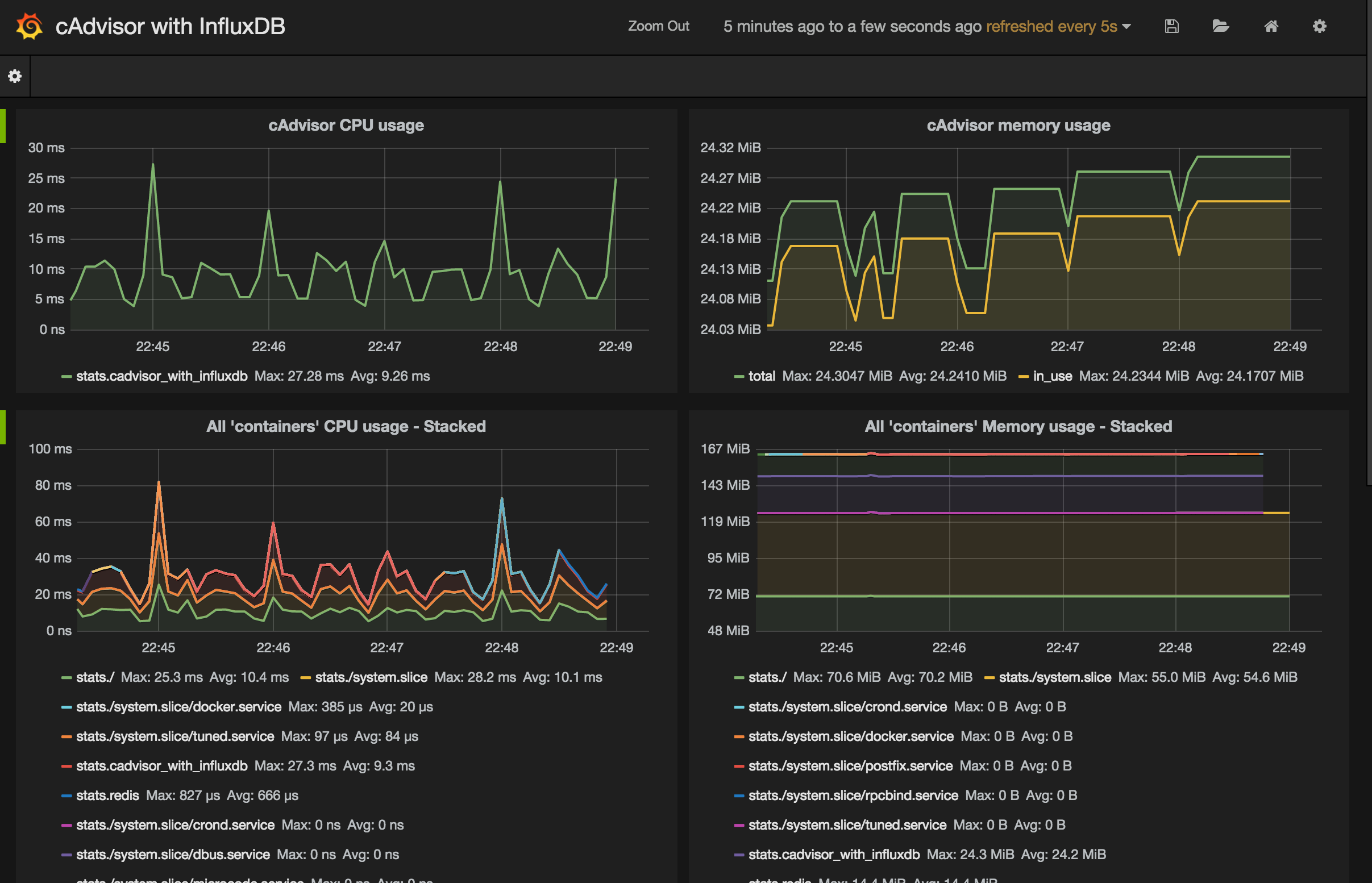
なかなかきれいに表示できました。
左上のグラフは以下の設定です。cadvisor_with_influxdbというコンテナのCPU使用率を表しています。
derivative関数は単位時間あたりの値の変化量つまり変化率を求めます。
select container_name, derivative(cpu_cumulative_usage) from "stats" where $timeFilter and machine = 'c563336a339b' and container_name = 'cadvisor_with_influxdb' group by time($interval) order asc
右上のグラフは以下の設定です。cadvisor_with_influxdbというコンテナのメモリ使用量を表しています。
select mean(memory_usage) from "stats" where $timeFilter and machine = 'c563336a339b' and container_name = 'cadvisor_with_influxdb' group by time($interval) order asc
select mean(memory_working_set) from "stats" where $timeFilter and machine = 'c563336a339b' and container_name = 'cadvisor_with_influxdb' group by time($interval) order asc
下の2つのグラフのように全コンテナのグラフを一度に表示する場合は、where句からcontainer_nameの条件を外し、group byでcontainer_nameを指定します。
終わりに
cAdvisor, InfluxDB, Grafanaを使うと簡単に複数台のDockerホスト上のコンテナの監視ができました。
ただ、cAdvisor APIで取れる全てのデータが入るわけではないとか、メタデータ的なものを追加できないとかちょっとデフォルトじゃ不満足な場合はfluentで入れるのがいいのかなあと思います。こんなfluentプラグイン(Woorank/fluent-plugin-cadvisor)もあるようですし。