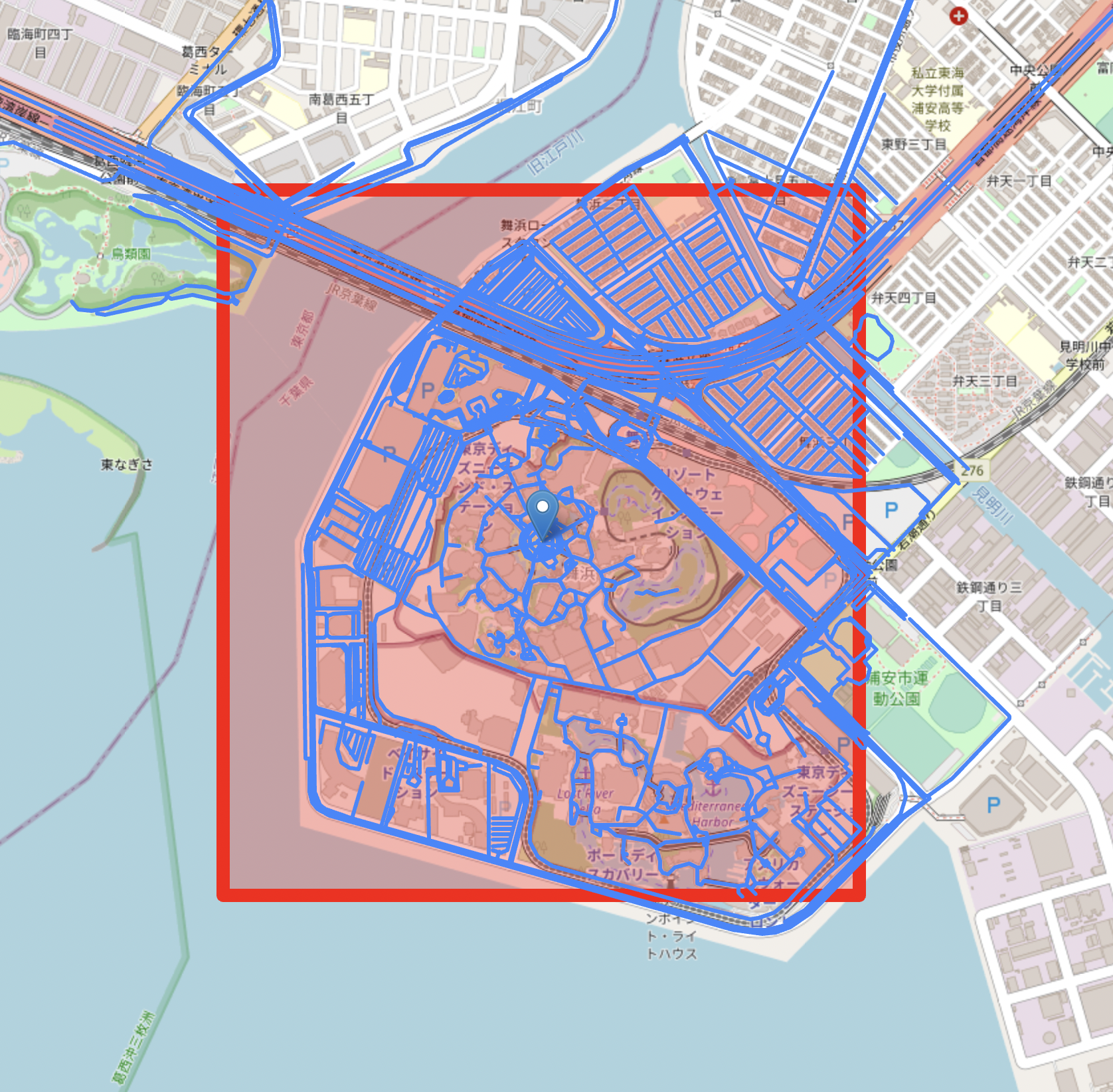
超高速な近傍道路探索の実行例
ディズニーランドを中心とした1辺が1kmの長方形に含まれる道路を抽出👉 クエリ実行時間0.01秒
道路の座標データは要らず,インデックスのみでいい場合👉 クエリ実行時間0.00008秒
はじめに
本記事では,空間インデックスなどに使用されるR-Treeの亜種で,最悪実行時間を保証した Priority R-Tree1(PR-Tree)を,Pythonから近傍道路探索の用途に使ってみます。
ライブラリは C++とPybind11で実装された python-prtree を用います。x86_64であれば,ビルド済みwheelがpypiに登録されているので以下でインストール可能です。M1 Mac等の場合は,cmakeとpybind11を事前にインストールする必要があります(ローカルでビルドが走るため)。また,R-Treeのライブラリであるrtreeも比較用にインストールします。
# {{ if aarch64 }}
pip install cmake pybind11
# {{ endif }}
pip install python-prtree tree
道路NWデータの準備
https://qiita.com/kkdd/items/1c39f87fe34c2fb406f3 を参考にOpenStreetMapから道路データのみを抽出します(リンク先では高速のみにフィルターされているためそれを外す)。抽出したファイル名を japan-way.osm.bf とします。
そして,https://qiita.com/kkdd/items/a900d2dd60e3215a1138 を参考に作成した以下のコードで道路NWデータだけを1つのdictにまとめてpickleで保存します。手元ではdata.pklは3GB程度になりましたので,ディスク・メモリ容量には気をつけてください2。
import osmium
import pickle
import copy
from tqdm import tqdm
ONEWAY = 1
BIDIRECTIONAL = 0
def wayDirection(oneway):
if oneway in [None, "no", "false", "0", "reversible"]:
return BIDIRECTIONAL
if oneway in ["reverse", "-1"]:
return -ONEWAY
else:
return ONEWAY
class DataHandler(osmium.SimpleHandler):
def __init__(self):
super().__init__()
self.d = {}
self.d["nodes"] = {}
self.d["ways"] = {ONEWAY: {}, BIDIRECTIONAL: {}}
self.pbar = tqdm()
def update(self):
self.pbar.update(1)
def node(self, n):
self.d["nodes"][n.id] = (n.location.lon, n.location.lat)
self.update()
def way(self, w):
nodes = [n.ref for n in w.nodes]
oneway = wayDirection(w.tags.get("oneway"))
if oneway == -ONEWAY:
oneway = ONEWAY
nodes = nodes[::-1]
self.d["ways"][oneway][w.id] = {
"nodes": nodes,
"tags": {k: v for k, v in w.tags},
}
self.update()
if __name__ == "__main__":
h = DataHandler()
h.apply_file("japan-way.osm.pbf", locations=False)
with open("data.pkl", "wb") as f:
pickle.dump(h.d, f)
data.pklは,以下のような構造になります。
{
"nodes": {
node_id: (lon, lat),
...,
},
"ways": {
ONEWAY: {
way_id: {
"nodes": [1, 2, 3, ...],
"tags": {key1: value1, ...}
},
},
BIDIRECTIONAL: ...
}
R-Tree/PR-Treeの構築と比較
せっかくなので,C++で実装されたlibspatialindexのPython Wrapperであるrtreeライブラリとの構築時間の比較・速度比較を行ってみたいと思います。なお,rtreeもbuildのwheelが手に入るので,Pythonだけで完結します。
Bounding Boxの作成
まずは各ライブラリに突っ込むデータを用意するために,抽出した道路NWデータから各道路(way_idごと)にBounding Box(BB)を作成していきます。BBは,(x_min, y_min, x_max, y_max)から決まる4点を頂点とする長方形です。
import pickle
import numpy as np
from tqdm import tqdm
with open("data.pkl", "rb") as f:
d = pickle.load(f)
nodes = dict()
for k, v in tqdm(d["nodes"].items()):
nodes[k] = np.array(list(v), dtype=np.float64)
nodes_boxes = np.array(list(nodes.values()), dtype=np.float64)
ways = dict()
tmp = d["ways"][0] | d["ways"][1]
for k, v in tqdm(tmp.items()):
try:
minima = np.stack([nodes[n] for n in v["nodes"]]).min(axis=0)
maxima = np.stack([nodes[n] for n in v["nodes"]]).max(axis=0)
bb = np.hstack([minima, maxima])
ways[k] = bb
except:
continue
idxes = np.array(list(ways.keys()), dtype=np.int64)
boxes = np.array(list(ways.values()), dtype=np.float64)
R-Tree/PR-Treeの構築
構築にかかった時間は,rtreeの場合は1時間程度,python-prtreeの一括構築の場合は20分程度でした。時間の都合上逐次挿入のpython-prtreeの実行時間はありませんが,小データではrtreeよりも高速に動作することは確認できました。
R-Tree
import time
import rtree
p = rtree.index.Property()
p.dat_extension = 'data'
p.idx_extension = 'index'
s = time.time()
file_idx = rtree.index.Index('rtree', properties=p)
for j, (i, v) in tqdm(enumerate(ways.items()), total=len(ways)):
datum = {
"nodes": tuple(tmp[i]["nodes"]),
"polylines": tuple([tuple(nodes[n]) for n in tmp[i]["nodes"]]),
"mbr": tuple(v.ravel()),
"tags": tmp[i]["tags"],
}
# 逐次に挿入して構築していく
file_idx.insert(i, boxes[j], obj=datum)
print(time.time() - s)
PR-Tree(一括で構築)
import time
from python_prtree import PRTree2D
s = time.time()
# ここで一気に構築する
prtree = PRTree2D(idxes, boxes)
for i, v in tqdm(ways.items()):
datum = {
"nodes": tuple(tmp[i]["nodes"]),
"polylines": tuple([tuple(nodes[n]) for n in tmp[i]["nodes"]]),
"mbr": tuple(v.ravel()),
"tags": tmp[i]["tags"],
}
# python objectの設定は後で
prtree.set_obj(i, datum)
prtree.save("prtree.bin")
print(time.time() - s)
PR-Tree(逐次で構築)
推奨はされないですが,R-Tree likeな逐次構築も可能です。なお,rebuild3 すると最悪計算時間の保証がされます。
import time
from python_prtree import PRTree2D
s = time.time()
prtree = PRTree2D()
for j, (i, v) in tqdm(enumerate(ways.items()), total=len(ways)):
datum = {
"nodes": tuple(tmp[i]["nodes"]),
"polylines": tuple([tuple(nodes[n]) for n in tmp[i]["nodes"]]),
"mbr": tuple(v.ravel()),
"tags": tmp[i]["tags"],
}
# 逐次に挿入して構築していく
prtree.insert(i, boxes[j], obj=datum)
# 最悪計算時間保障のため構築し直す
prtree.rebuild()
prtree.save("prtree.bin")
print(time.time() - s)
近傍の道路を探索
検索速度を検証するために,ディズニーランドを中心とした1辺が1kmの長方形に含まれる道路を全て列挙して,foliumを使って可視化してみたいと思います。得られる結果はrtree/python-prtreeを用いた場合も同一で,以下のようになりました。
また,気になるクエリの実行時間ですが,rtreeの場合は0.03秒程度・python-prtreeの場合は0.01秒程度でした。
さらに,今回は使用していないですが,python-prtreeにはbatch_queryというメソッドがあり,数十万のクエリでもC++の中で並列に実行してくれて一括で結果を返してもらえるので便利そうです。
R-Tree
import numpy as np
import rtree
import folium
import time
p = rtree.index.Property()
p.dat_extension = 'data'
p.idx_extension = 'index'
file_idx = rtree.index.Index('rtree', properties = p)
lat, lng = (35.6329, 139.8804)
dx = (1./3600/27) # 1m
dy = (1./3600/30) # 1m
k = 1000 # m
rect = (lng - k * dx, lat - k * dy, lng + k * dx, lat + k * dy)
s = time.time()
for _ in range(10):
res = list(file_idx.intersection(rect, objects=True))
res = [r.object for r in res]
print(time.time() - s)
m = folium.Map(location=[lat, lng], zoom_start=14)
folium.Marker([lat, lng], popup="here").add_to(m)
locations = [
(rect[1], rect[0]),
(rect[3], rect[0]),
(rect[3], rect[2]),
(rect[1], rect[2]),
]
folium.Polygon(
locations=locations,
color="red",
weight=10,
fill=True,
fill_opacity=0.3,
).add_to(m)
for r in res:
locations = [x[::-1] for x in r["polylines"]]
popup = r["tags"]
folium.PolyLine(locations=locations, popup=popup).add_to(m)
m.save("rtree.html")
PR-Tree
import numpy as np
from python_prtree import PRTree2D
import folium
import time
prtree = PRTree2D("prtree.bin")
print(prtree.n)
lat, lng = (35.6329, 139.8804)
dx = (1./3600/27) # 1m
dy = (1./3600/30) # 1m
k = 1000 # m
rect = (lng - k * dx, lat - k * dy, lng + k * dx, lat + k * dy)
s = time.time()
for _ in range(10):
res = prtree.query(rect, return_obj=True)
print(time.time() - s)
m = folium.Map(location=[lat, lng], zoom_start=14)
folium.Marker([lat, lng], popup="here").add_to(m)
locations = [
(rect[1], rect[0]),
(rect[3], rect[0]),
(rect[3], rect[2]),
(rect[1], rect[2]),
]
folium.Polygon(
locations=locations,
color="red",
weight=10,
fill=True,
fill_opacity=0.3,
).add_to(m)
for r in res:
locations = [x[::-1] for x in r["polylines"]]
popup = r["tags"]
folium.PolyLine(locations=locations, popup=popup).add_to(m)
m.save("prtree.html")
まとめ
R-Treeの亜種で最悪実行時間を保証した Priority R-Tree(PR-Tree)のライブラリであるpython-prtreeを使って,道路NWからR-Tree/PR-Treeの近傍道路探索を行ってみました(on M1 MacBook)。その結果,PR-Treeのライブラリであるpython-prtreeは,R-Treeのライブラリであるrtreeよりも構築・検索ともに3倍ほど高速に動作しました。
また,batch_queryというrtreeにはないメソッドもpython-prtreeにはあり,多くのクエリを投げる際にはさらに高速に動作しそうです。さらに,python-prtreeは,構築やバッチクエリの処理にマルチスレッド対応しているため,本検証で使用した4+4コアのM1よりも多くのコアがあるCPUを利用する際には更なる高速化が望めます。
最後になりますが,python-prtreeに関する改善要望等ありましたら,https://github.com/atksh/python_prtree/issues/new からissueを立てていただければ可能な範囲で対応しますので,ご意見/ご要望をお待ちしています。