ネットワークインタフェースのトラフィックデータ等の累積カウンタ値を、よしなに処理してからInfluxDBに入れる方法です。
元データの確認
ここでは Telegraf の SNMP プラグインを用いて、ネットワークインタフェースのトラフィックデータを取得したものを元データとします。
なお、Telegraf の SNMP 部分の設定は以下のようにしています。
[[inputs.snmp]]
agents = [ "127.0.0.1:161" ]
interval = "10s"
timeout = "5s"
retries = 3
version = 2
community = "public"
max_repetitions = 10
tags = ["ifName"]
fielddrop = ["ifName"]
[[inputs.snmp.field]]
name = "hostname"
oid = "RFC1213-MIB::sysName.0"
is_tag = true
[[inputs.snmp.table]]
name = "interface"
inherit_tags = [ "hostname" ]
oid = "IF-MIB::ifXTable"
[[inputs.snmp.table.field]]
name = "ifName"
oid = "IF-MIB::ifName"
is_tag = true
[[inputs.snmp.table.field]]
name = "ifDescr"
oid = "IF-MIB::ifDescr"
is_tag = true
これにより、SNMP でデータ取得し、別途設定した InfluxDB に送ります。ここでは raw という Retention Policy を事前に設定しておき、そこに生データを保存しています。
保存されたデータは以下のようなクエリにより確認できます。
> SELECT ifHCInOctets FROM raw.interface WHERE time > now() - 30s GROUP BY *
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=eth0, ifName=eth0
time ifHCInOctets
---- ------------
1516858951000000000 3599114638
1516858962000000000 3599133428
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=eth1, ifName=eth1
time ifHCInOctets
---- ------------
1516858951000000000 1041168347
1516858962000000000 1041173076
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=lo, ifName=lo
time ifHCInOctets
---- ------------
1516858951000000000 154361066
1516858962000000000 154370681
実際にはこの他にも多くのデータがありますが、説明の都合上、インタフェースの受信トラフィックのカウンタ値(ifHCInOctets)のみとしています。
累積値カウンタから Byte/sec を算出する (Continuous Query 編)
Continuous Query とは InfluxDB 上で定期的にクエリを実行し、結果を再度 InfluxDB に書き込む機能です。これにより、前述の累積カウンタ値から Byte/sec を算出して InfluxDB に保存します。
まずは Byte/sec を算出するクエリを考えます。
> SELECT DERIVATIVE(MEAN("ifHCInOctets"), 1s) FROM raw.interface WHERE time > now() - 30s GROUP BY time(10s), *
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=eth0, ifName=eth0
time derivative
---- ----------
1516858960000000000 1879
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=eth1, ifName=eth1
time derivative
---- ----------
1516858960000000000 472.9
name: interface
tags: agent_host=127.0.0.1, host=telegraf, hostname=telegraf, ifDescr=lo, ifName=lo
time derivative
---- ----------
1516858960000000000 961.5
ここで用いられている derivative 関数は、前の値との差分を取り、さらに指定した時間あたりの値を算出します。上記のクエリでは10秒毎の平均値を使っているのでデータの間隔は10秒、指定した単位時間が1秒なので、差分を10で割るといった処理になります。
このクエリを用いて、以下のように Continuous Query を作成します。
CREATE CONTINUOUS QUERY interface_10s_avg ON telegraf
RESAMPLE EVERY 10s FOR 30s
BEGIN
SELECT derivative(mean(ifHCInOctets), 1s) AS ifHCInOctets INTO telegraf."10s_avg_cq".interface FROM telegraf.raw.interface GROUP BY time(10s), *
END
RESAMPLE EVERY 10s FOR 30s の部分は、10秒毎に過去30秒間のデータに対してクエリを実行することを示します。クエリ本体には WHERE句による時間の指定がありませんが、Continuous Query では自動補完されて実行されることになります。また、クエリ本体のINTO句により、クエリの結果を10s_avg_cqという Retention Policy に保存します。
累積値カウンタから Byte/sec を算出する (Kapacitor 編)
Kapacitor は InfluxDB と同じく TICK スタックの中の一つであり、ストリームデータを受信し、処理を行ったものを InfluxDB に書き込むという使い方ができます。
ストリームデータについては、Telegraf で InfluxDB にデータを送るのと全く同様に Kapacitor ホストの9092ポート(既定値)を指定することで、送ることができます。その際、実際にはデータは保存されませんが、保存先のデータベース、Retention Policy、measurement についても同様に指定します。
このストリームデータを処理するために、下記のようなスクリプトを用意します。
# cat derivative.tick
stream
// ストリームデータの指定
| from()
.database('telegraf')
.retentionPolicy('raw')
.measurement('interface')
.groupBy(*)
// データに対する処理
| derivative('ifHCInOctets')
.as('ifHCInOctets')
.unit(1s)
// InfluxDB へ出力
| influxDBOut()
.cluster('localhost')
.database('telegraf')
.retentionPolicy('10s_avg_kap')
.measurement('interface')
ストリームデータの指定の部分では、Telegraf で指定したデータベース、Retention policy、measurement を指定します。
データに対する処理では、先ほどの InfluxDB でのクエリと同じく、delivative 関数を使用します。
InfluxDB への出力の部分は、受信部分と同様ですが、出力先のホストについても指定します。Retention Policy は 10s_avg_kapとしています。
これを、下記のようにしてタスクとして登録し、実行します。
$ kapacitor define interface_10s_avg -type stream -tick derivative.tick
$ kapacitor enable interface_10s_avg
これにより、Telegraf から受け取ったデータを処理し、InfluxDB に保存することができます。
処理されたデータの確認
以上により InfluxDB に保存されたデータを Grafana を通して確認してみると、以下のようなグラフとなります。Continuous Query で処理された値は cq、Kapacitor で処理されたデータは kapというラベルで表示しています。
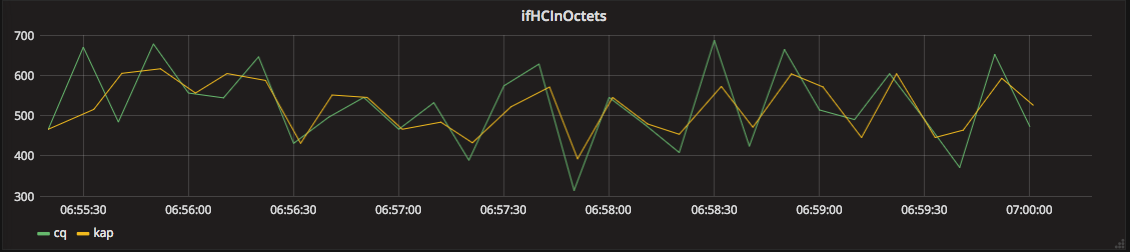
値は近いものの、完全に一致しておらず、タイムスタンプについても若干ずれています。これは Continuous Query では仕様上 group by time(10s)といった指定が必要なため、タイムスタンプの値が丸められたことによるものです。