1. モチベーション
- 週1回くらいお店を調べてご飯を食べにいくのだが、食べログで高評価なお店だともちろんご飯は美味しいのだが、予約を取るのが困難、2時間制になっていてせわしないなどの欠点も。
- しかし、オープンしたてのお店だと口コミの評価が高くても食べログの評価はそこまで高くなく狙い目なのではないかという仮説がたった。おそらく新店舗で口コミが少ない段階でお店の関係者数名がポジティブな口コミを書いて点数を高く見せるなどの方法を使えないようにするためと推察される。これ自体はもちろん食べログの評価の信頼性を担保する上では重要な施作である。
- オープンしたてのお店は情報も少なく玉石混交であろうが、どれも食べログの点数は低めと考えられただただ検索するだけではあまり引っかかってこない。その中から口コミの情報を元にいいお店を探し出し、予約もスムース、料理にも満足、2時間制も気にすることなくゆっくり、なんならお店もリピーターを作りたいから接客も丁寧、みたいなのは理想的である。(もちろん人気店には人気店のよさがあるのだが。)
- ベンジャミン・グレアム以来ウォーレン・バフェットへと続くバリュー投資は今でも投資の王道のひとつである。彼らに倣って食べログの評価は低いもののポテンシャルの高いレストランを探し出し、人気店になるまでの期間コスパの高い食事・サービスにありつこうというのが今回のモチベーションである。
2. 食べログについて
- まずはじめにはっきりさせておきたいのですが、私は数年来お店を探すにあたって食べログを利用しており、そのサービスに非常に感謝しています。この記事についても食べログさんに喧嘩を売るつもりは一切なく、問題があればすぐに削除するのでお知らせください。
- スクレイピングで情報を取得するにあたってまずは利用規約を確認する。(http://user-help.tabelog.com/rules/)
2019年12月現在スクレイピング禁止という文言は見当たらない。今回特に気にするべきと思われるのは6.(1)にある営利目的利用の禁止と口コミの無断転載の禁止であろう。もとより個人の趣味の範囲で利用するつもりであるし、以降口コミ内容を表示させることのないよう注意する。 - 点数とランキングについてその算出ロジックも簡単に公開されている。(https://tabelog.com/help/score/)
これがなかなか興味深い。今回関係ありそうなのは以下の2つ。
1:ユーザー影響度を加味している。(食べ歩き経験が豊富なユーザーの影響を大きくする)
2:評価が集まらないと点数があがらない。
やはりオープンしたてのお店はその実力よりundervalueのまま放置されている様子である。
3. スクレイピング エリアとURL取得編
個々のお店のURLを見ると、東京の場合、"//tabelog.com/tokyo/A..../A....../......../"という形になっている。
例えば渋谷のお店の場合、URLは"//tabelog.com/tokyo/A1303/A130301/......../"となっており、「食べログ/東京/渋谷・恵比寿・代官山/渋谷/具体的なお店/」というように解釈できる。
食べログのトップページを見ると、「エリアから探す」というところに"//tabelog.com/tokyo/A..../"までのデータがあり、まずはこれを取得することにする。さすがに全国全てのデータはいらないため、ある程度大きなエリアを絞った上で、欲しいデータだけを取りにいく。
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import time
root_url = 'https://tabelog.com/'
res = requests.get(root_url)
soup = BeautifulSoup(res.content, 'html.parser')
こんな感じでBeautifulSoupを使ってパースしてやり、中を見てみると、
<h2 class="rsttop-heading1 rsttop-search__title">
エリアから探す
</h2>
</div>
<ul class="rsttop-area-search__list">
<li class="rsttop-area-search__item">
<a class="rsttop-area-search__target js-area-swicher-target" data-swicher-area-list='[{"areaName":"銀座・新橋・有楽町","url":"/tokyo/A1301/"},{"areaName":"東京・日本橋","url":"/tokyo/A1302/"},{"areaName":"渋谷・恵比寿・代官山","url":"/tokyo/A1303/"},...
↑この辺に欲しいデータが!!
a = soup.find_all('a', class_='rsttop-area-search__target js-area-swicher-target')
a[0].get('data-swicher-area-list')
てな感じでやると
'[{"areaName":"銀座・新橋・有楽町","url":"/tokyo/A1301/"},{"areaName":"東京・日本橋","url":"/tokyo/A1302/"},{"areaName":"渋谷・恵比寿・代官山","url":"/tokyo/A1303/"},...
という具合だ。しかし、いい感じにディクショナリのリストになっているかと思いきや、完全に文字列という。。。ということでなんとかする方法調べてみたものの見つからなかったので以下ダサいけど強引に必要な形に直す。
もしここのプロセスをスムースに処理する方法ご存知の方いたら教えてください!
splitted = a[0].get('data-swicher-area-list').split('"')
area_dict = {}
for i in range(int((len(splitted)-1)/8)):
area_dict[splitted[i*8+3]] = splitted[i*8+7]
これでなんとか以下のようなディクショナリになった。
{'上野・浅草・日暮里': '/tokyo/A1311/',
'両国・錦糸町・小岩': '/tokyo/A1312/',
'中野~西荻窪': '/tokyo/A1319/',...
正直東京だけでもいいのだが、一応網羅的に取ってくるとすれば以下の通り。
area_url = {}
for area in a:
area_dict = {}
splitted = area.get('data-swicher-area-list').split('"')
for i in range(int((len(splitted)-1)/8)):
area_dict[splitted[i*8+3]] = splitted[i*8+7]
area_url[area.get('data-swicher-city').split('"')[3]] = area_dict
なお、途中で気になったのが、len(a)=53に対してlen(area_url)=47であった。調べてみると東京・神奈川・愛知・大阪・京都・福岡が2回出てくるのが原因だったが、欲しい部分に関しては内容は同じだったので、上のコードで目的は達成できていると判断した。
以下のような形でURLを取得できている。
area_url
│
├──'東京'
│ ├──'上野・浅草・日暮里' : '/tokyo/A1311/'
│ ├──'両国・錦糸町・小岩' : '/tokyo/A1312/'
│ ⋮
│ └──'銀座・新橋・有楽町' : '/tokyo/A1301/'
│
├──'神奈川'
│ ├──'小田原周辺' : '/kanagawa/A1409/'
│ ⋮
⋮
エリアの大分類が取得できたところで、次は小分類の取得である。
大分類の取得と同じ要領で、
url = '/tokyo/A1304/'
res = requests.get(root_url + url[1:])
soup = BeautifulSoup(res.content, 'html.parser')
a = soup.find_all('a', class_='c-link-arrow')
area_dict = {}
for area in a:
href = area['href']
if href[-21:-8]!=url:
continue
else:
area_dict[area.text] = href
としてやると、
{'代々木': 'https://tabelog.com/tokyo/A1304/A130403/',
'大久保・新大久保': 'https://tabelog.com/tokyo/A1304/A130404/',
'新宿': 'https://tabelog.com/tokyo/A1304/A130401/',
'新宿御苑': 'https://tabelog.com/tokyo/A1304/A130402/'}
いい感じになる。
なお、if文を入れたのは、soup.find_all('a', class_='c-link-arrow')をした時に広告でもclass="c-link-arrow"となっているものがあり、これらを排除するためである。
次に自分が行きたいエリアを指定してそのエリアのURLを取得する。
visit_areas = ['六本木・麻布・広尾', '原宿・表参道・青山', '四ツ谷・市ヶ谷・飯田橋', '新宿・代々木・大久保',
'東京・日本橋', '渋谷・恵比寿・代官山', '目黒・白金・五反田', '赤坂・永田町・溜池', '銀座・新橋・有楽町']
url_dict = {}
for visit_area in visit_areas:
url = area_url['東京'][visit_area]
time.sleep(1)
res = requests.get(root_url + url[1:])
soup = BeautifulSoup(res.content, 'html.parser')
a = soup.find_all('a', class_='c-link-arrow')
for area in a:
href = area['href']
if href[-21:-8]!=url:
continue
else:
url_dict[area.text] = href
以下のような形で34エリアのURLを取得することに成功した!
{'丸の内・大手町': 'https://tabelog.com/tokyo/A1302/A130201/',
'九段下': 'https://tabelog.com/tokyo/A1309/A130906/',...
4. スクレイピング 個別のレストランURL取得編
エリアを指すURL("//tabelog.com/tokyo/A..../A....../")が取得できたところで、次はこれに続く個別のレストランのURL取得("//tabelog.com/tokyo/A..../A....../......../")である。
url = 'https://tabelog.com/tokyo/A1302/A130201/'
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
上記urlでこのエリアにあるお店の最初の20店舗が表示される。
なお、次の20店舗のURLは”//tabelog.com/tokyo/A1302/A130201/rstLst/2/”となっており、rstLst/3,4,5,...と指定していけば良いことがわかる。
ここでループ処理をするためにはrstLstの最大値が必要なので以下のように全レストラン数を20で割った値を整数に切り上げる。
import math
count = soup.find_all('span', class_='list-condition__count')
print(math.ceil(int(count[0].text)/20))
90
全部で1,784件のお店があり、1ページに20件であれば最後のページは90ページ目になるということである。
しかし、90ページ目を表示しようとしたところ、、、
このページを表示することができません
食べログをご利用いただきありがとうございます。
60ページ以降は表示できません。
条件を絞り込んで再度検索して下さい。
との表示が!!
とりあえず60ページまでしか表示しないとのことである。
ということで、エリア以上に条件を絞って店の件数が1,200件以下になるようにした上でループ処理を回すか、あるいはニューオープン順の上位1,200件を取得して満足するかなどを悩まないといけないことに。
ということで一旦各エリアごとに何件のお店が掲載されているのかを確認する。
counts = {}
for key,value in url_dict.items():
time.sleep(1)
res = requests.get(value)
soup = BeautifulSoup(res.content, 'html.parser')
counts[key] = int(soup.find_all('span', class_='list-condition__count')[0].text)
print(sorted(counts.items(), key=lambda x:x[1], reverse=True)[:15])
[('新宿', 5756),
('渋谷', 3420),
('新橋・汐留', 2898),
('銀座', 2858),
('六本木・乃木坂・西麻布', 2402),
('丸の内・大手町', 1784),
('飯田橋・神楽坂', 1689),
('恵比寿', 1584),
('日本橋・京橋', 1555),
('赤坂', 1464),
('人形町・小伝馬町', 1434),
('五反田・高輪台', 937),
('有楽町・日比谷', 773),
('溜池山王・霞ヶ関', 756),
('茅場町・八丁堀', 744)]
ということで11のエリアで掲載数が1,200件を超えている状況が明らかになった。
どうしようかといろいろ試行錯誤した結果、今回の目的に照らし合わせてジャンルをレストランに限定した上で、ニューオープン順の上位1,200件のデータを取得するので満足することにした。
とりあえず特定のページに表示されているレストラン情報を取得する。
url = 'https://tabelog.com/tokyo/A1301/A130101/rstLst/RC/1/?Srt=D&SrtT=nod'
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
rc_list = []
for rc_div in soup.find_all('div', class_='list-rst__wrap js-open-new-window'):
rc_name = rc_div.find('a', class_='list-rst__rst-name-target cpy-rst-name').text
rc_url = rc_div.find('a', class_='list-rst__rst-name-target cpy-rst-name')['href']
rc_score = rc_div.find('span', class_='c-rating__val c-rating__val--strong list-rst__rating-val')
if rc_score is None:
rc_score = -1.
else:
rc_score = float(rc_score.text)
rc_review_num = rc_div.find('em', class_='list-rst__rvw-count-num cpy-review-count').text
rc_list.append([rc_name, rc_url, rc_score, rc_review_num])
いくつか解説を加えておく。
まず、最初のurlであるが、'/rstLst/RC'でジャンルをレストランに限定している。その後にくる'/1'は1ページ目、すなわち最初の20件を意味している。さらに、'/?Srt=D&SrtT=nod'はニューオープン順の指定である。
for文のところで20件のレストランデータを順番に処理している。
注意が必要なのは食べログのスコアである。上記findメソッドでスコアを取得できるのだが、スコアがない場合このタグ自体が存在しない。そこでif文の is None で場合分けをし、スコアがない場合は一旦スコアを-1とする処理を付け加えた。
なお、レビュー件数についてはレビューがない場合' - 'が返ってくる。
あとはエリアごと、ページごとにループを回してやればレストランのURL取得ができる!!
5. スクレイピング 口コミと評価取得編
以上までで個別のレストランのURLを取得できるようになったので、ここからは個別のレストランのページから口コミ情報を取得することが目的となる。
先にコードを載せてしまうと、以下のようなことをした。
url = 'https://tabelog.com/tokyo/A1301/A130101/13079232/dtlrvwlst/COND-2/smp0/?smp=0&lc=2&rvw_part=all&PG=1'
res = requests.get(url)
soup = BeautifulSoup(res.content, 'html.parser')
station = soup.find_all('dl', class_='rdheader-subinfo__item')[0].find('span', class_='linktree__parent-target-text').text
genre = '/'.join([genre_.text for genre_ in soup.find_all('dl', class_='rdheader-subinfo__item')[1].find_all('span', class_='linktree__parent-target-text')])
price = soup.find_all('dl', class_='rdheader-subinfo__item')[2].find('p', class_='rdheader-budget__icon rdheader-budget__icon--dinner').find('a', class_='rdheader-budget__price-target').text
score = [score_.next_sibling.next_sibling.text for score_ in soup.find_all('span', class_='c-rating__time c-rating__time--dinner')]
print(station, genre, price, score)
解説を加えていく。
まずurlであるが、’/dtlrvwlst’は口コミ一覧、'/COND-2'は夜の口コミ、'smp0'は簡易表示、’lc=2’は100件ずつ表示、'PG=1'は1ページ目を意味している。
最寄駅、ジャンル、予算はクラス名が'rdheader-subinfo__item'という'dl'タグ内にデータがあるため順に取得してきている。ジャンルについては1つの店に複数のジャンルが割り振られていることが大半なので、ここでは一旦'/'で全てのジャンル名を結合した。
予算とそれぞれの口コミの点数は夜のものだけが欲しかったため、少し面倒な表記になっている。
6. 実行!!
個々に必要な情報が取れるようになったのであとはループ処理で欲しいデータを取得するだけ!!
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
import math
import time
from tqdm import tqdm
root_url = 'https://tabelog.com/'
res = requests.get(root_url)
soup = BeautifulSoup(res.content, 'html.parser')
a = soup.find_all('a', class_='rsttop-area-search__target js-area-swicher-target')
area_url = {}
for area in a:
area_dict = {}
splitted = area.get('data-swicher-area-list').split('"')
for i in range(int((len(splitted)-1)/8)):
area_dict[splitted[i*8+3]] = splitted[i*8+7]
area_url[area.get('data-swicher-city').split('"')[3]] = area_dict
visit_areas = ['渋谷・恵比寿・代官山']
url_dict = {}
for visit_area in visit_areas:
url = area_url['東京'][visit_area]
time.sleep(1)
res = requests.get(root_url + url[1:])
soup = BeautifulSoup(res.content, 'html.parser')
a = soup.find_all('a', class_='c-link-arrow')
for area in a:
href = area['href']
if href[-21:-8]!=url:
continue
else:
url_dict[area.text] = href
max_page = 20
restaurant_data = []
for area, url in url_dict.items():
time.sleep(1)
res_area = requests.get(url)
soup_area = BeautifulSoup(res_area.content, 'html.parser')
rc_count = int(soup_area.find_all('span', class_='list-condition__count')[0].text)
print('There are ' + str(rc_count) + ' restaurants in ' + area)
for i in tqdm(range(1,min(math.ceil(rc_count/20)+1,max_page+1,61))):
url_rc = url + 'rstLst/RC/' + str(i) + '/?Srt=D&SrtT=nod'
res_rc = requests.get(url_rc)
soup_rc = BeautifulSoup(res_rc.content, 'html.parser')
for rc_div in soup_rc.find_all('div', class_='list-rst__wrap js-open-new-window'):
rc_name = rc_div.find('a', class_='list-rst__rst-name-target cpy-rst-name').text
rc_url = rc_div.find('a', class_='list-rst__rst-name-target cpy-rst-name')['href']
rc_score = rc_div.find('span', class_='c-rating__val c-rating__val--strong list-rst__rating-val')
if rc_score is None:
rc_score = -1.
else:
rc_score = float(rc_score.text)
rc_review_num = rc_div.find('em', class_='list-rst__rvw-count-num cpy-review-count').text
if rc_review_num != ' - ':
for page in range(1,math.ceil(int(rc_review_num)/100)+1):
rc_url_pg = rc_url + 'dtlrvwlst/COND-2/smp0/?smp=0&lc=2&rvw_part=all&PG=' + str(page)
time.sleep(1)
res_pg = requests.get(rc_url_pg)
soup_pg = BeautifulSoup(res_pg.content, 'html.parser')
if 'お探しのページが見つかりません' in soup_pg.find('title').text:
continue
try:
station = soup_pg.find_all('dl', class_='rdheader-subinfo__item')[0].find('span', class_='linktree__parent-target-text').text
except:
try:
station = soup_pg.find_all('dl', class_='rdheader-subinfo__item')[0].find('dd', class_='rdheader-subinfo__item-text').text.replace('\n','').replace(' ','')
except:
station = ''
genre = '/'.join([genre_.text for genre_ in soup_pg.find_all('dl', class_='rdheader-subinfo__item')[1].find_all('span', class_='linktree__parent-target-text')])
price = soup_pg.find_all('dl', class_='rdheader-subinfo__item')[2].find('p', class_='rdheader-budget__icon rdheader-budget__icon--dinner').find('a', class_='rdheader-budget__price-target').text
score = [score_.next_sibling.next_sibling.text for score_ in soup_pg.find_all('span', class_='c-rating__time c-rating__time--dinner')]
restaurant_data.append([area, rc_count, rc_name, rc_url, rc_score, rc_review_num, station, genre, price, score])
データ量が多いのでここでは一旦エリアをvisit_areas = ['渋谷・恵比寿・代官山']に限定した。また、max_page = 20としたため、1つの場所ごとに20件/page✖️20(max_page)の400件のデータのみが取得できる形となる。
また、レビューの数を取得したのちそれを100件/ページずつ取得していっているが、はじめに取得するレビューの数は昼の評価も含めたものであり、ループ処理は夜の評価のみを対象としているため、ループ処理の過程で当初想定していたほどレビューが存在していないという事態が発生したため、
if 'お探しのページが見つかりません' in soup_pg.find('title').text:
continue
で処理をした。
また、ほとんどのお店は最寄駅を記載しているが、最寄駅の代わりにエリアを記載しているお店がわずかに存在し、この場合タグの名前が異なるため、
try:
station = soup_pg.find_all('dl', class_='rdheader-subinfo__item')[0].find('span', class_='linktree__parent-target-text').text
except:
try:
station = soup_pg.find_all('dl', class_='rdheader-subinfo__item')[0].find('dd', class_='rdheader-subinfo__item-text').text.replace('\n','').replace(' ','')
except:
station = ''
でこれを処理している。
結果895件のデータを得ることができた。このうち1つでも点数のついた口コミがあったのが804件。
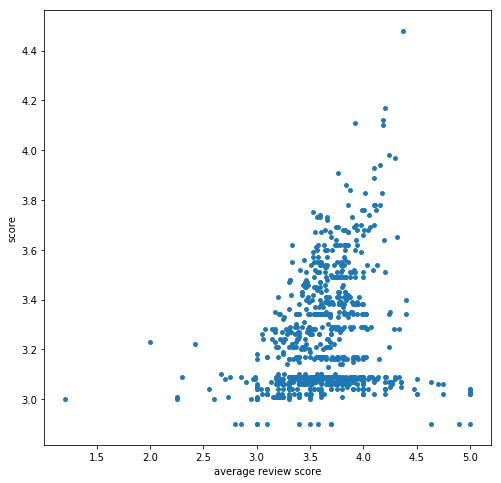
口コミ評価の平均と食べログの点数との関係を表したのが上の散布図。
食べログの点数がないお店は2.9点として処理している。
全体として口コミ評価の平均が高くなれば食べログの点数も高くなっている様子がわかる他、
口コミ評価の平均が高いのに食べログの点数は低く、過小評価されているお店が存在していることもわかった。
ということで、今度この過小評価されているお店のどれかに行ってみようと思います!!