はじめに
この記事はQualiArts Advent Calendar 2020の19日目の記事になります。
本稿は筆者が安心して夜も寝られなかったオレオレデータ加工パイプラインを、Dataformに乗り換えることで幸せになろうとする記事です。まだ完全には乗り換えられていないですが、個人的にはDataformこそが求めていたサービスだったので急いで検証して、乗り換えるコツなどを共有することでなるべく自分のような不幸な人を生み出したくないという背景があります。
Dataformとは
Dataformは、データウェアに格納されているデータを加工するパイプラインを構築するためのサービスです。もともとはそんなにメジャーではなかったと思うのですが、それが突如脚光を浴びたのはGoogle Cloudが12/8に買収を発表したからです。ただ買収しただけであればここまで注目されることもなかったと思うのですが、なんと買収発表と同時に完全無料化したため衝撃が走りました。Google様ありがとうございます。(ちなみにもともとは月額$150〜450のサービスだったようです)
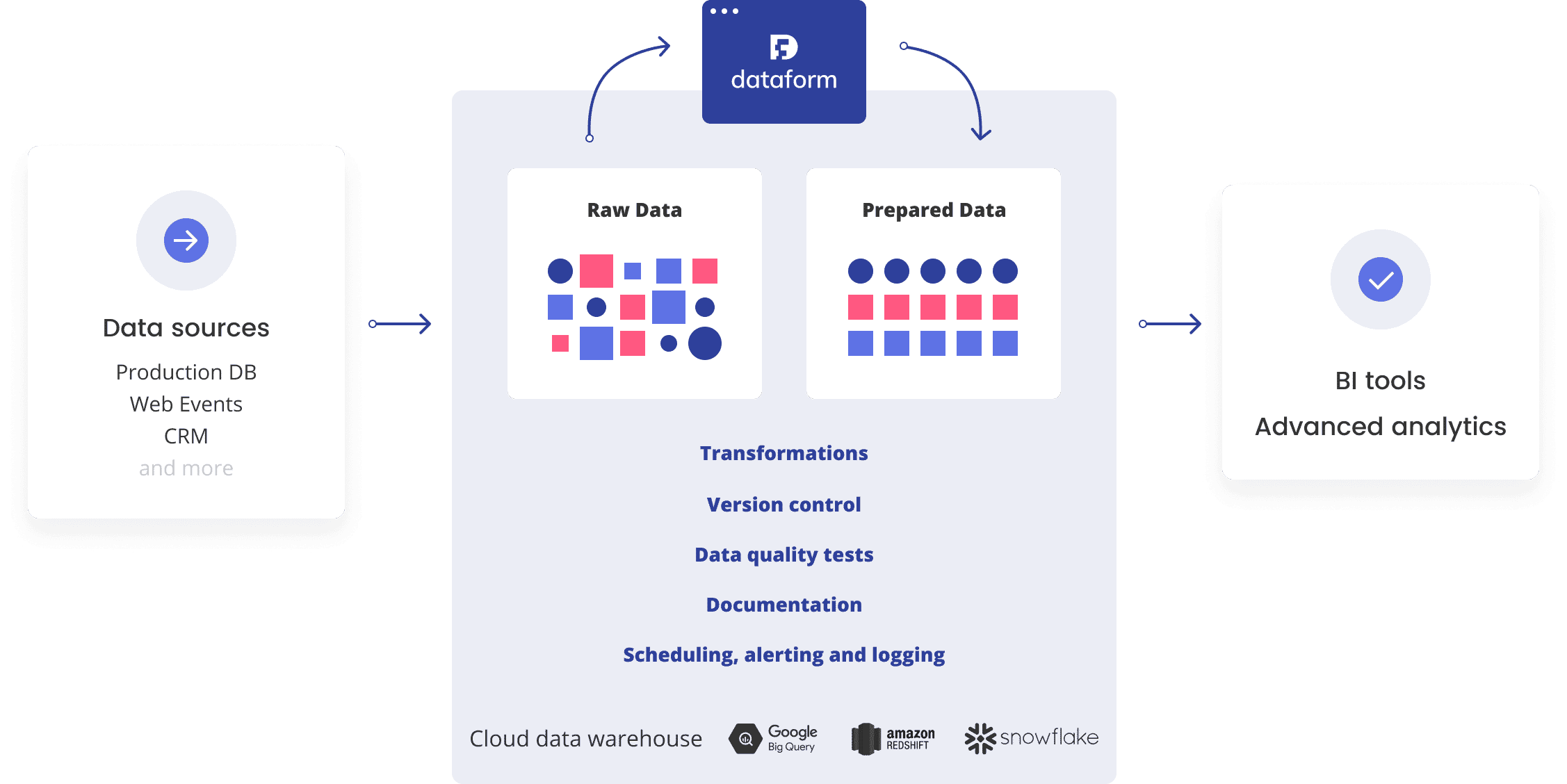
出典: https://docs.dataform.co/introduction
Dataform自体は元Googleのエンジニアが立ち上げたスタートアップだったようで、それをGoogleが買収するという構図に何とも言えない気持ちになりました。
対応データウェアハウス
BigQuery以外にもクラウド含めた主要なデータウェアハウスに対応しています。
- Google BigQuery
- Amazon Redshift
- Snowflake
- Azure SQL Data Warehouse
- Postgres
ただしGoogleが買収したことから察せるように、今後はBigQuery連携の開発に注力するということで、今からBigQuery以外の人が飛びつくのは少し危ないかもしれませんが、Dataform自体はOSSでDocker Hubでイメージも配信されているので、絶対に避けたほうがいいわけでもないかもしれませんが。
特徴
- SQLXという独自に拡張したSQLでテーブル固有の情報+クエリを一体で管理する
- テストデータを定義してクエリのテストを記述可能
- テーブル間の依存関係を自動解決
- ウェブIDE
- 依存関係の可視化
- ジョブの実行
- 定期実行
- メール/Slack通知あり
- 実行ログの確認
- Git管理
- GitHub連携
- CI/CD対応
- GitHub Actionsでのrun/test
- 環境管理:開発環境と本番環境を定義してデータの分離が可能
ということで、まさにこれぞ自分が求めていたものです。完璧で何も言うことありません。
オススメする人
次のような、データウェアハウスにあるデータを加工するクエリを泣きながら管理していた人にオススメです。
- BigQueryのスケジュールクエリで何となくクエリを流して管理ができていなかった人
- 筆者のようにオレオレのデータ加工パイプラインを構築して、クエリが失敗して途中で止まるたびに泣く泣く手で直していた人
オススメしない人
Dataformはデータウェアハウスにあるデータを加工することに特化したサービスです。Dataformにデータをロードするところを含めてパイプラインを構築することは(現状は)できません。そのようなことが必要な場合は、次に紹介するGCPの他サービスを利用して全体のパイプラインを構築するか、ロード部分のみをシンプルにGCSなどからロードしてBigQueryに流し込めるような状態を作ってそこからはDataformで完結させるかのどちらかになると思います。
Google Cloudの他サービスとの比較
BigQuery標準のスケジュールクエリ
手軽さで言えば敵わないですが、クエリ1つ1つが独立した扱いになるのでとてもパイプラインは構築できないです。大規模なパイプラインを構築するときに個人的には絶対に使えないです。
Cloud Functions + Cloud Schedulerのオレオレパイプライン
筆者が構築していたのはこれでした。自由度は高く、要件も複雑ではなかったので一日一回決められた順番でクエリを流すだけでしたが、たまにコケることがありリカバリーをするのが大変でした。また管理も属人化してしまうので、もう二度と作りたくはないです・・・
Dataflow, Dataprep, Data Fusion
いずれもマネージドなパイプライン構築サービスですが、料金がお高めなのと、BigQuery上のデータをこねくりまわすだけの要件であれば機能としてリッチすぎるので選択肢としてはなかなか難しいです。
Dataformを使ってみる
では実際にDataformを使ってみるためのステップを簡単に紹介します。
まずはDataformの要であるSQLXについて説明します。
SQLXとは
Dataformが独自にSQLを拡張したものがSQLXです。ロジック(クエリ)とセットで、設定やドキュメント、テストを記述できます。
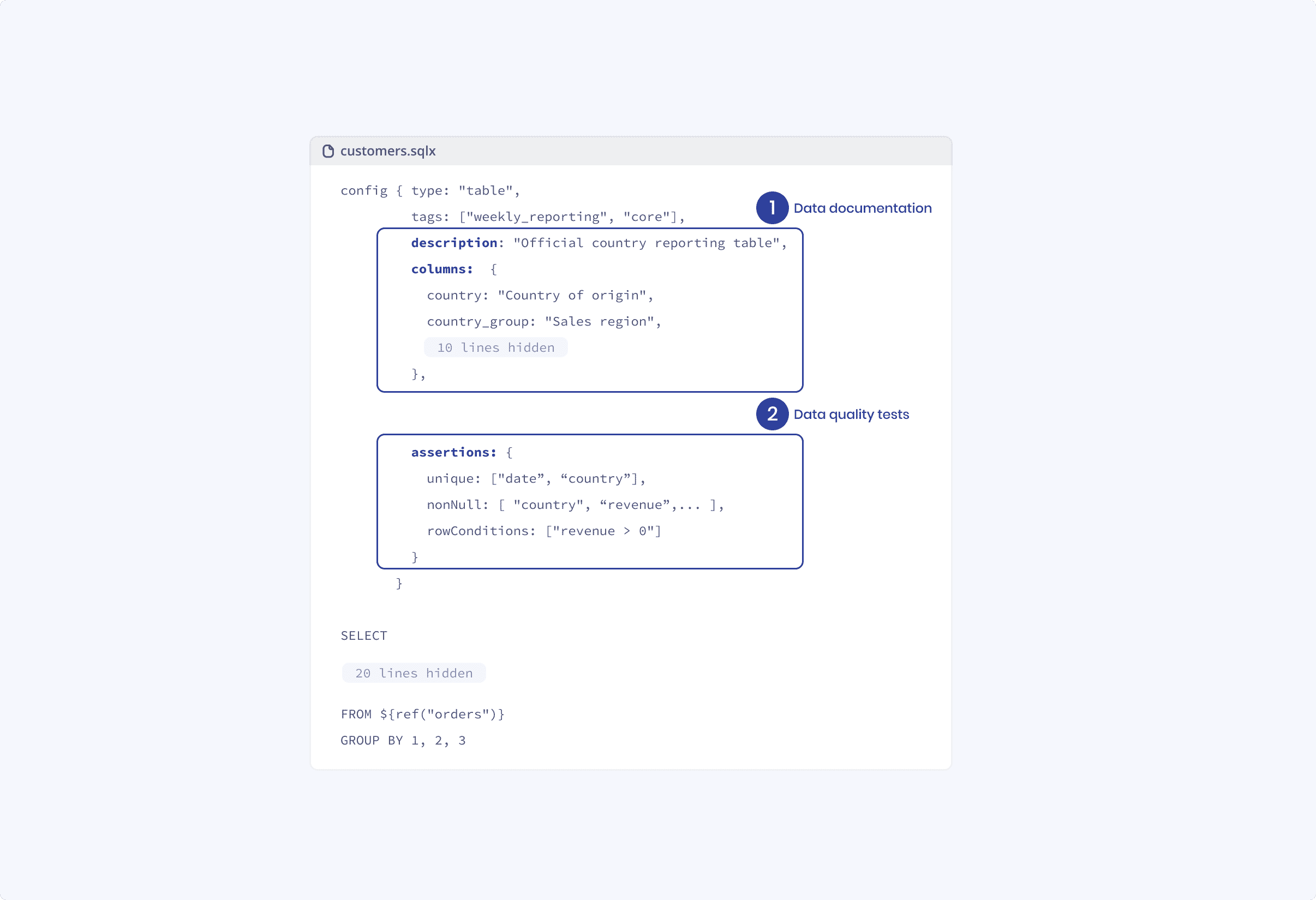
出典: https://docs.dataform.co/introduction/dataform-in-5-minutes
基本的には先頭にconfigブロックを書き、それに続いてSQLクエリを書く形です。1つのテーブルを構築するのに必要な全ての情報が1つに纏められるので、見通しが非常に良いです。
またテーブル参照関数 ${ref("")}のようなDataform独自関数が使えるので、テーブルの参照をきちんと管理でき、またインラインJavascriptも使えるため通常のSQLクエリよりもプログラマブルです。
configに書くtypeがそのSQLXの種別を表し、以下の物があります。
| type | 説明 |
|---|---|
| declaration | ソースとなるテーブル、依存関係の管理のために使用 |
| table | テーブルとして出力、常に上書き |
| incremental | テーブルとして出力、出力先があれば追加、出力先がなければテーブル作成 |
| view | ビューとして出力 |
では実際にSQLXを書いてデータパイプラインを構築していくために、まずは初期設定を行います。
初期設定 (dataform.json)
プロジェクト作ったら、まずは初期設定としてdataform.jsonを書きます。
{
"warehouse": "bigquery",
"defaultSchema": "dataset",
"assertionSchema": "dataform_assertions",
"defaultDatabase": "GCP Project ID"
}
汎用的な名前になっていて何を書けばいいのか分かりづらいですが、defaultDatabaseにGCPのプロジェクトIDを、defaultSchemaにデータセット名を書きます。
次に入力元となるソーステーブルを定義します。
ソーステーブルの定義
DataformはBigQuery上にあるデータを加工するため、ソースとなるテーブルを予めconfigのみのSQLXで定義します。
config {
type: "declaration",
schema: "dataset",
name: "src_table",
description: "foo"
}
typeはdeclarationになります。schemaとnameが汎用的な名前になっていて分かりづらいですが、それぞれBigQueryで言うデータセット名とテーブル名です。
いよいよDataformの真髄である、加工するクエリのSQLXを書きます。
加工するクエリを書く
declarationを参照して、データを加工するSQLXクエリを書きます。
config {
type: "table",
columns: {
time: "日時",
data: "何かしらのデータ"
},
bigquery: {
partitionBy: "time"
}
}
SELECT time, data FROM ${ref("src_table")}
WHERE time > TIMESTAMP("2000/01/01", "Asia/Tokyo")
Dataformはテーブルを自動的に作成してくれるため、columnsにカラムの説明を書きます。
BigQuery特有のオプションとしてパーティション列なども同時に定義できます。
クエリはただカラムを絞って抽出する簡単なものですが、雰囲気は伝わるかなと思います。
簡単な例ではありますが、これだけでデータ加工のパイプラインが定義できました。
あとはこれをスケジュール機能を使って定期的に実行するだけです。
言うは易し行うは難し、実際に運用していたクエリを移植するときにハマったポイントがあったので、次にそれを紹介します。
Dataformに移行する際にハマった罠
よくあるBigQueryの日次バッチクエリをDataformに移行する際に、Dataform特有の感覚を理解していないと詰まりやすいポイントがあるので、それらを事前に知っておくことでスムーズに移行できるようになります。
実行日を基準としたクエリはダメ
BigQueryのスケジュールクエリで使える@run_dateや、独自スクリプトのようにクエリで実行日などを変数として入力していると、実行日の前日のデータだけSELECTして集計すればいいため、クエリを書くのが非常に楽です。**ところがDataformではこのような機能がないため、実行日を基準としたクエリは(素直には)書けません。**そこでDataformにクエリを移行するときには、冪等なクエリ(何回実行しても安全なクエリ)に置き換えるように工夫する必要があります。
素直に書くとこのようなイメージです。
config {
type: "incremental",
}
SELECT * FROM ${ref("src_table")}
WHERE time > (SELECT MAX(time) as max_time FROM ${self()})
出力先テーブルにある一番大きい時間を取ってきて、それより大きいデータを入力テーブルから選択する簡単なクエリです。ただしこれはフルスキャンになるダメな例なので、それの解決方法を次に紹介します。
冪等なクエリがフルスキャンになりがち
BigQueryの場合スキャン量を抑えるためにテーブルが日時などでパーティション化されていることが多いと思いますが、冪等なクエリを書くときに予め参照するパーティションが決まっていないとフルスキャンとなってしまい、膨大なコストと時間がかかってしまいます。
そこでDataformでこのようなクエリを書く場合は、BigQuery ScriptingのDECLAREを使って予め計算する範囲を絞ります。
スクリプト機能自体はわりと最近出た機能で、筆者はDataformを触るまで知りませんでした。
config {
type: "incremental",
}
pre_operations {
declare max_time default (
${when(incremental(),
`SELECT MAX(time) FROM ${self()}`,
`select timestamp("2000-01-01")`)}
)
}
SELECT * FROM ${ref("src_table")}
WHERE time > max_time
このDECLAREのテクニックは、Dataformに限らず通常のBigQueryでも使えるため、覚えておくと良さそうです。
このテクニックを含めたDataformにおけるBigQueryのtipsはぜひ読んでみて下さい。
ググっても何も出てこない
Dataform自体がメジャーになっていないためか、まだ情報が少ないためか、ググると全く関係ないデータが出てきがちです。
英語のドキュメントとGitHubにあるサンプルぐらいしかないので取っつきづらいのは確かですが、逆に言えば現時点でこれぐらいしかないので一通り読み込むことを推奨します。
サンプルにしか無い関数もあったりします
その他紹介できなかったことで試したいこと
クエリの移植に時間がかかってしまったので本当は検証したかったのですが、実際の運用に乗せるために以下のDataformの機能も検証して、運用に向けたノウハウを貯める必要があると感じています。まだふわっとしか理解していない部分が多いですが、使い勝手を試しながら現在のオレオレパイプラインを完全に移行したいと思います。
- テスト
- アサート
- テストデータの準備
- 環境定義による、開発環境と本番環境のデータセットの分離
- GitOps
- スケジュール実行
- 失敗時のリカバリー
- 複数人開発
- クエリからドメイン固有のロジックの分離(ボット判定条件など)
さいごに
Dataformは現時点でも素晴らしすぎる機能が揃っていてDXが上がること間違いなしなので、ぜひとも皆さん使ってみて下さい!
明日は @tarob19 さんの記事になります、よろしくお願いします。