はじめに
プログラミング初心者なんで、自分が理解するための記録として書いていきたいと思います。
まず、今回やるのはMNISTを使った学習です。
MNISTデータ
MNISTデータは、手書きの数字が書かれた白黒画像(28×28ピクセル)です。
学習データ(60,000枚)、テストデータ(10,000枚)のデータセットです。
データの読み込み
MNISTデータを読み込みます。
データはタプル型で代入されます。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(type(mnist.load_data()))
# class <'tuple'>
データの前処理
・入力データの形を変換
入力データを
・学習データ :60000×784
・テストデータ:10000×784
の形に変換します。
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
一枚のデータを横一列に並べて、それを縦に60,000(10,000)枚並べた感じになるのかな??
図のイメージ。実際には二次元配列になってると思うけど、、、
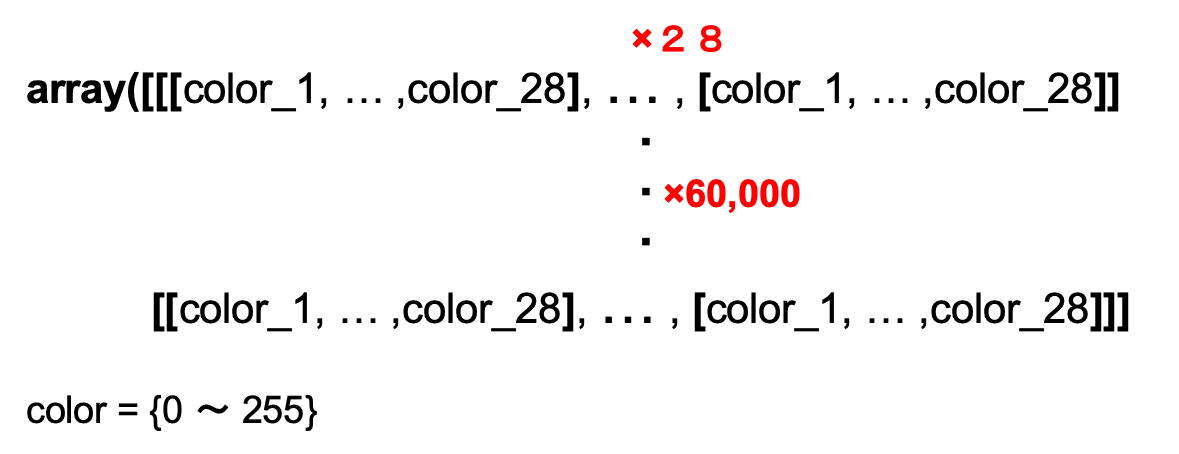
・入力データの正規化
学習精度を高めるために、入力データを0〜1の間になるように正規化を行います。
データはfloat型に変換します。
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
厳密には以下の式で正規化を行っています。
X:入力データ(0〜255)
M:正規化後の最大値1
m:正規化後の最小値0
Y = \frac{X - X_{min}}{X_{max} - X_{min}} (M - m) + m
・教師データをダミー変数に変換(one_hot_encoding)
教師データをダミー変数に変換します。
二つ目の引数に値を渡すと、0からnb_classesまでの要素で変換するらしい。
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# to_categorical(y, nb_classes = None)
# 4 = [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
モデルの構築
Sequentialモデルで学習をします。
層を追加する時は、addメソットでどんどん追加していくと見易くなります。
Denseの最初の引数はユニット数、activationは活性化関数です。
活性化関数は他にもたくさんあります。
活性化関数は各層でどのように学習して次の層に伝えるを決める結構重要なもの
なのかなって認識しています。
input_dimは隠れ層の一層目に書くもので、入力のユニット数なのかな??
ちなみに、ReLUは0以下の値だと0で、1以上だとそのままの値を出力するような関数です。
softmaxは、出力層で使われます。
使い所としては、分類で識別率を出したいときに使います。
だから、回帰とかの時には使わない認識です。
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=784))
model.add(Dense(10, activation='softmax'))
モデルの最適化
optimizerはRMSpropというものを使います。
optimizerは損失関数を最小にするような重みを算出するアルゴリズムで
その手法は他にもたくさんあります。
ですが、どの手法が優れているのかについてはしっかりとたエビデンスがまだ出ていないらしいです。
ただ、RMSpropはパラメーターが多く、最適なパラメーターを設定しないと他の手法に劣るらしい。
(ここらへんについてはもっと勉強します、、、)
lossは損失関数です。損失関数は、予測と実測値とのズレを評価します。
回帰と分類で、用いる関数が異なります。
metricsは評価関数です。損失関数と似ていて、予測値と実測値とのズレを評価します。
戻り値には、評価した値の平均を返します。
model.compile(
optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']
)
学習
ここでは、ミニバッチ学習(学習データの半分以下のバッチサイズで学習)をしていきます。
バッチサイズは1グループに対する個数のことです。つまり、バッチサイズが100なら、
600グループができるということになります。ちなみに、グループのことはバッチ数といいます。
グループを分けて学習を行うことで、一部のデータに対してのみ最適化してしまうのを
防ぐ役割をします。そのため、データの動きが激しい場合には、バッチサイズを大きく設定し、
あまり変動がないようなデータにはバッチサイズを小さくするのが望ましいようです。
損失関数の更新はバッチ数毎に行います。(多分、、、)
エポック数は学習回数です。全てのバッチ数を学習し終えると、データをシャッフルします。
この工程がエポック1となります。
model.fit(
x_train, y_train,
batch_size=100,
epochs=12,
verbose=1
)
モデルの評価
97.4%の識別率が出ました。
score = model.evaluate(x_test, y_test)
print(score[0])
print(score[1])
# output
# 0.0918885813294677
# 0.9739000201225281
終わりに
次回はデータの可視化をしたりとか色々やっていきたいと思います。