はじめに
顔には性格が現れるってよく言いますよね。
今回は、画像分類でよく使われるCNNをTensorFlowで実装して、アニメキャラの顔画像を基にキャラの性格を分類してみました。
アニメキャラクターの属性一覧表 全53種
http://tonarino-kawauso.com/wordpress/personality-types/
を参考にアニメキャラにありがちな性格をピックアップ
- ボーイッシュ
- クールビューティー
- お嬢様
- 妹
- ツンデレ
他にも色々とありますが、とりあえず今回はこの5つのクラスに分類してみます
データの収集
画像検索で地道に手作業で収集していき、全部で153件のデータを集めました。
平均すると1クラスあたり30件程度の画像データがあることになります。
全ての画像に対して、手作業で顔画像の切り出しを行い(自動的に処理しようとするとどうしても精度が低かった)
クラスごとにディレクトリを分けていきました
データの加工
集めたデータを学習用と検証用に8:2の割合で分けて
反転やコントラストをいじるなどして、それぞれ6倍に増やしました。
その結果
学習用データ:732件
検証用データ:186件
となりました
CNNの実装
cnn_anime.py
import numpy as np
import tensorflow as tf
NUM_CLASSES = 5 # 分類するクラス数
IMG_SIZE_w = 32 # 画像の1辺の長さ
IMG_SIZE_h = 32 # 画像の1辺の長さ
COLOR_CHANNELS = 3 # RGB
IMG_PIXELS = IMG_SIZE_w * IMG_SIZE_h * COLOR_CHANNELS # 画像のサイズ*RGB
sess = tf.InteractiveSession()
x = tf.placeholder(tf.float32, shape=[None, IMG_PIXELS])
y_ = tf.placeholder(tf.float32, shape=[None, NUM_CLASSES])
W = tf.Variable(tf.zeros([IMG_PIXELS,NUM_CLASSES]))
b = tf.Variable(tf.zeros([NUM_CLASSES]))
sess.run(tf.initialize_all_variables())
y = tf.nn.softmax(tf.matmul(x,W) + b)
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
W_conv1 = weight_variable([5, 5, COLOR_CHANNELS, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x, [-1, IMG_SIZE_w, IMG_SIZE_h, COLOR_CHANNELS])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([8 * 8 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 8*8*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess.run(tf.initialize_all_variables())
モデルの学習
cnn_anime.py
import random
STEPS = 50 # 学習ステップ数
BATCH_SIZE = 50 # バッチサイズ
tr_ac_list = []
te_ac_list = []
for i in range(STEPS):
print i
random_seq = range(len(train_image))
random.shuffle(random_seq)
for j in range(len(train_image)/BATCH_SIZE):
batch = BATCH_SIZE * j
train_image_batch = []
train_label_batch = []
for k in range(BATCH_SIZE):
train_image_batch.append(train_image[random_seq[batch + k]])
train_label_batch.append(train_label[random_seq[batch + k]])
train_image_batch = np.array(train_image_batch)
train_label_batch = np.array(train_label_batch)
train_step.run(feed_dict={x: train_image_batch, y_: train_label_batch, keep_prob: 0.5})
# 毎ステップ、学習データに対する正答率を表示
train_accuracy = accuracy.eval(feed_dict={
x:train_image, y_: train_label, keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
tr_ac_list.append(train_accuracy)
test_accuracy = accuracy.eval(feed_dict={
x: test_image, y_: test_label, keep_prob: 1.0})
print("test accuracy %g"% test_accuracy)
te_ac_list.append(test_accuracy)
# 精度の可視化
import matplotlib.pyplot as plt
x_axis = np.array([i for i in range(1,51)])
y_axis = np.array(tr_ac_list)
y2_axis = np.array(te_ac_list)
plt.hold(True)
plt.plot(x_axis,y_axis,label="train_data")
plt.plot(x_axis,y2_axis,label="test_data")
plt.legend()
plt.xlabel("step")
plt.ylabel("accuracy")
plt.show()
plt.savefig("result.png")
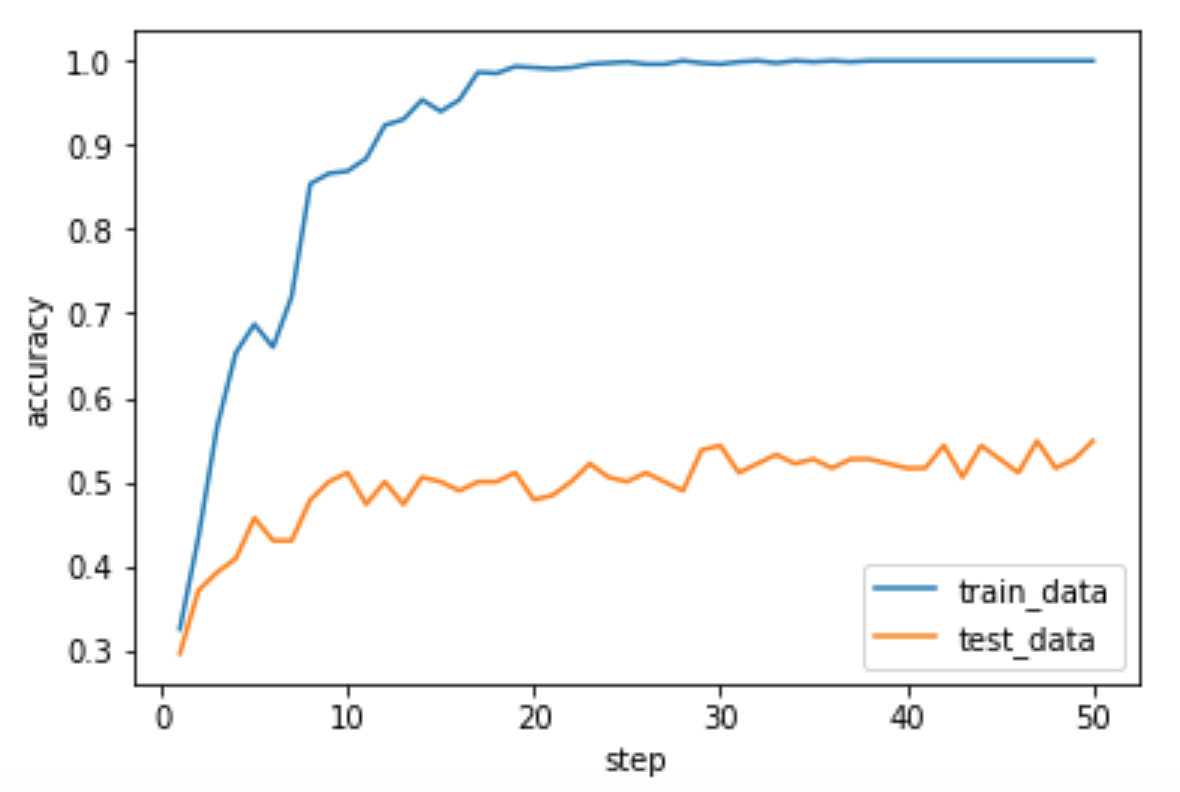
やはりデータが少ないこともあって、学習はかなり早い段階で収束してますが、検証データでの精度は5割弱といったところでしょうか。
クラスごとの精度
| クラス | 予測精度 |
|---|---|
| ボーイッシュ | 20.0% |
| クールビューティー | 26.2% |
| お嬢様 | 95.2% |
| 妹 | 60.0% |
| お嬢様 | 69.0% |
お嬢様の予測精度が異常に高いですね。
一方で、ボーイッシュはランダムで分類した時とほとんど変わらないという結果になっています。
データを見てみると、お嬢様キャラはほぼ全員、金髪ロングの縦ロールでした。そりゃ分類できるわと思いました。

一方で、ボーイッシュは髪型は似ている気がするけど、髪色はあまり似ていなかったです。

まとめ
- 全体的な精度は5割弱だが、お嬢様は高い精度で判別できる
- 髪型とか服装が判断根拠になるっぽいので、顔画像ではイマイチ判断できない
- 画像の切り出し方を変えたらいいのかも