はじめに
BigQueryでの分析ってしている人は居るような気がするが
どんな手順で行っているのかは見つからず、着手に苦労。。
自分がBigQueryを使ってGAのローデータ分析をやってきた手順・やり方についてまとめる。
※細かいSQLについては今回は触れない。
※今回扱うデータはGAのデータ。
アジェンダ
・分析の各工程
・データ抽出の進め方
・例
・まとめ
分析の各工程
おおよそ以下の工程
①分析テーマ決め / 分析対象決め
②抽出条件定義 / 対象項目決定
③データ抽出 ★
④ビジュアライズ
⑤結果共有 / ディスカッション
ー ①~⑤の繰り返し ー
⑥GOAL(最終アウトプット作成 / 施策の決定等)
一番時間をかける、かつ、BigQueryの性質も考慮した分析手順として、
データ抽出の箇所を深掘る。
データ抽出の進め方
BigQueryのポイント
①"何単位"のデータ?
取得したい項目が何単位のデータ(ユーザー・セッション・ヒット)なのか
最終的に分析・可視化したいデータが何単位なのか
を意識してデータを作成することが大切
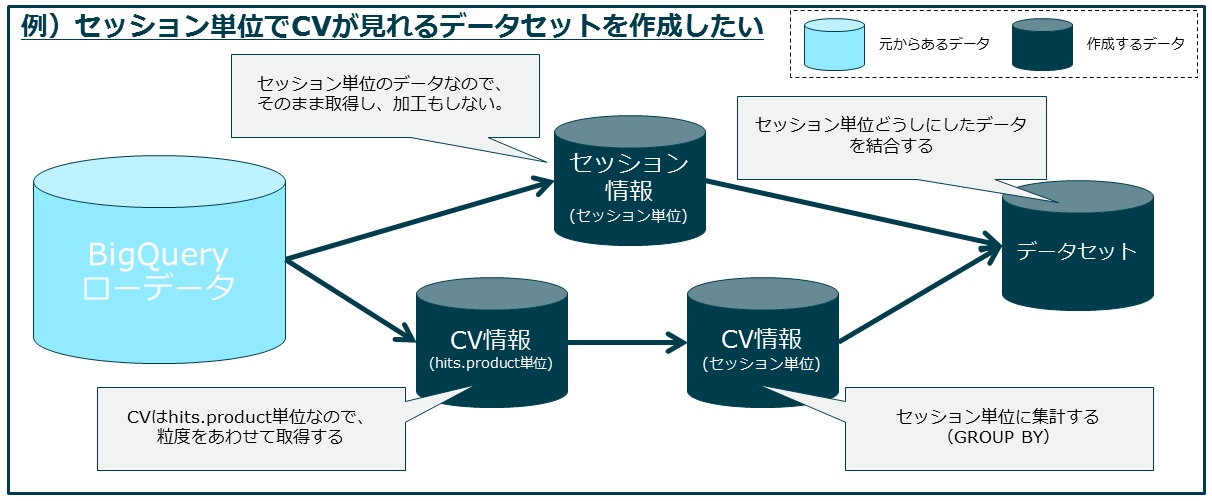
②テーブルを分けて分析を進める
分析過程がわかりやすい、データの検証がしやすい
何単位のデータか?
アクセス解析のデータには、
「ユーザー」、「セッション」、「ヒット(PV)」の概念がある。
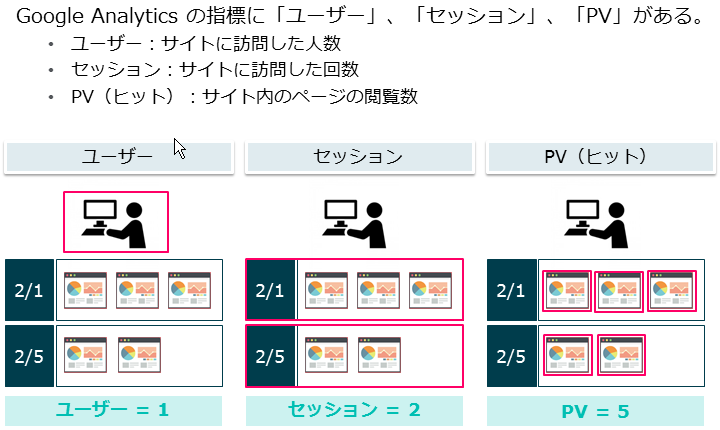
BigQueryのデータ構造は1レコード1セッション単位ですが、
中にはヒット(PV)の情報が入れ子のような形で含まれている。
そのため、セッション単位の情報・ヒット単位の情報を合わせてみたい!と言った場合、
『セッション単位の情報』と『ヒット単位の情報』を分けて取得し、
セッションの一意キーで結合してデータセットを作成していくイメージとなる。
カスタムディメンション
GAのデータは原則Googleが定義した箱の中にデータを設定していくイメージですが、
カスタムディメンションでは、個別サイトで任意の項目を設定・取得することが出来ます。
こちらもヒット・セッション毎で設定可能です。
カスタムディメンションはRECORD型のデータとなるので、取得の際には、「どのまとまりで取得するか」「最終、どのデータセットに結合しにいくか」を考慮します。
例
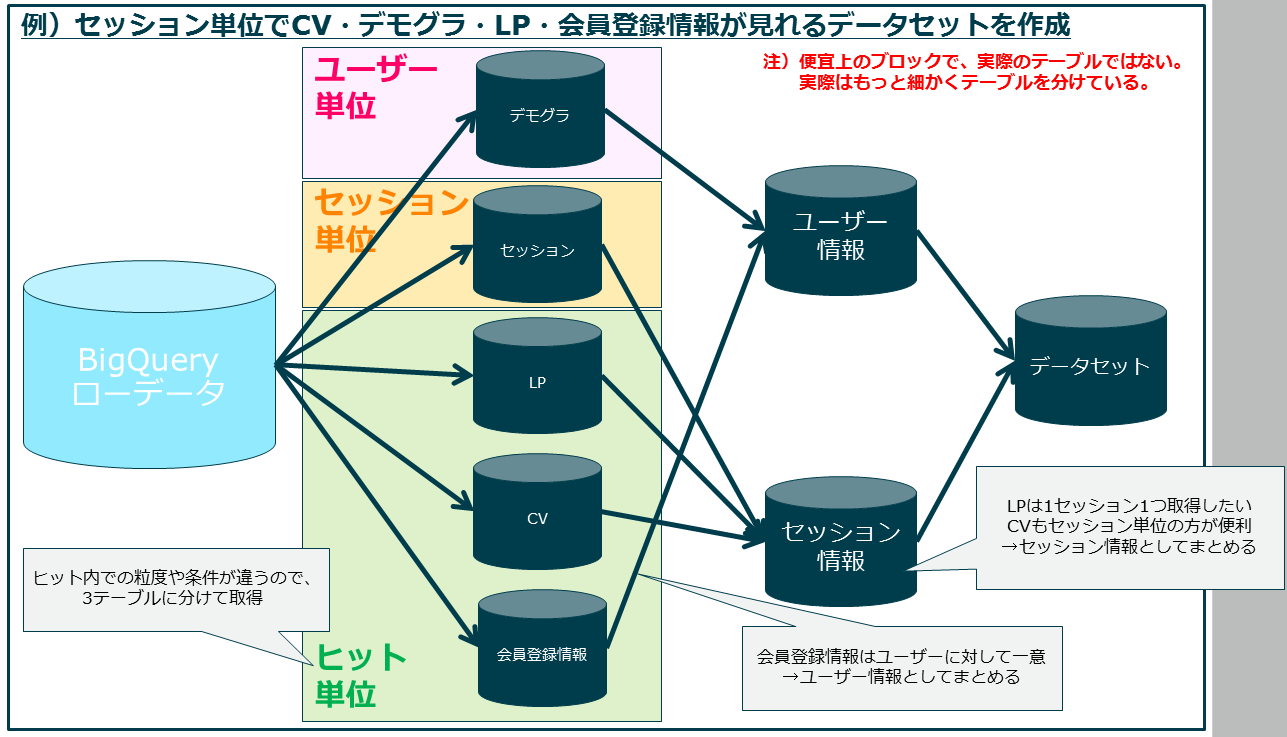
※今回使ったデータでは、デモグラ(ユーザーの属性値)をカスタムディメンションで取得している。
会員登録情報はヒットで取っている。CV/LP/セッションについてはおおよそ標準の通り。
まとめ
・何単位のデータ(ユーザー・セッション・ヒット)なのか がとても重要
・一個一個情報を確認しながら進めるのが大切
・最後にデータセットとしてまとめられる用に、どれをキーにJOINするか、頭で設計しておくべし