概要
近年、機械学習が話題となっており、その多くは画像系、コンピュータビジョン領域のものに分類される。一方で自然言語処理も機械学習が対象とするタスクであり、様々な実験がされているものの、まだ画像分野に比べると実用化できるレベルは限られている。AIで自然言語というと文章を自動に生成したり、文章の意味を理解し要約する機能を思い浮かべがちだが、この分野はまだまだ発展段階である。
今回は自然言語処理の中でも比較的容易なタスクである文章のジャンルの推測について紹介をする。
ナイーブベイズ分類器とは
別名、単純ベイズ分類器。トピックモデルで有名なLDAは教師なし学習であるが、ナイーブベイズは教師あり学習であり事前に教師データを集める必要がある点に注意する。
ナイーブベイズ分類器は、ベイズの定理を基に作られる分類器であるが、名前の通り一部条件を単純化して分類を行うという特徴がある。
ベイズの定理
ベイズの定理より以下のことが言える。
- BとAの同時確率 = B の後でAが起きる確率 × Bが起きる確率
- AとBの同時確率 = A の後でBが起きる確率 × Aが起きる確率
以上を式で表すと以下のようになり、かつ変形ができる。
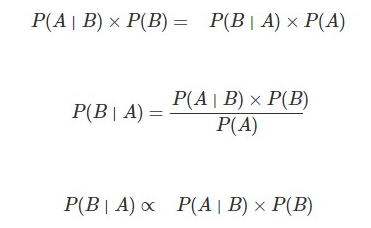
適用
これを自然言語処理的に置き換えると以下のようになる。
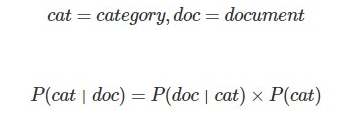
左辺P(cat|doc)はあるドキュメント(文章)があるとき、その文章があるカテゴリー(ジャンル)に属する確率であり、今回求めるべき値である。
右辺P(cat)はあるカテゴリー(ジャンル)が起こりうる確率。
例えば全体で50000単語あるうち、スポーツに関連する単語が10000単語であれば、0.2となる。
そして右辺P(doc|cat)は、ナイーブベイズの特徴の一つである独立性仮定を使用して変換する必要がある。
独立性仮定
自然言語処理ではマルコフ仮定に代表されるように、前後の関係を考慮することが一般的である。例えば、「魚」という単語があったとき、後ろに続く単語は「食べる」だったり「釣る」「買う」といった単語が一般的であり、「借りる」や「走る」といった単語は続かないと予測される。人間の場合にも、聞き取れない単語があった場合に前後の文脈から単語を推測することはよく行われる。
機械的な処理を行う場合にも前後の単語を見ることで、自然言語処理の精度向上に取り組むことは一般的だが、ナイーブベイズ分類器では単純化のため前後の文脈を無視して考える。
すなわちドキュメント(文章)を単純な単語の集まりだと考え、かつ文章の生成される確率を各単語の確立を、独立に掛け合わせたものだと考える。
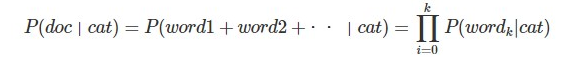
独立性仮定により、ドキュメントdocは単純にwordの集まりと考え、word1+word2・・・と変換し、これによりP(word|cat)の掛け算に落とし込む。そして以下の式を導く。
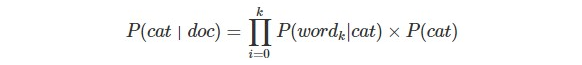
仮に過去の野球記事とサッカー記事があったとし、量の割合が野球記事4割、サッカー記事6割とする。そしてこれを学習に使用しナイーブベイズ分類器を学習させる。
次に「ゴールキーパーがボールをキャッチする」という文章が野球,サッカーどちらのジャンルに当たるか推論する。人間が見た場合、これはサッカーに関する文章だと推測できるが、ナイーブベイズで考えるときには確率計算を行う必要がある。
右辺第二項のP(cat)はカテゴリー(ジャンル)の割合で、以下のようになる。
- P(野球)=0.4
- P(サッカー)=0.6
次に右辺第一項です。特徴的な単語を考える必要があるため助詞や助動詞をなくし{ゴールキーパー,ボール,キャッチ}の3単語で考える。
教師データの野球記事の中での単語の出現頻度が
| 単語 | 確率 |
|---|---|
| ゴールキーパー | 0.0001 |
| ボール | 0.2 |
| キャッチ | 0.03 |
一方、サッカー記事の中での単語の出現頻度が
| 単語 | 確率 |
|---|---|
| ゴールキーパー | 0.01 |
| ボール | 0.2 |
| キャッチ | 0.01 |
であるものとして計算する。
ジャンルの推測結果
P(cat|doc)の計算
-
「ゴールキーパーがボールをキャッチする」が野球に分類される確率
- (0.0001x0.2x0.03)x0.4=2.4x10**-7
-
「ゴールキーパーがボールをキャッチする」がサッカーに分類される確率
- (0.01x0.2x0.01)x0.6 =1.2x10**-5
この場合,「ゴールキーパーがボールをキャッチする」はジャンル「サッカー」に分類されることになる。
テスト
今回はスポーツに関係する文章を入力した際に、以下4種類のスポーツのどれに近いかをジャンル推定する。
- サッカー
- 野球
- バレーボール
- バスケットボール
事前準備
各ジャンルの文章を事前に準備しBOW、すなわち単語群に変換しておく。なお単語群生成にはMeCabがおすすめ。
- サッカー
- "ボール バッド グローブ ストライク アウト"
- 野球
- "ボール バッド グローブ ストライク アウト"
- バレーボール
- "ボール トス レシーブ スパイク ブロック"
- バスケットボール
- "ボール レイアップ ダンク ピポッド フェイク"
モデル
ナイーブベイズでは大きく3つのモデルがある
-
gaussianNB
正規分布に従っていることを前提としたモデル。文章分類には適さない -
multinomialNB
事象の出現回数を特徴量として捉える。TFIDFと相性がいい -
bernoullNB
事象が起こったor起こってないの2値分類に適している
学習
ナイーブベイズ分類器はscikit-learnを使用することで簡単に実装が可能。
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
# BOW(string)
baseball="ボール バッド グローブ ストライク アウト"
football="ボール ボランチ オフサイド ヘディング キーパー"
volleyball="ボール トス レシーブ スパイク ブロック"
basketball="ボール レイアップ ダンク ピポッド フェイク"
keywords=[baseball,football,volleyball,basketball]
# vectorize
count_vectorizer = CountVectorizer()
feature_vectors = count_vectorizer.fit_transform(keywords)
features = count_vectorizer.get_feature_names()
print(features,len(features))
print("--------------------------------")
print(feature_vectors)
learning_labels = np.array([0,1,2,3])
# 学習
clf = MultinomialNB()
clf.fit(feature_vectors, learning_labels)
# 確認
print("--------------------------------")
print("score",clf.score(feature_vectors, learning_labels))
['アウト', 'オフサイド', 'キーパー', 'グローブ', 'ストライク', 'スパイク', 'ダンク', 'トス', 'バッド', 'ピポッド', 'フェイク', 'ブロック', 'ヘディング', 'ボランチ', 'ボール', 'レイアップ', 'レシーブ'] 17
--------------------------------
(0, 0) 1
(0, 4) 1
(0, 3) 1
(0, 8) 1
(0, 14) 1
(1, 2) 1
(1, 12) 1
(1, 1) 1
(1, 13) 1
(1, 14) 1
(2, 11) 1
(2, 5) 1
(2, 16) 1
(2, 7) 1
(2, 14) 1
(3, 10) 1
(3, 9) 1
(3, 6) 1
(3, 15) 1
(3, 14) 1
--------------------------------
score 1.0
ナイーブベイズ分類は教師あり学習であるため、各文章とその文章のジャンルを分類器に与えて覚えさせる必要がある。なおここで言う文章とは単語群であることに注意。
単語群が、何のジャンルで使われた単語群かをベクトルで表現する必要がある。
keywords=[baseball,football,volleyball,basketball]に各ジャンル毎に文章(単語群)を入力し、すべての単語を重複無しでベクトル化する。これにより、アウト→0,オフサイド→1,キーパー→3,グローブ→4と言った形で番号が割り当てられる。
またジャンルに関しては上記keywordに入力した順にbaseball=0,football=1,volleyball=2,baseball=3が割り当てられる。
各単語とその単語が所属するジャンルはこれらのベクトルを使った形で表現する。たとえば(0,3)は野球の文章に含まれる単語グローブを数値で表現したものであり、0→野球、3→グローブを表している。
推論
new_doc=["ボランチ オフサイド"]
new_vectors = count_vectorizer.transform(new_doc)
print("--------------------------------")
print(new_vectors)
print("probability",clf.predict_proba(new_vectors))
print("")
print("predict",clf.predict(new_vectors))
--------------------------------
(0, 1) 1
(0, 13) 1
probability [[0.14285714 0.57142857 0.14285714 0.14285714]]
推論時にボランチ、オフサイドの単語を含む文章を与えた時の推論結果。当然、サッカーに関する単語のため、0.57とサッカーの箇所の確率が高くなっており、推論できたと言える。